
In an earlier post I listed a few reasons why I’ve come to embrace and use Spark. In particular I described why Spark is well-suited for many distributed Big Data Analytics tasks such as iterative computations and interactive queries, where it outperforms Hadoop. With version 0.6, Spark becomes even0 faster and easier to use. The release notes contain all the detailed changes, but as you’ll see from the highlights1 below, version 0.6 is a substantial release. Another good sign is the growth in number of contributors, with now over a third of the developers coming from outside the core team in Berkeley.
New Deployment Modes
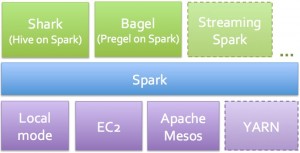
In addition to running on top of Mesos, Spark can now be deployed in standalone mode: users only need to install Spark and a JVM on each node, a simple cluster manager2 that comes with Spark 0.6, handles the rest. Deployment becomes much simpler and allows organizations who aren’t familiar with Mesos (and C++) to run Spark on their clusters. This release also provides an experimental mode for running Spark on Apache YARN.
New Java API
While I use Spark exclusively through Scala, many Java developers have been asking for a Java API. With version 0.6 the wait is over: all of Spark’s features can be accessed from Java through an API. A Python API is coming very soon.
RDD persistence options
RDD’s are distributed objects that can be cached in-memory, across a cluster of compute nodes. They are the fundamental data objects used in Spark. In version 0.6 caching policy can be controlled at the individual RDD level. Users can decide whether to keep an RDD in-memory or on disk, serialize it, or replicate3 it across nodes.
Significant Performance Improvements
Spark’s communication layer has been rewritten4 resulting in lower latencies particularly for interactive queries, and for answering requests from front-end applications. Shuffle was also rewritten5, resulting in many common RDD operators such as “groupByKey”, “reduceByKey” and sorts, running up to 2x faster.
Developer Tools and Documentation
Beginning with version 0.6, Spark will come with an easy-to-browse HTML documentation in the source tree. Also Spark and Mesos will now be published through Maven, making it more convenient to link to both projects. With improved logging, debugging tools should make it easier to see how long each part of your code is taking.
Shark updates (Shark version 0.2)
Spark provides a suite of tools6 for many common types of analysis. For interactive query analysis Shark7 supports supports SQL-like queries via HiveQL. Because of inter-query caching of data Shark tends to run much faster than Hive.
The primary performance improvement in Shark version 0.2 is in joins and group bys: a combination of factors have led to performance increases of up to 2x. First as noted above Shuffle is much faster in Spark 0.6. Developers also reduced the amount of temporary objects created in group bys and joins (which impacts JVM garbage collection time). Finally unnecessary double buffering of data or operations were eliminated.
Other updates available with the release of Shark 0.2 include: (1) Shark will work with Spark 0.6’s standalone deploy mode, (2) support for Hive version 0.9, (3) ability to add and distribute UDF’s and UDAF’s to slaves using8 Hive’s ADD FILE command, (4) Shark Thrift server mode (contributed by Yahoo! and compatible with Hive’s Thrift server), lets multiple clients access a data warehouse using the same set of cached tables.
In addition, Shark version 0.3 will be released in a few weeks. Version 0.3 updates include compression for columns, range pruning for cached tables, and a simple dashboard for tracking Shark’s memory usage on a cluster.
One more thing: in a few weeks there will be another important release involving Spark Streaming (for real-time apps). Finally look for O’Reilly’s Learning Spark book in early 2013! It will be co-written by Matei Zaharia, the creator and primary developer of Spark.
Related post:
(0) Many Spark users already swear by its usability and performance. I love the fact that the Spark development team continues to focus on features that will help grow the number of users.
(1) This post is based on interviews with Matei Zaharia and Reynold Xin, lead developers of Spark and Shark.
(2) The slimmed down cluster manager was built specifically to run Spark. It comes with a web interface for viewing cluster activity and processes.
(3) For RDD’s, this wasn’t possible prior to version 0.6.
(4) This involved “control plane optimizations”.
(5) To speed up computations that involve network operations, Shuffle was changed from HTTP-based to asynchronous NIO.
(6) Rather than having to mix and match a set of tools (e.g., Hive, Hadoop, Mahout, S4/Storm), you only have to learn one programming paradigm.
(7) The main difference between Hive and Shark is in the generation of physical plans: in Hive they turn into separate Map and Reduce tasks, while in Shark they become operators that transform RDD’s.
(8) Users previously had to include the UDFs as JARs on the classpath.