
Here are a few of the data stories that caught my attention this week.
IBM’s record-breaking data storage array
 IBM Research is building a new data storage array that’s almost 10 times larger than anything that’s been built before. The data array is comprised of 200,000 hard drives working together, with a storage capacity of 120 petabytes — that’s 120 million gigabytes. To give you some idea of the capacity of the new “drive,” writes MIT Technology Review, “a 120-petabyte drive could hold 24 billion typical five-megabyte MP3 files or comfortably swallow 60 copies of the biggest backup of the Web, the 150 billion pages that make up the Internet Archive’s WayBack Machine.”
IBM Research is building a new data storage array that’s almost 10 times larger than anything that’s been built before. The data array is comprised of 200,000 hard drives working together, with a storage capacity of 120 petabytes — that’s 120 million gigabytes. To give you some idea of the capacity of the new “drive,” writes MIT Technology Review, “a 120-petabyte drive could hold 24 billion typical five-megabyte MP3 files or comfortably swallow 60 copies of the biggest backup of the Web, the 150 billion pages that make up the Internet Archive’s WayBack Machine.”
Data storage at that scale creates a number of challenges, including — no surprise — cooling such a massive system. But other problems include handling failure, backups and indexing. The new storage array will benefit from other research that IBM has been doing to help boost supercomputers’ data access. Its General Parallel File System was designed with this massive volume in mind. The GPFS spreads files across multiple disks so that many parts of a file can be read or written at once. This system already demonstrated that it can perform when it set a new scanning speed record last month by indexing 10 billion files in just 43 minutes.
IBM’s new 120-petabyte drive was built at the request of an unnamed client that needed a new supercomputer for “detailed simulations of real-world phenomena.”
 Strata Conference New York 2011, being held Sept. 22-23, covers the latest and best tools and technologies for data science — from gathering, cleaning, analyzing, and storing data to communicating data intelligence effectively.
Strata Conference New York 2011, being held Sept. 22-23, covers the latest and best tools and technologies for data science — from gathering, cleaning, analyzing, and storing data to communicating data intelligence effectively.
Infochimps’ new Geo API
![]() The data marketplace Infochimps released a new Geo API this week, giving developers access to a number of disparate location-related datasets via one API with a unified schema.
The data marketplace Infochimps released a new Geo API this week, giving developers access to a number of disparate location-related datasets via one API with a unified schema.
According to Infochimps, the API addresses several pain points that those working with geodata face:
- Difficulty in integrating several different APIs into one unified app
- Lack of ability to display all results when zoomed out to a large radius
- Limitation of only being able to use lat/long
To address these issues, Infochimps has created a new simple schema to help make data consistent and unified when drawn from multiple sources. The company has also created a “summarizer” to intelligently cluster and better display data. And finally, it has also enabled the API to handle queries other than just those traditionally associated with geodata, namely latitude and longitude.
As we seek to pull together and analyze all types of data from multiple sources, this move toward a unified schema will become increasingly important.
Hurricane Irene and weather data
The arrival of Hurricane Irene last week reiterated the importance not only of emergency preparedness but of access to real-time data — weather data, transportation data, government data, mobile data, and so on.
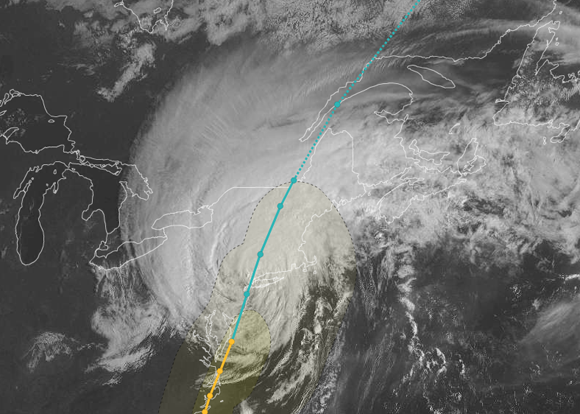
Screenshot from the New York Times’ interactive Hurricane Irene tracking map. See the full version.
As Alex Howard noted here on Radar, crisis data is becoming increasingly social:
We’ve been through hurricanes before. What’s different about this one is the unprecedented levels of connectivity that now exist up and down the East Coast. According to the most recent numbers from the Pew Internet and Life Project, for the first time, more than 50% of American adults use social networks. 35% of American adults have smartphones. 78% of American adults are connected to the Internet. When combined, those factors mean that we now see earthquake tweets spread faster than the seismic waves themselves. The growth of an Internet of things is an important evolution. What we’re seeing this weekend is the importance of an Internet of people.”
Got data news?
Feel free to email me.
Hard drive photo: Hard Drive by walknboston, on Flickr
Related:
{kind=link}