
Google App Engine went down earlier today. GAE is still a developer preview release, and currently lacks a public monitoring dashboard. Unfortunately this means that many people either found out from their app and/or admin consoles being unavailable or from Mike Arrington’s post on TechCrunch.
Google has a strong Web Operations culture, and there are numerous internal monitoring tools in use across the company, along with a smaller set available to customers. It’s suprising that Google launched a developer platform without providing something beyond an email group, although they are by no means the first to do so.
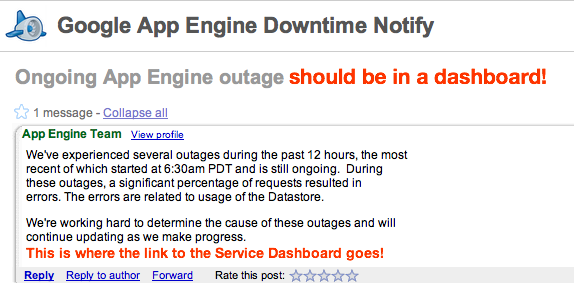
Service Monitoring Dashboards are mandatory for production services and platforms!
- If you launch a platform that people pay you money for, you need to have a real time service dashboard. Ideally this should be decoupled from the rest of your infrastructure.
- Don’t rely on platforms that lack service monitoring dashboards for production.
Many companies are initially reluctant to provide this kind of monitoring to the public, and only do so in reaction to an outage. However, it seems that every company that offers such a dashboard uses it as a source of competitive advantage.
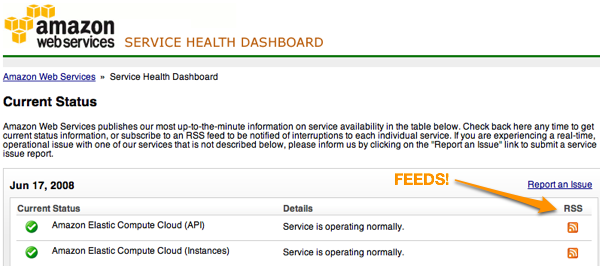
The best example of this is trust.salesforce.com which they launched after series of outages in 2006. Amazon (eventually) launched a status dashboard for AWS, and added RSS feeds for specific services which I think is pretty cool.
Javier Soltero at Hyperic points out
1. The reports of service outages arrive long after anyone who depends on the services can possibly do anything to mitigate their effect.
2. The services themselves seem incapable of providing any visibility into the circumstances that might lead to future outages.[…]Even TechCrunch points out that the Google Apps blog doesn’t even mention the outage. Other clouds rely on blogs such as this one, this one, or maybe even this one (from our good friends at Mosso). These are all places where outages can be discussed, but not the right means for people to find out whether it their application that crashed, or the cloud that it depends on.
(Updated:Niall Kennedy pointed out that GAE is still a preview release, and I agree that my original wording was wrong. My intent is to emphasize the importance of providing a public service dashboard and so I’ve edited accordingly.)