
A little over four years ago, I attended the first Crowdsourcing meetup at the offices of Crowdflower (then called Dolores Labs). The crowdsourcing community has grown explosively since that initial gathering, and there are now conference tracks and conferences devoted to this important industry. At the recent CrowdConf1, I found a community of professionals who specialize in managing a wide array of crowdsourcing projects.
Data scientists were early users of crowdsourcing services. I personally am most familiar with a common use case – the use of crowdsourcing to create labeled data sets for training machine-learning models. But as straightforward as it sounds, using crowdsourcing to generate training sets can be tricky – fortunately there are excellent papers and talks on this topic. At the most basic level, before embarking on a crowdsourcing project you should go through a simple checklist (among other things, make sure you have enough scale to justify engaging with a provider).
Beyond building training sets for machine-learning, more recently crowdsourcing is being used to enhance the results of machine-learning models: in active learning, humans2 take care of uncertain cases, models handle the routine ones. The use of ReCAPTCHA to digitize books is an example of this approach. On the flip side, analytics are being used to predict the outcome of crowd-based initiatives: researchers developed models to predict the success of Kickstarter campaigns 4 hours after their launch.
Crowdsourcing providers and workers: signs of maturation
Crowdsourcing providers tend to specialize on specific tasks such as digitizing forms (Microtask), image classification, and more recently I’m seeing services for language translation3 (Gengo and Transfluent). The increasing sophistication in types of tasks is a trend in the industry. CrowdFlower recently surveyed workers (“crowd contributors”) on their platform, some of whom have been contributing for more than two years4:
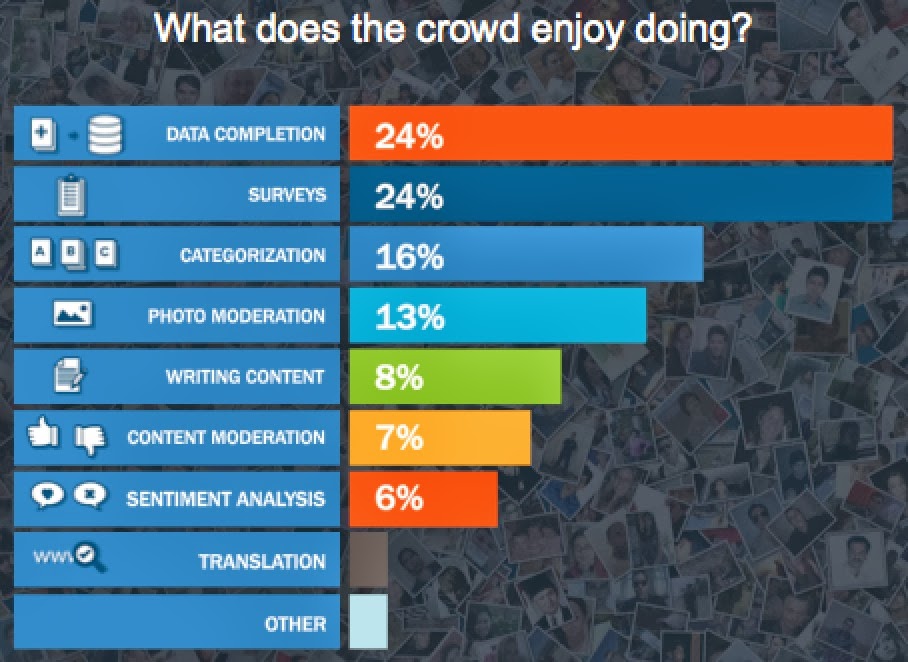
As the industry expands: some challenges
As companies start using crowdsourcing, important decisions are being made based on the input of the crowd. It’s becoming more attractive to subject crowdsourcing to attacks akin to the ones used to influence search engines (e.g., a few workers may maliciously manipulate the outcomes of tasks). Within a data related project all it takes is one worker to expose sensitive information. Researchers from Microsoft have come up with a few suggestions for mitigating the damage from potential adversaries: this includes identifying crowd contributors “willing to go above and beyond to help”, using tools to conceal (sensitive) information while allowing workers to complete required tasks, and tools that can automatically flag sensitive content.
Another group of researchers found that malicious behavior – including attacking the computer systems of teams at the top of the leader board – is common in crowdsourcing competitions. Depending on the project you’re embarking on, diversity can be an issue: all-volunteer site Wikipedia is embarking on a campaign to diversify its army of contributors.
Crowdsourcing resources
The good news is that it’s getting easier for companies to define, initiate, and manage crowdsourcing projects. Nevertheless crowdsourcing projects still require experienced professionals. As companies continue to use crowdsourcing, demand for people who know how to manage projects remains steady. I’m starting to come across people with the title “Director of Crowdsourcing”. Crowdflower has been developing resources to help those charged with managing crowdsourcing projects: the company recently started offering professional training and launched a community site that gathers best practices and stories.
Related posts:
- Mechanical Turk Best Practices
- A startup takes on “the paper problem” with crowdsourcing and machine learning
- Crowdsourcing specific microtasks
(1) CrowdConf is an annual conference organized by CrowdFlower.
(2) But can this approach scale? As Panos Ipeirotis recently noted: “… Google Books and ReCAPTCHA project are really testing the scalability limits of this approach.”
(3) Google Translate is OK, but not quite ready for primetime!
(4) As more people telecommute and/or do contract work, lessons from the crowdsourcing industry may be useful to the larger labor force. At CrowdConf, researcher Vili Lehdonvirta presented the results of in-depth interviews with crowdsourcing workers. He found lack of continuity, lack of understanding of how one’s work relates to the “big picture” and lack of recognition from loved ones as the primary challenges faced by crowdsourcing workers. To cope with these challenges, workers used two main strategies: evasion (downplaying involvement in cloud labor, selective association- “I’m an independent contractor”, pretending the work is actually a game) and embracement (detachment and unpredictability are seen as freedom, favorable comparisons “against the drudgery of normal office work”).
 O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work. Strata + Hadoop World: October 28-30 | New York, NY Strata in London: November 15-17 | London, England Strata in Santa Clara: February 11-13 | Santa Clara, CA
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work. Strata + Hadoop World: October 28-30 | New York, NY Strata in London: November 15-17 | London, England Strata in Santa Clara: February 11-13 | Santa Clara, CA