
Theo Schlossnagle, author of Scalable Internet Architectures, gave a great explanation of how internet traffic spikes are shifting:
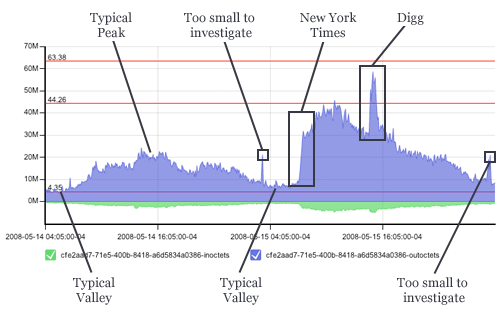
Lately, I see more sudden eyeballs and what used to be an established trend seems to fall into a more chaotic pattern that is the aggregate of different spike signatures around a smooth curve. This graph is from two consecutive days where we have a beautiful comparison of a relatively uneventful day followed by long-exposure spike (nytimes.com) compounded by a short-exposure spike (digg.com):
The disturbing part is that this occurs even on larger sites now due to the sheer magnitude of eyeballs looking at today’s already popular sites. Long story short, this makes planning a real bitch.
[…]What isn’t entirely obvious in the above graphs? These spikes happen inside 60 seconds. The idea of provisioning more servers (virtual or not) is unrealistic. Even in a cloud computing system, getting new system images up and integrated in 60 seconds is pushing the envelope and that would assume a zero second response time. This means it is about time to adjust what our systems architecture should support. The old rule of 70% utilization accommodating an unexpected 40% increase in traffic is unraveling. At least eight times in the past month, we’ve experienced from 100% to 1000% sudden increases in traffic across many of our clients.
[Link]