
The choice of tools for data science includes1 factors like scalability, performance, and convenience. A while back I noted that data scientists tended to fall into two camps: those who used an integrated stack, and others who tended to stitch together frameworks. Being able to stick with the same programming language and environment is a definite productivity boost since it requires less setup time and context-switching.
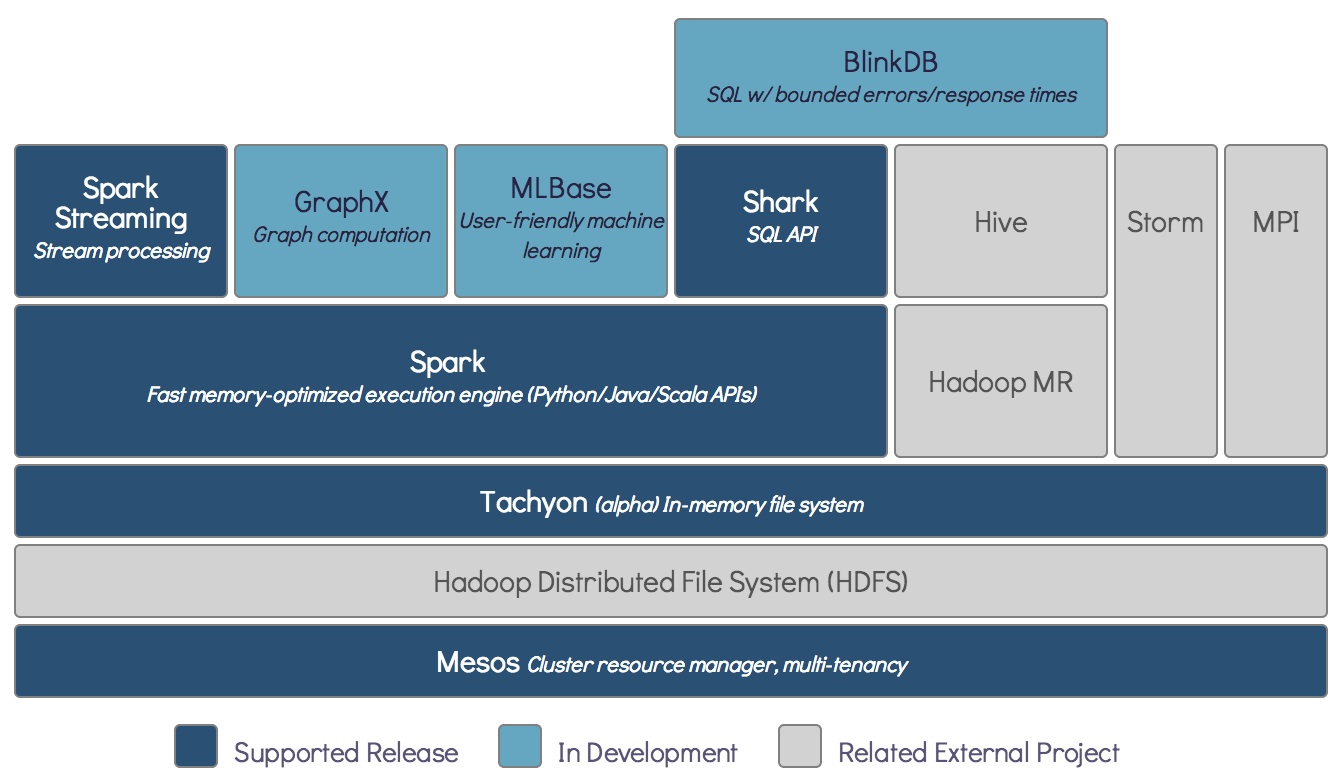
More recently I highlighted the emergence of composable analytic engines, that leverage data stored in HDFS (or HBase and Accumulo). These engines may not be the fastest available, but they scale to data sizes that cover most workloads, and most importantly they can operate on data stored in popular distributed data stores. The fastest and most complete set of algorithms will still come in handy, but I suspect that users will opt for slightly slower2, but more convenient tools, for many routine analytic tasks.
Interactive Query Analysis: SQL-directly-on-Hadoop
Hadoop was originally a batch processing platform but late last year a series of interactive3 query engines became available – beginning with Impala and Shark, users now have a range of tools for querying data in Hadoop/HBase/Accumulo including Phoenix, Sqrrl, Hadapt, and Pivotal-HD. These engines tend to be slower than MPP databases: early tests showed that Impala and Shark ran slower than an MPP database (AWS Redshift). MPP databases may always be faster, but the Hadoop-based query engines only need to be within range (“good enough”) before convenience (and price per terabyte) persuades companies to offload many tasks over to them. I also expect these new query engines to improve4 substantially as they’re all still fairly new and many more enhancements are planned.
Graph Processing
Apache Giraph is one of several BSP-inspired graph processing frameworks that have come out over the last few years. It runs on top of Hadoop making it an attractive framework for companies with data in HDFS and who rely on tools within the Hadoop ecosystem. At the recent GraphLab workshop, Avery Ching of Facebook alluded to convenience and familiarity as crucial factors for their heavy use of Giraph. Another example is GraphX, the soon to be released graph processing component of the BDAS stack. It runs slower than GraphLab but hopes to find an audience5 among Spark users.
Machine-learning
With Cloudera ML and its recent acquisition of Myrrix, I expect Cloudera will at some point release an advanced analytics library that integrates nicely with CDH and its other engines (Impala and Search). The first release of MLbase, the machine-learning component of BDAS, is scheduled over the next few weeks and is set to include tools for many basic tasks (clustering, classification, regression, and collaborative filtering). I don’t expect these tools (MLbase, Mahout) to outperform specialized frameworks like GraphLab, SkyTree, H20, or wise.io. But having seen how convenient and easy it is to use MLbase from within Spark/Scala, I can see myself turning to it for many routine6 analyses.
Integrated engines are in their early stages
Data in distributed systems like Hadoop can now be analyzed in situ using a variety of analytic engines. These engines are fairly new, and performance improvements will narrow the gap with specialized systems. This is good news for data scientists: they can perform preliminary and routine analyses using tightly integrated engines, and use the more specialized systems for the latter stages of the analytic lifecycle.
Related posts:
(1) There are many other factors involved including cost, importance of open source, programming language, and maturity (at this point, specialized engines have many more “standard” features).
(2) As long as performance difference isn’t getting in the way of their productivity.
(3) What made things a bit confusing for outsiders is the Hadoop community referring to interactive query analysis, as real-time.
(4) Performance gap will narrow over time – many of these engines are less than a year old!
(5) As I previously noted, the developers of GraphX admit that GraphLab will probably always be faster: “We emphasize that it is not our intention to beat PowerGraph in performance. … We believe that the loss in performance may, in many cases, be ameliorated by the gains in productivity achieved by the GraphX system. … It is our belief that we can shorten the gap in the near future, while providing a highly usable interactive system for graph data mining and computation.”
(6) Taking the idea of streamlining a step further, it wouldn’t surprise me if we start seeing one of the Hadoop query engines incorporate “in-database” analytics.
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata Rx Health Data Conference: September 25-27 | Boston, MA
Strata + Hadoop World: October 28-30 | New York, NY
Strata in London: November 15-17 | London, England