
A large portion of this week’s Amp Camp at UC Berkeley, is devoted to an introduction to Spark – an open source, in-memory, cluster computing framework. After playing with Spark over the last month, I’ve come to consider it a key part of my big data toolkit. Here’s why:
Hadoop integration: Spark can work with files stored in HDFS, an important feature given the amount of investment in the Hadoop Ecosystem. Getting Spark to work with MapR is straightforward.
The Spark interactive Shell: Spark is written in Scala, and has it’s own version of the Scala interpreter. I find this extremely convenient for testing short snippets of code.
The Spark Analytic Suite:
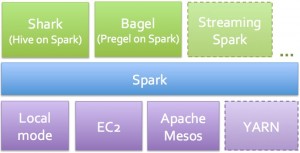
(Figure courtesy of Matei Zaharia)
Spark comes with tools for interactive query analysis (Shark), large-scale graph processing and analysis (Bagel), and real-time analysis (Spark Streaming). Rather than having to mix and match a set of tools (e.g., Hive, Hadoop, Mahout, S4/Storm), you only have to learn one programming paradigm. For SQL enthusiasts, the added bonus is that Shark tends to run faster than Hive. If you want to run Spark in the cloud, there are a set of EC2 scripts available.
Resilient Distributed Data sets (RDD’s):
RDD’s are distributed objects that can be cached in-memory, across a cluster of compute nodes. They are the fundamental data objects used in Spark. The crucial thing is that fault-tolerance is built-in: RDD’s are automatically rebuilt if something goes wrong. If you need to test something out, RDD’s can even be used interactively from the Spark interactive shell.
Distributed Operators:
Aside from Map and Reduce, there are many other operators one can use on RDD’s. Once I familiarized myself with how they work, I began converting a few basic machine-learning and data processing algorithms into this framework.
Once you get past the learning curve … iterative programs
It takes some effort to become productive in anything, Spark is no exception. I was a complete Scala newbie so I first had to get comfortable with a new language (apparently, they like underscores – see here, here, and here). Beyond Scala one can use Shark (“SQL” on Spark), and relatively new Java and Python API’s.
You can use the examples that come with Spark to get started, but I found the essential thing is to get comfortable with the built-in distributed operators. Once I learned RDD’s and the operators, I started writing iterative programs to implement a few machine-learning and data processing algorithms. (Since Spark distributes & caches data in-memory, you can write pretty fast machine-learning programs on massive data sets.)
It’s already used in production
Is anyone really using Spark? While the list of companies is still small, judging from the size of the SF Spark Meetup and Amp Camp, I expect many more companies to start deploying Spark. (If you’re in the SF Bay Area, we are starting a new Distributed Data Processing Meetup with Airbnb, and Spark is one one of the topics we’ll cover.)
Update (8/23/2012): Here’s another important reason to like Spark – at 14,000 lines of code it’s much simpler than other software used for Big Data.
The Spark codebase is small, extensible, and hackable.
Matei’s last presentation at Amp Camp included the diagram below (LOC = lines of code):

(Figure courtesy of Matei Zaharia)