
A series of open source, distributed stream processing frameworks have become essential components in many big data technology stacks. Apache Storm remains the most popular, but promising new tools like Spark Streaming and Apache Samza are going to have their share of users. These tools excel at data processing and are also used for data mining – in many cases users have to write a bit of code1 to do stream mining. The good news is that easy-to-use stream mining libraries will likely emerge in the near future.
High volume data streams (data that arrive continuously) arise in many settings, including IT operations, sensors, and social media. What can one learn by looking at data one piece (or a few pieces) at a time? Can techniques that look at smaller representations of data streams be used to unlock their value? In this post, I’ll briefly summarize a recent overview given by stream mining pioneer Graham Cormode.
Generate Summaries
Massive amounts of data arriving at high velocity pose a challenge to data miners. At the most basic level, stream mining is about generating summaries that can be used to answer fundamental questions:
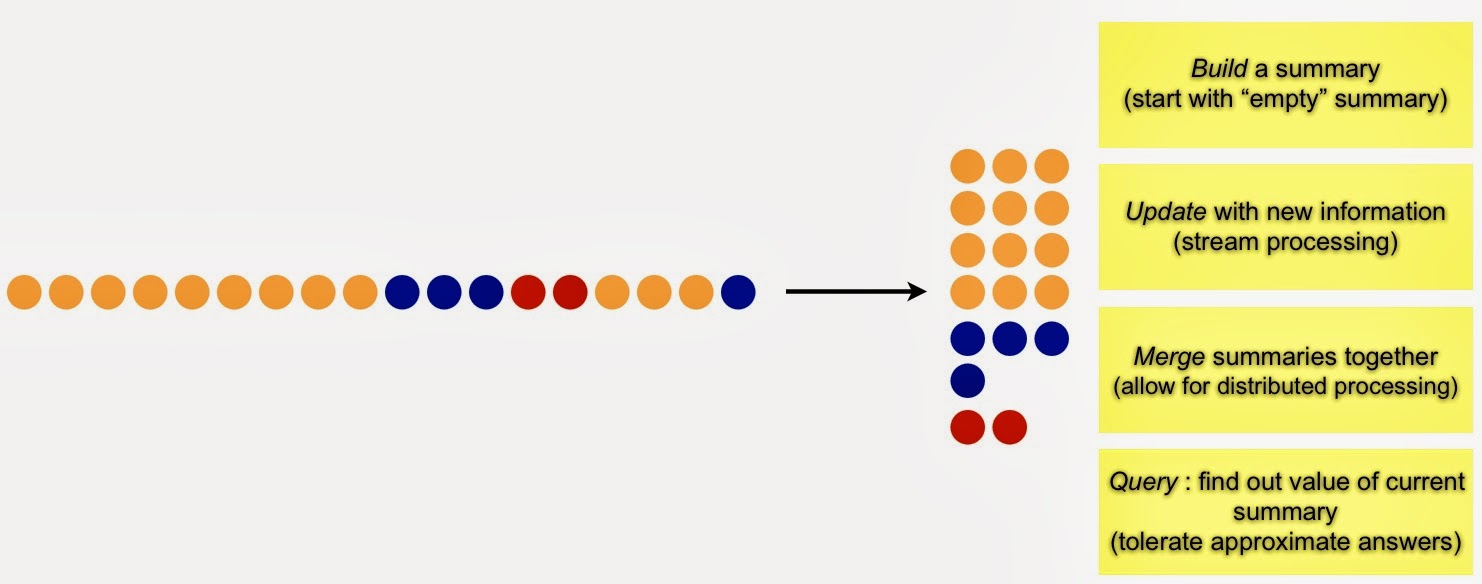
Properly constructed summaries are useful for highlighting emerging patterns, trends, and anomalies. Common summaries (frequency moments in stream mining parlance) include a list of distinct items, recently trending items, heavy hitters (items that have appeared frequently), and the top k (most popular) items.
Approximate Answers
In the streaming context summaries are constantly changing, thus in many2 applications approximate3 answers are acceptable. Sketches are linear transformations that are widely used to generate approximate answers in stream mining. To facilitate fast updates and queries, in practice sketches are described by simple hash4 functions. In recent years researchers have made substantial progress in deriving error estimates to answers generated via sketches.
There are many different sketches, each one tends to be used for a specific set of problems. A prototypical example is the Count-Min sketch (introduced by Cormode and Muthukrishnan) – widely used to identify5 heavy hitters and popular items. Used to encode set membership, Bloom filters are used to detect duplicate or previously viewed items in a data stream. The FM sketch is an old technique used to estimate the number of distinct items (count distinct in SQL). Sketches have also been recently been used in machine-learning (Yahoo! researchers found that hash functions are effective tools for dimension reduction in automatic classification) and for approximate matrix multiplication (solutions to linear regression in “sketch space”).
Sampling from a data stream
Building a random sample from data that’s continuously arriving isn’t straightforward (note that in a stream you “iterate” over the data set only once). Fortunately this problem has been the focus of intense research for many years. First introduced in the 1980s, reservoir sampling is the “canonical” technique for tackling this problem (it’s also useful for data science job interviews). One can try an adaptive strategy, where you draw a uniform sample from data that has been observed so far and modify it as more data arrives. Min-wise sampling is a slightly newer and simpler technique that relies on assigning random tags to incoming items (an added bonus is that it’s easy to compute in a distributed environment).
As noted above, the fundamental task in stream mining is to build, compute, and maintain summaries. A new class of sampling methods (Lp sampling) have emerged that leverage samples from sketches to arrive at optimal estimates for many common summaries (frequency moments).
Data Mining
Beyond simple summaries, advanced algorithms for data mining have drawn interest. In recent years, researchers have worked on extending algorithms for clustering, association rule mining (used to identify correlations in buying patterns), and anomaly detection, to data streams.
Related posts:
- Stream Processing and Mining just got more interesting
- Scalable streaming analytics using a single-server
- Interactive Big Data analysis using approximate answers
(1) I also recently wrote about StreamDrill – a new tool optimized for some of the stream mining tasks covered in this post.
(2) Finance (billing) may require exact answers.
(3) As I noted in an earlier post, the “real-time big data triangle of constraints” posits that you can have only two of the following: volume, velocity, exact.
(4) Think of the use of hash functions as an approach where you “see” all the data even if you can’t “remember” it all.
(5) Yahoo! researchers added a temporal component to the count-min sketch, thus giving users the ability to answer “historical” queries (“give me the count from noon of the 3rd Sunday in March of last year”).
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata + Hadoop World: October 28-30 | New York, NY
Strata in London: November 15-17 | London, England
Strata in Santa Clara: February 11-13 | Santa Clara, CA