
Here are the data stories that caught my attention this week:
Oracle’s big data week
 Eyes have been on Oracle this week as it holds its OpenWorld event in San Francisco. The company has made a number of major announcements, including unveiling its strategy for handling big data. This includes its Big Data Appliance, which will use a new Oracle NoSQL database as well as an open-source distribution of Hadoop and R.
Eyes have been on Oracle this week as it holds its OpenWorld event in San Francisco. The company has made a number of major announcements, including unveiling its strategy for handling big data. This includes its Big Data Appliance, which will use a new Oracle NoSQL database as well as an open-source distribution of Hadoop and R.
Edd Dumbill examined the Oracle news, arguing that “it couldn’t be a plainer validation of what’s important in big data right now or where the battle for technology dominance lies.” He notes that whether one is an Oracle customer or not, the company’s announcement “moves the big data world forward,” pointing out that there is now a de facto agreement that Hadoop and R are core pieces of infrastructure.
GigaOm’s Derrick Harris reached out to some of the startups who also offer these core pieces, including Norman Nie, the CEO of Revolution Analytics, and Mike Olson, CEO of Cloudera. Not surprisingly perhaps, the startups are “keeping brave faces, but the consensus is that Oracle’s forays into their respective spaces just validate the work they’ve been doing, and they welcome the competition.”
Oracle’s entry as a big data player also brings competition to others in the space, such as IBM and EMC, as all the major enterprise providers wrestle to claim supremacy over whose capabilities are the biggest and fastest. And the claim that “we’re faster” was repeated over and over by Oracle CEO Larry Ellison as he made his pitch to the crowd at OpenWorld.
 Web 2.0 Summit, being held October 17-19 in San Francisco, will examine “The Data Frame” — focusing on the impact of data in today’s networked economy.
Web 2.0 Summit, being held October 17-19 in San Francisco, will examine “The Data Frame” — focusing on the impact of data in today’s networked economy.
Who wrote Hadoop?
 As ReadWriteWeb’s Joe Brockmeier notes, ascertaining the contributions to open-source projects is sometimes easier said than done. Who gets credit — companies or individuals — can be both unclear and contentious. Such is the case with a recent back-and-forth between Cloudera’s Mike Olson and Hortonworks’ Owen O’Malley over who’s responsible for the contributions to Hadoop.
As ReadWriteWeb’s Joe Brockmeier notes, ascertaining the contributions to open-source projects is sometimes easier said than done. Who gets credit — companies or individuals — can be both unclear and contentious. Such is the case with a recent back-and-forth between Cloudera’s Mike Olson and Hortonworks’ Owen O’Malley over who’s responsible for the contributions to Hadoop.
O’Malley wrote a blog post titled “The Yahoo! Effect,” which, as the name suggests, describes Yahoo’s legacy and its continuing contributions to the Hadoop core. O’Malley argues that “from its inception until this past June, Yahoo! contributed more than 84% of the lines of code still in Apache Hadoop trunk.” (Editor’s note: The link to “trunk” was inserted for clarity.) O’Malley adds that so far this year, the biggest contributors to Hadoop are Yahoo! and Hortonworks.
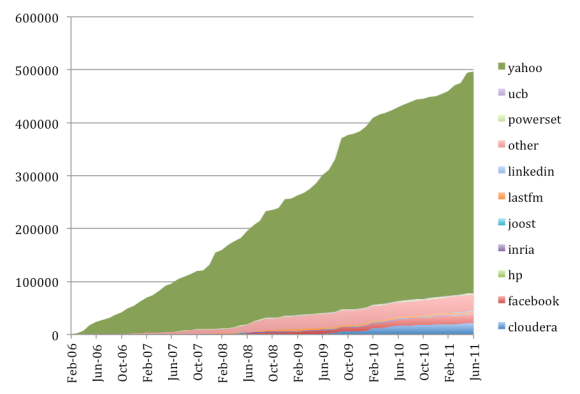 Lines of code contributed to Apache Hadoop Trunk (from Owen O’Malley’s post, “The Yahoo! Effect”)
Lines of code contributed to Apache Hadoop Trunk (from Owen O’Malley’s post, “The Yahoo! Effect”)
That may not be a surprising argument to hear from Hortonworks, the company that was spun out of Yahoo! earlier this year to focus on the commercialization and development of Hadoop.
But Cloudera’s Mike Olson challenges that argument — again, not a surprise, as Cloudera has long positioned itself as a major contributor to Hadoop, a leader in the space, and of course now the employer of former Yahoo! engineer Doug Cutting, the originator of the technology. Olson takes issue with O’Malley’s calculations and in a blog post of his own, contends that these calculations don’t accurately take into account the companies that people now work for:
Five years is an eternity in the tech industry, however, and many of those developers moved on from Yahoo! between 2006 and 2011. If you look at where individual contributors work today — at the organizations that pay them, and at the different places in the industry where they have carried their expertise and their knowledge of Hadoop — the story is much more interesting.
Olson also argues that it isn’t simply a matter of who’s contributing to the Apache Hadoop core, but rather who is working on:
… the broader ecosystem of projects. That ecosystem has exploded in recent years, and most of the innovation around Hadoop is now happening in new projects. That’s not surprising — as Hadoop has matured, the core platform has stabilized, and the community has concentrated on easing adoption and simplifying use.
Got data news?
Feel free to email me.
Related: