
Danny Hillis’ latest venture, Metaweb, is about to unveil its first product, the aptly named freebase, tomorrow. While freebase is still VERY alpha, with much of the basic functionality barely working, the idea is HUGE. In many ways, freebase is the bridge between the bottom up vision of Web 2.0 collective intelligence and the more structured world of the semantic web.
Early visitors to the site might be inclined to dismiss it as an early candidate for the Techcrunch deadpool. After all, is there really room for what at first glance appears to be a bastard child of wikipedia and the Open Directory Project, another site that purports to collect and organize all the world’s information in one place?
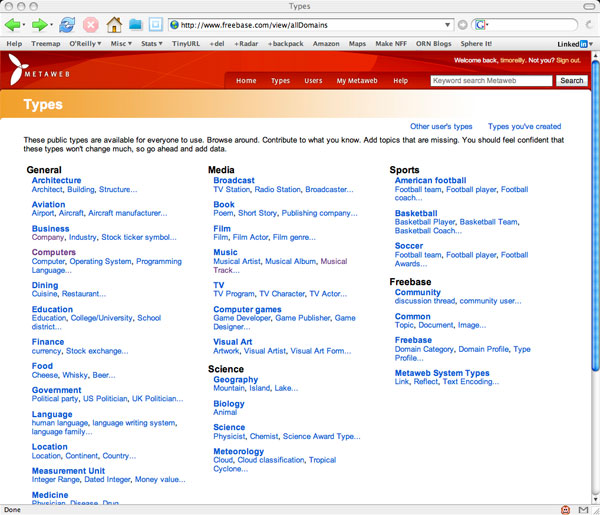
But once you understand a bit about what metaweb is doing, you realize just how remarkable it is. Metaweb has slurped in the contents of several of the web’s freely accessible databases, including much of wikipedia, and song tracks from musicbrainz. It then turns its users loose on not just adding more data items but making connections between them by filling out meta tags that categorize or otherwise connect the data items, using a typology that can be extended by users, wiki-style.
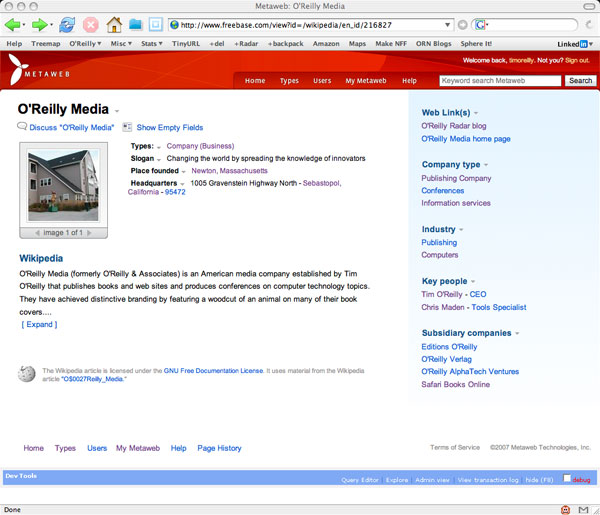
So, for example, I search for O’Reilly Media, and come to the following page:
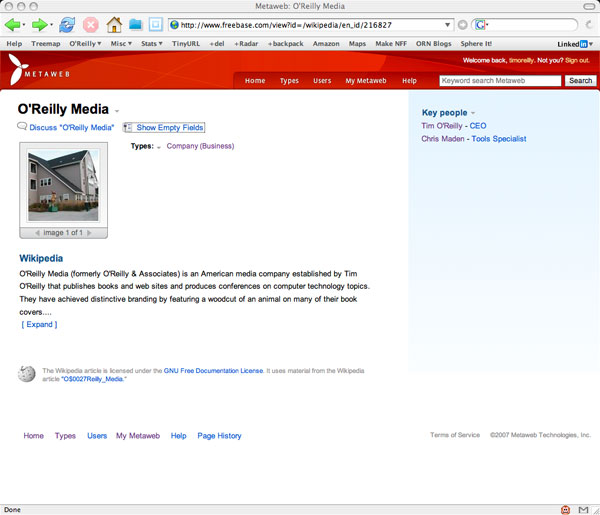
As you can see, freebase pulls in the wikipedia entry if available, and there’s a user-supplied photo of O’Reilly’s building in Sebastopol. But most importantly, O’Reilly Media is identified by its type: Company. And with that type designation comes a whole lot of structure, because Metaweb has defined a whole set of additional data that is typically associated with a company:
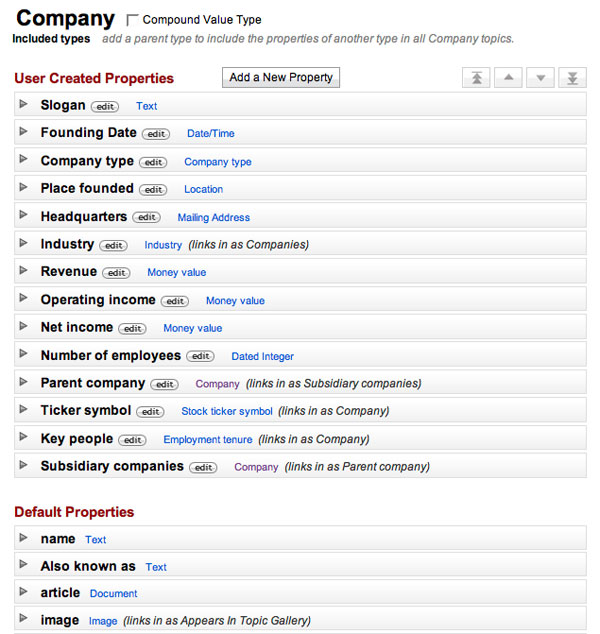
Now, when I select the link “show empty fields”, I see a new version of the entry, which prompts me to enter various structured information that I might know:
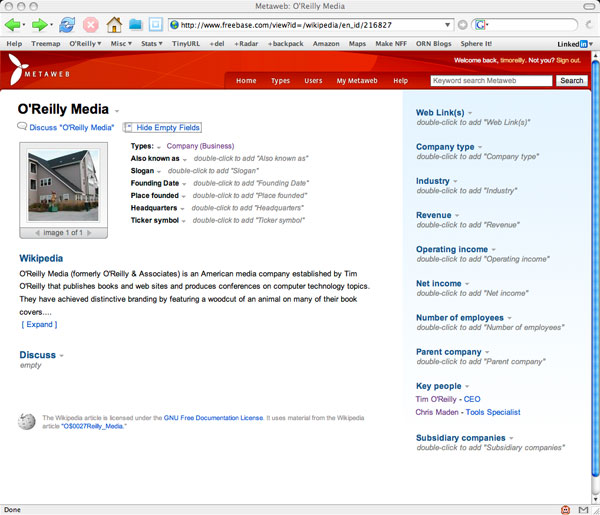
Now, I can fill in various data items that I know about with O’Reilly Media. For example, I’ve added the fact that O’Reilly was founded in Newton, MA, is currently headquartered in Sebastopol, California, and has some subsidiary companies.
And here’s where the magic happens. Now, when I go to the “companies” page, the new companies I’ve listed now have entries of their own.
Much as in wikipedia, any entry listing an entity not already known creates a new page. But these entries are structured — if I add a person, they are of type person. If I add a location, they are of type location. If I add a company, they are of type company. And each of these things comes with certain relationships, and that allows other entries to be automatically updated.
When Danny first showed me this application a couple of months ago, there was a really powerful example of the way this ought to work. We were looking at the tracks for Brian Eno’s album Bell Studies for the Clock of the Long Now. Danny noted that he was actually the composer of one of the tracks, 1st-14th January 07003, Hard Bells, Hillis Algorithm. Robert Cook, who was doing the demo, immediately added Danny as the composer. Then, when we went to Danny Hillis’ page, we saw that he was now listed as a composer as well as a computer scientist.
Now that was a demo. In playing with the application since, I’ve found that some of these work in theory, but not yet in fact. For example, as I added myself as the CEO of O’Reilly Media, that should have also updated the entry for Tim O’Reilly (person), but it didn’t. (I may not have created a new Tim O’Reilly rather than selecting the existing entry.) In theory, the entry for Sebastopol, California should have changed to reflect a new company located there, but it didn’t.
In addition, two of the companies I added as O’Reilly subsidiaries aren’t really subsidiaries, which suggests wholly-owned companies, but affiliates. Safari Books Online is a joint venture with Pearson, and O’Reilly AlphaTech Ventures is a partnership that we are a member of. I don’t have the privileges to create a new field in a company record, “Affiliated companies,” but presumably, if it takes off, Metaweb will promote community members to the level where they can make these kinds of edits.
But hopefully, this narrative will give you a sense of what Metaweb is reaching for: a wikipedia like system for building the semantic web. But unlike the W3C approach to the semantic web, which starts with controlled ontologies, Metaweb adopts a folksonomy approach, in which people can add new categories (much like tags), in a messy sprawl of potentially overlapping assertions.
Now, the really powerful thing about this is that all these categories, these data types and the web of fields that define them, provide new hooks for applications that will be able to extract meaning from the data. That’s what makes Metaweb a kind of semantic web application.
If Metaweb gets this right, this bottom up approach will build new connections between data, new categories and ways of thinking. It will likely be messy and contradictory for a while, but as I told John Markoff for the story on Metaweb that he was preparing for the New York Times tonight, they are building new synapses for the global brain.
And if you know anything about our own intelligence, you realize that our own pattern recognition works much the same way. We arrange the world in categories. Many of our categories are wrong, or in conflict — hence our many squabbles and even wars — but collectively, we make sense of things.
It’s name is appropriate for many reasons. Yes, it is a free database, it is addictive, and its name is overloaded with multiple meanings, just like so many things we try to make sense of. But we have the ability to disambiguate those meanings, and to take them both in, with the overtones and conflicts actually giving additional meaning.
Metaweb still has a long way to go, but it seems to me that they are pointing the way to a fascinating new chapter in the evolution of Web 2.0.