
Microsoft has placed Apache Hadoop at the core of its big data strategy. It’s a move that might seem surprising to the casual observer, being a somewhat enthusiastic adoption of a significant open source product.
The reason for this move is that Hadoop, by its sheer popularity, has become the de facto standard for distributed data crunching. By embracing Hadoop, Microsoft allows its customers to access the rapidly-growing Hadoop ecosystem and take advantage of a growing talent pool of Hadoop-savvy developers.
Microsoft’s goals go beyond integrating Hadoop into Windows. It intends to contribute the adaptions it makes back to the Apache Hadoop project, so that anybody can run a purely open source Hadoop on Windows.
Microsoft’s Hadoop distribution
The Microsoft distribution of Hadoop is currently in “Customer Technology Preview” phase. This means it is undergoing evaluation in the field by groups of customers. The expected release time is toward the middle of 2012, but will be influenced by the results of the technology preview program.
Microsoft’s Hadoop distribution is usable either on-premise with Windows Server, or in Microsoft’s cloud platform, Windows Azure. The core of the product is in the MapReduce, HDFS, Pig and Hive components of Hadoop. These are certain to ship in the 1.0 release.
As Microsoft’s aim is for 100% Hadoop compatibility, it is likely that additional components of the Hadoop ecosystem such as Zookeeper, HBase, HCatalog and Mahout will also be shipped.
Additional components integrate Hadoop with Microsoft’s ecosystem of business intelligence and analytical products:
- Connectors for Hadoop, integrating it with SQL Server and SQL Sever Parallel Data Warehouse.
- An ODBC driver for Hive, permitting any Windows application to access and run queries against the Hive data warehouse.
- An Excel Hive Add-in, which enables the movement of data directly from Hive into Excel or PowerPivot.
On the back end, Microsoft offers Hadoop performance improvements, integration with Active Directory to facilitate access control, and with System Center for administration and management.
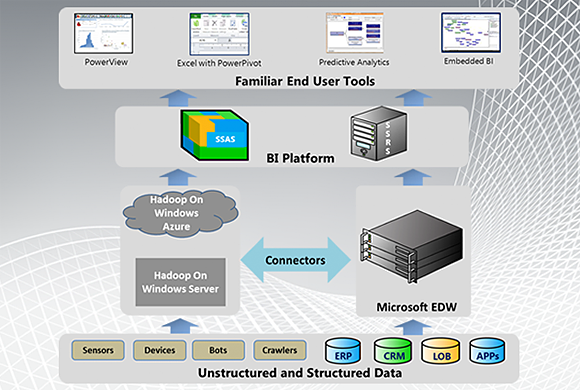
How Hadoop integrates with the Microsoft ecosystem. (Source: microsoft.com.)
Developers, developers, developers
One of the most interesting features of Microsoft’s work with Hadoop is the addition of a JavaScript API. Working with Hadoop at a programmatic level can be tedious: this is why higher-level languages such as Pig emerged.
Driven by its focus on the software developer as an important customer, Microsoft chose to add a JavaScript layer to the Hadoop ecosystem. Developers can use it to create MapReduce jobs, and even interact with Pig and Hive from a browser environment.
The real advantage of the JavaScript layer should show itself in integrating Hadoop into a business environment, making it easy for developers to create intranet analytical environments accessible by business users. Combined with Microsoft’s focus on bringing server-side JavaScript to Windows and Azure through Node.js, this gives an interesting glimpse into Microsoft’s view of where developer enthusiasm and talent will lie.
It’s also good news for the broader Hadoop community, as Microsoft intends to contribute its JavaScript API to the Apache Hadoop open source project itself.
The other half of Microsoft’s software development environment is of course the .NET platform. With Microsoft’s Hadoop distribution, it will be possible to create MapReduce jobs from .NET, though using the Hadoop APIs directly. It is likely that higher-level interfaces will emerge in future releases. The same applies to Visual Studio, which over time will get increasing levels of Hadoop project support.
Streaming data and NoSQL
Hadoop covers part of the big data problem, but what about streaming data processing or NoSQL databases? The answer comes in two parts, covering existing Microsoft products and future Hadoop-compatible solutions.
Microsoft has some established products: Its streaming data solution called StreamInsight, and for NoSQL, Windows Azure has a product called Azure Tables.
Looking to the future, the commitment of Hadoop compatibility means that streaming data solutions and NoSQL databases designed to be part of the Hadoop ecosystem should work with the Microsoft distribution — HBase itself will ship as a core offering. It seems likely that solutions such as S4 will prove compatible.
Toward an integrated environment
Now that Microsoft is on the way to integrating the major components of big data tooling, does it intend to join it all together to provide an integrated data science platform for businesses?
That’s certainly the vision, according to Madhu Reddy, senior product planner for Microsoft Big Data: “Hadoop is primarily for developers. We want to enable people to use the tools they like.”
The strategy to achieve this involves entry points at multiple levels: for developers, analysts and business users. Instead of choosing one particular analytical platform of choice, Microsoft will focus on interoperability with existing tools. Excel is an obvious priority, but other tools are also important to the company.
According to Reddy, data scientists represent a spectrum of preferences. While Excel is a ubiquitous and popular choice, other customers use Matlab, SAS, or R, for example.
The data marketplace
One thing unique to Microsoft as a big data and cloud platform is its data market, Windows Azure Marketplace. Mixing external data, such as geographical or social, with your own, can generate revealing insights. But it’s hard to find data, be confident of its quality, and purchase it conveniently. That’s where data marketplaces meet a need.
The availability of the Azure marketplace integrated with Microsoft’s tools gives analysts a ready source of external data with some guarantees of quality. Marketplaces are in their infancy now, but will play a growing role in the future of data-driven business.
Summary
The Microsoft approach to big data has ensured the continuing relevance of its Windows platform for web-era organizations, and makes its cloud services a competitive choice for data-centered businesses.
Appropriately enough for a company with a large and diverse software ecosystem of its own, the Microsoft approach is one of interoperability. Rather than laying out a golden path for big data, as suggested by the appliance-oriented approach of others, Microsoft is foc
using heavily on integration.
The guarantee of this approach lies in Microsoft’s choice to embrace and work with the Apache Hadoop community, enabling the migration of new tools and talented developers to its platform.
 Microsoft SQL Server is a comprehensive information platform offering enterprise-ready technologies and tools that help businesses derive maximum value from information at the lowest TCO. SQL Server 2012 launches next year, offering a cloud-ready information platform delivering mission-critical confidence, breakthrough insight, and cloud on your terms; find out more at www.microsoft.com/sql.
Microsoft SQL Server is a comprehensive information platform offering enterprise-ready technologies and tools that help businesses derive maximum value from information at the lowest TCO. SQL Server 2012 launches next year, offering a cloud-ready information platform delivering mission-critical confidence, breakthrough insight, and cloud on your terms; find out more at www.microsoft.com/sql.Related: