
Here are a few of the data stories that caught my eye this week.
Hadoop competition heats up
 As the number of Hadoop vendors increases, companies are looking for ways to differentiate themselves. A couple of announcements this past week point to the angles vendors are taking.
As the number of Hadoop vendors increases, companies are looking for ways to differentiate themselves. A couple of announcements this past week point to the angles vendors are taking.
Infrastructure company Rainstor announced that its latest data retention technology can be deployed using Cloudera’s Hadoop distribution. Rainstor says it will improve the Hadoop Distributed File System with better compression and de-duplication, and it promises a physical footprint that is at least 97% smaller.
In other Hadoop news, MapR revealed that it will serve as the storage component for EMC’s recently announced Greenplum HD Enterprise Edition Hadoop distribution. EMC’s Hadoop distribution is not based on the official Apache Software Foundation version of the code, but is instead based on Facebook’s optimized version.
In an interesting twist, MapR also became an official contributor to the Apache Hadoop project this week. As GigaOm’s Derrick Harris observes:
More contributors [to Hadoop] means more (presumably) great ideas to choose from and, ideally, more voices deciding what changes to adopt and which ones to leave alone. For individual companies, getting officially involved with Apache means that perhaps Hadoop will evolve in ways that actually benefit their products that are based upon or seeking to improve Hadoop.
 OSCON Data 2011, being held July 25-27 in Portland, Ore., is a gathering for developers who are hands-on, doing the systems work and evolving architectures and tools to manage data. (This event is co-located with OSCON.)
OSCON Data 2011, being held July 25-27 in Portland, Ore., is a gathering for developers who are hands-on, doing the systems work and evolving architectures and tools to manage data. (This event is co-located with OSCON.)
Visualizing Facebook’s PHP codebase
Facebook’s Greg Schechter offered an explanation this week of how and why Facebook built a visualization project in order to better grasp some of the interdependencies among the more than 10,000 modules that comprise Facebook’s front-end code.
Facebook has been normalizing its PHP usage, particularly as it relates to managing modules’ dependencies. With its new system, when a module is written or modified, other modules that are directly dependent are fully determinable. This makes sure that circular dependencies are avoided.
But graphing this with a classic “arc-and-node” graph visualization won’t work at Facebook’s scale, so at a recent hackathon, the company came up with a better visualization method.
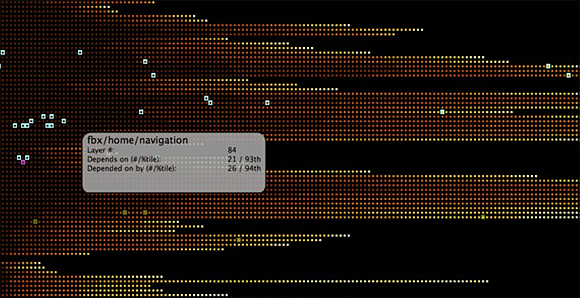
Screen from Facebook PHP codebase visualization. See more here.
This method divides the information into layers, where each row represents a layer and a layer’s modules are dependent only on modules in the rows below it, and are depended upon only by modules in the rows above it. The visualization also colors modules more darkly if they have more dependencies.
A few screens showing the visualization are available here. Unfortunately, the full tool is only available internally for the Facebook engineering team.
Visualizing Shaquille O’Neal’s data
In honor of the end of Shaquille O’Neal’s 19-year NBA career (an announcement he tweeted yesterday), data journalist Matt Stiles has created an interactive visualization of the star’s stats.
The visualization was created using data from basketball-reference.com and the Many Eyes data visualization tool. The Atlantic’s Alexis Madrigal used the tool to take a look at Shaq’s shoddy free-throw record.
While Shaq’s career — and now his retirement — provide ample data for off-hand curiosity, the merging of sports stats and visualizations also opens the door to broader opportunities and new kinds of data products.
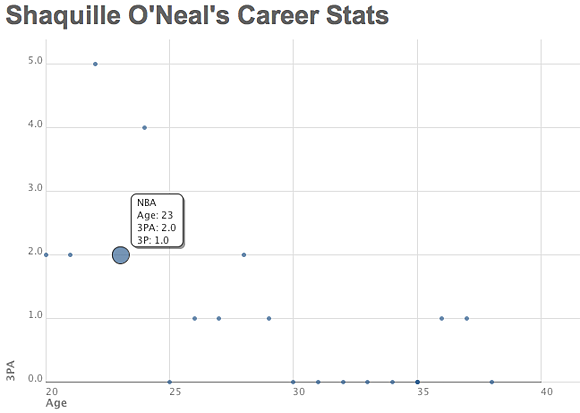
Because few things are funnier than a center lofting three pointers, this graph matches Shaquille O’Neal’s age against his three-point attempts. He hit a high-water mark (the big dot) at 23 when he attempted two three pointers and hit the only three of his career.
Got data news?
Feel free to email me.
Related: