
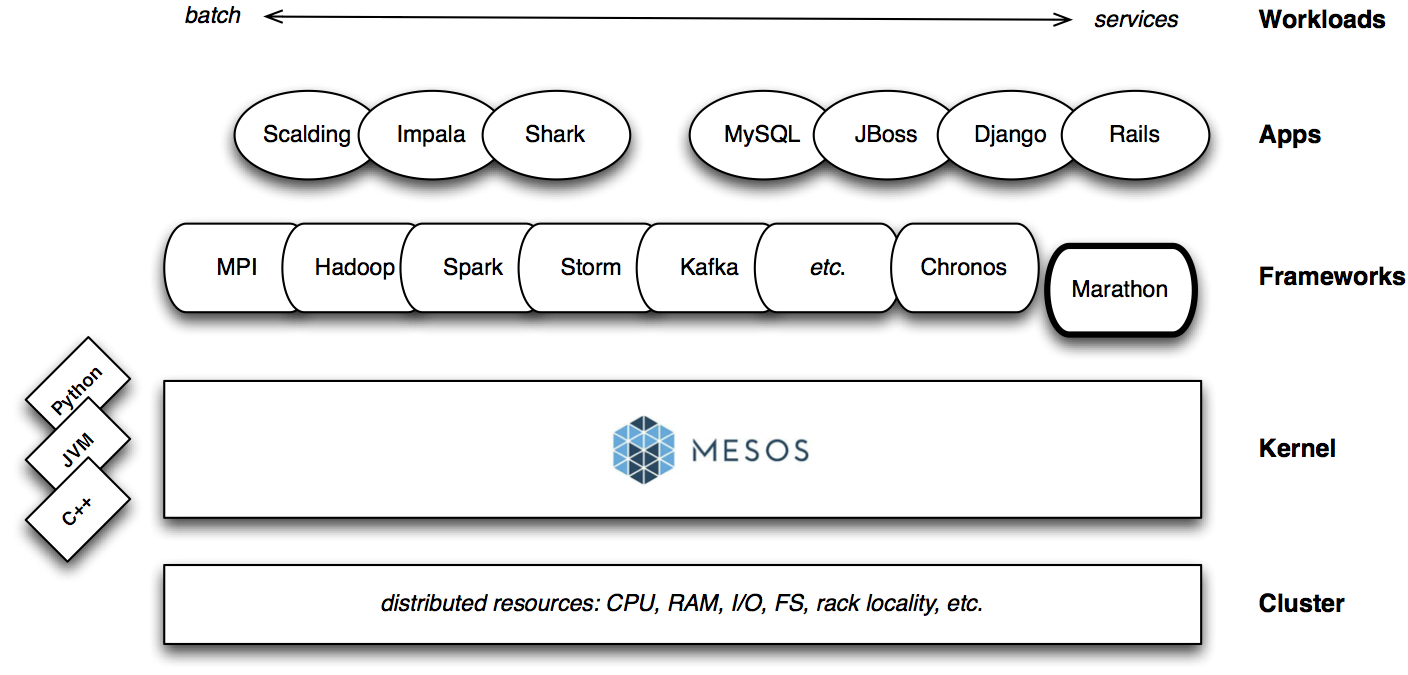
As organizations increasingly rely on large computing clusters, tools for leveraging and efficiently managing compute resources become critical. Specifically, tools that allow multiple services and frameworks run on the same cluster can significantly increase utilization and efficiency. Schedulers1 take into account policies and workloads to match jobs with appropriate resources (e.g., memory, storage, processing power) in a large compute cluster. With the help of schedulers, end users begin thinking of a large cluster as a single resource (like “a laptop”) that can be used to run different frameworks (e.g., Spark, Storm, Ruby on Rails, etc.).
Multi-tenancy and efficient utilization translates into improved ROI. Google’s scheduler, Borg, has been in production for many years and has led to substantial savings2. The company’s clusters handle a variety of workloads that can be roughly grouped into batch (compute something, then finish) and services (web or infrastructure services like BigTable). Researchers recently examined traces from several Google clusters and observed that while “batch jobs” accounted for 80% of all jobs, “long service jobs” utilize 55-60% of resources.
There are other benefits of multi-tenancy. Being able to run analytics (batch, streaming) and long running services (e.g., web applications) on the same cluster significantly lowers latency3, opening up the possibility for real-time, analytic applications. Bake-offs can be done more effectively as competing tools, versions, and frameworks can be deployed on the same cluster. Data scientists and production engineers leverage the same compute resources, making it easier for teams to work together across the analytic lifecycle. An additional benefit is that data science teams learn to build products and services that factor in efficient utilization and availability.
Mesos, Chronos, and Marathon
Apache Mesos is a popular open source scheduler that originated from UC Berkeley’s AMPlab. Mesos is based on features in modern kernels for resource isolation (cgroups in Linux). It has been in production for a few years at Twitter4, airbnb5, and many other companies – AMPlab simulations showed Mesos comfortably handling clusters with 30K servers.
Data scientists like Mesos because it allows them to easily run frameworks across languages on the same cluster (e.g., Hadoop/HDFS, Spark, GraphLab, pydata). Bake-offs (and upgrades) can be conducted more effectively as multiple frameworks (or versions of the same framework) can run on the same cluster.
An earlier criticism of Mesos was that it wasn’t suitable6 for service jobs (long-running, highly available). Some recent tools have addressed this deficiency. In an earlier post, I wrote about Chronos, a flexible, fault-tolerant, distributed (it’s built on top of Mesos), raw bash scheduler written in Scala. (Chronos is an open source project originated by airbnb.) Released yesterday, Marathon is an open source project from startup Mesosphere. It can be used – in conjunction with HAProxy, for service discovery – to start and stop long running, highly available services. In particular, Marathon7 can initiate any service that can be launched by standard shell.
With Chronos (“Unix cron”) and Marathon (“Unix init.d”) a single cluster can be used to handle many different workloads (batch, request/response services) and frameworks. Both tools8 are accessible through REST APIs or elegant UIs, that vastly simplify the management of complex workflows and cluster computing resources. Mesos (along with Borg and Omega from Google) avert the need for virtualization, which results in large optimizations especially for services on heavily loaded clusters. As Google, Twitter and other companies have learned, moving different workloads and frameworks onto the same collection of machines significantly increases efficiency and ROI.
Related posts:
- Simpler workflow tools enable the rapid deployment of models
- Data scientists tackle the analytic lifecycle
- Near realtime, streaming, and perpetual analytics
(1) For more on schedulers, read the recent paper describing Google’s Omega – a new shared-state scheduler.
(2) From a recent Wired article: “Borg is a way of efficiently parceling work across Google’s vast fleet of computer servers, and according to Wilkes, the system is so effective, it has probably saved Google the cost of building an extra data center. … Rather than building a separate cluster of servers for each software system — one for Google Search, one for Gmail, one for Google Maps, etc. — Google can erect a cluster that does several different types of work at the same time. All this work is divided into tiny tasks, and Borg sends these tasks wherever it can find free computing resources, such as processing power or computer memory or storage space.”
(3) Analytics and apps are co-located in the same cluster. Even for batch applications, being able to lower latency opens up possibilities. A famous example from Sears is worth highlighting: they took a batch process that took over 6 hours in COBOL/JCL and reduced it to to 6 minutes in Hadoop and Pig.
(4) Chris Fry, SVP Engineering at Twitter: “Mesos is the cornerstone of our elastic compute infrastructure – it’s how we build all our new services and is critical for Twitter’s continued success at scale. It’s one of the primary keys to our data center efficiency.”
(5) Mike Curtis, VP Engineering at airbnb: “We think we might be pushing data science in the field of travel more so than anyone has ever done before… a smaller number of engineers can have higher impact through automation on Mesos.”
(6) From the paper describing Google’s Omega: “Mesos works best when tasks are short-lived and relinquish resources frequently.”
(7) Marathon was written by the developers who created Chronos.
(8) Twitter also built a scheduler (Aurora) that runs on top of Mesos.
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata Rx Health Data Conference: September 25-27 | Boston, MA
Strata + Hadoop World: October 28-30 | New York, NY
Strata in London: November 15-17 | London, England