
When an interesting piece of big data technology gets introduced, early1 adopters tend to focus on technical features and capabilities. Applications get built as companies develop confidence that it’s reliable and that it really scales to large data volumes. That seems to be where Spark is today. With over 90 contributors from 25 companies, it has one of the largest developer communities among big data projects (second only to Hadoop MapReduce).

I recently became an advisor to Databricks (a startup commercializing Spark) and a member of the program committee for the inaugural Spark Summit. As I pored over submissions to Spark’s first community gathering, I learned how companies have come to rely on Spark, Shark, and other components of the Berkeley Data Analytics Stack (BDAS). Spark is at that stage where companies are deploying it, and the upcoming Spark Summit in San Francisco will showcase many real-world applications. These applications cut across many domains including advertising, marketing, finance, and academic/scientific research, but can generally be grouped into the following categories:
Data processing workflows: ETL and Data Wrangling
Many companies rely on a wide variety of data sources for their analytic products. That means cleaning, transforming, and fusing (unstructured) external data with internal data sources. Many companies – particularly startups – use Spark for these types of data processing workflows. There are even companies that have created simple user interfaces that open up batch data processing tasks to non-programmers.
Advanced analytics
From the outset users were attracted to Spark for its speed (compared to Hadoop) and suitability for handling the type of (iterative) computations common in advanced analytics (machine-learning, statistics). Very early on companies and users wrote their own Spark libraries for things like regression, clustering and classification. These tools and libraries have been applied to problems in online advertising and marketing (reinforcement learning), finance, fraud detection, and even scientific research (neuroscience). The good news is that these types of applications are going to get easier to build: Spark developers have responded by developing libraries for machine-learning (MLlib) and graph analytics (GraphX).
Stream Processing
By most accounts Spark and Shark are the most popular components of BDAS. Right behind them are Spark Streaming (realtime processing) and PySpark (Spark’s Python API). One of the main selling points of Spark Streaming is programmer productivity: the same code used for batch processing can, with minor tweaks, be used for realtime computations. This is turning out to be an important feature. I’m coming across many more companies who are using Spark Streaming for realtime data processing. Applications include stream mining, (near) realtime scoring2 of analytic models, recommendations and targeting, personalization, and network optimization. CloudPhysics has been using Spark and Spark Streaming to detect patterns and anomalies in massive amounts of machine data.

Business Intelligence and Visual Analytics
With performance within range of MPP databases, open source SQL-on-Hadoop solutions Shark and Impala are gaining traction3. Many companies start out by using Shark and BlinkDB for interactive SQL analysis. Some startups developed custom, interactive dashboards that are powered in realtime by Shark and Spark. Beyond static reports and query analysis, companies are beginning to use visual analysis tools like Tableau in conjunction with Shark. This opens up terabytes of data to tools that are already popular among business users. More recently, startup ClearStory built a platform that lets users quickly fuse together many data sources and collaboratively produce interactive visualizations. The ClearStory platform uses Spark, Shark, and other BDAS components:
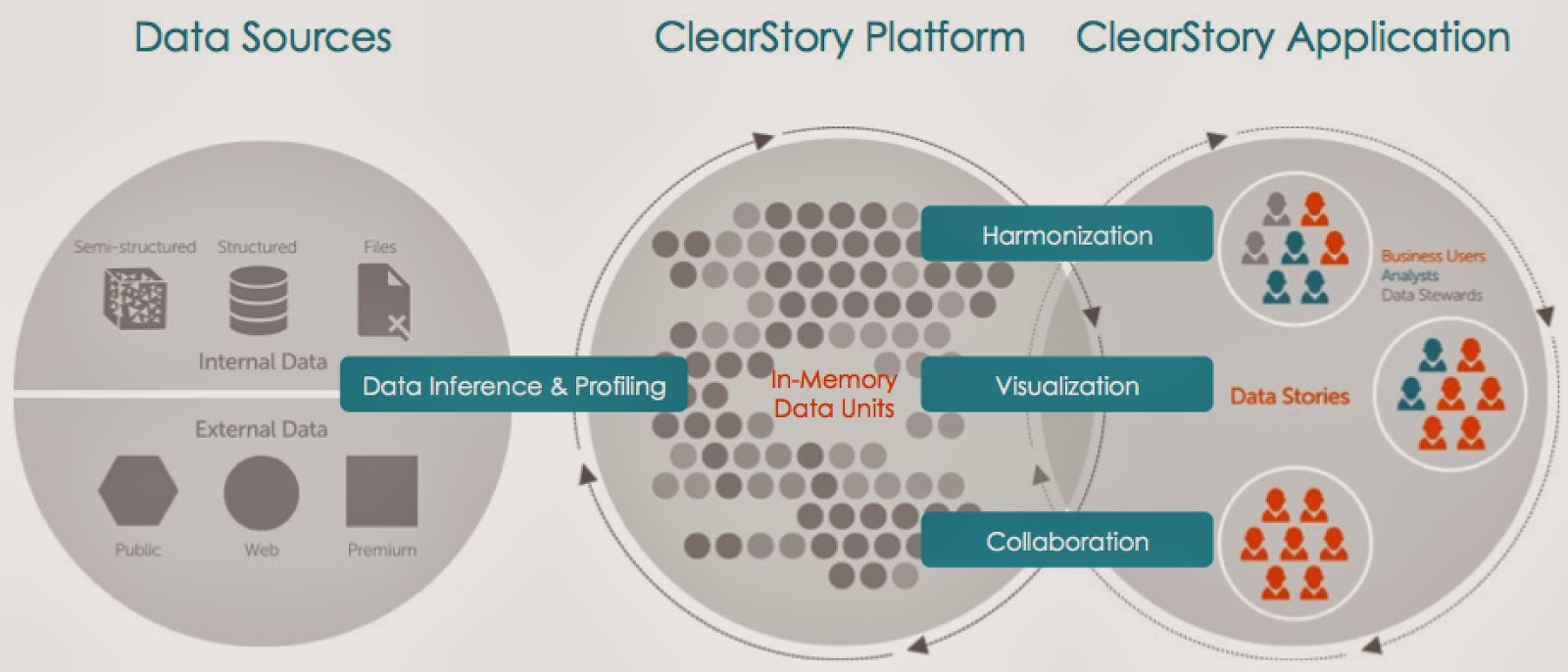
Unified Analytic Platform
Having a single programming model that works across many sets of problems is appealing. Add to that the convenience of having a set of analytic engines (Shark, BlinkDB, MLlib, GraphX) in different stages of maturity. This has allowed some companies to use Spark for applications that cut across different workloads (offline, near realtime, and realtime analytics).
Spark is still young
With adoption growing4 rapidly over the last 6-12 months, it’s easy to forget that Spark is still a relatively young piece of technology (launched in Jan/2010, the current release version is 0.8). Recent enhancements include giving users the ability to kill ad hoc jobs, multi-user5 support, and more efficient data shuffles. Other areas of active development include improved Python support (PySpark) and libraries for advanced analytics (MLlib/GraphX). Along with real-world applications, the Spark Summit will also feature sessions on recent improvements to Spark and Shark, as well as a day packed with tutorials. I hope to see you there!
Update (11/22/2013): Use the code spark-summit-oreilly to get a 10% discount to the summit.
Related content:
- For more on the Berkeley Data Analytics Stack, a day long tutorial on its various components will be held at Strata Santa Clara 2014 (it will include talks and hands-on training)
- Strata posts on the Berkeley Data Analytics Stack
(1) As an example, my first post on Spark reflected my excitement as a user.
(2) Spark has been used in conjunction with PMML.
(3) It will be interesting to see if Facebook’s new open source MPP database (Presto) starts getting adopted. Presto developers plan to integrate BlinkDB.
(4) Some factoids from a recent Databricks blog post: “A final indicator of growth is conferences and events. The AMP Camp training camp at Berkeley was sold out with members from over 100 companies attending … San Francisco user meetup has grown to 1300 members.”
(5) multi-user support for security purposes: A solution has just been merged into the master branch.

O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata in Santa Clara: February 11-13 | Santa Clara, CA