
Here are a few observations based on conversations I had during the just concluded Strata NYC conference.
Interactive query analysis on Hadoop remains a hot area
A recent O’Reilly survey confirmed SQL is an important skill for data scientists. A year after the launch of Impala, quite a few attendees I spoke with remained interested in the progress of SQL-on-Hadoop solutions. A trio from Hortonworks gave an update on recent improvements and changes to Hive1. A sign that Impala is gaining traction, Greg Rahn’s talk on Practical Performance Tuning for Impala was one of the best attended sessions in the conference. Ditto for a sponsored session on Kognitio’s latest features.
Existing SQL-on-Hadoop solutions require that users define a schema – an additional step given that a lot of data is increasingly in key-value or JSON format. In his talk Hadapt co-founder Daniel Abadi highlighted a solution2 that lets users query complex data types (Hadapt reserializes complex data types to speed up joins). I expect other SQL-on-Hadoop solutions to also offer query support for complex data types in the near future.
Empowering business users
With its launch at the conference, ClearStory joins Platfora and Datameer in the business analytics space. Each company builds tools that lets business users wade through large amounts of data, while emphasizing different areas. Platfora is for interactive visual analysis of massive data sets, while Datameer connects to many data sources (not just Hadoop), has started offering analytics, and can run on a laptop or cluster. Built primarily on the Berkeley stack (BDAS), ClearStory’s interesting platform encourages collaboration and simplifies data harmonization (fusing disparate data sources is a common bottleneck for business users). For organizations willing to tag and describe their data sets, Microsoft unveiled a tool that lets users query data using natural language (UK startup NeutrinoBI uses a similar “search interface”).
Approximate Answers
As data sets grow, companies are beginning to learn more about how and when approximation techniques suffice. Sampling was one of the topics that Trifacta’s Sean Kandel discussed in his session on visualization techniques that scale to big data. In a recent post on Stream Mining, I explained the role of approximate answers in realtime analytics. Along those lines, Fangjin Yang and Nelson Ray of Metamarkets described how an open source datastore (Druid) and approximation techniques (HyperLogLog) allow them to wade through massive amounts of realtime ad bidding data. Another popular session was an overview of BlinkDB, the recently released approximate query engine that’s part of BDAS. Facebook will incorporate BlinkDB in their soon to be released open source MPP database (Presto).
ML Startups: Model Building and Deployment
As I discussed in a previous post, model building is just one component of the analytic lifecycle. Machine-learning startups are starting to tackle model deployment: Skytree and 0xdata provide environments and tools that allow data scientists to quickly build and deploy analytic models (Wibidata’s Kiji framework offers the same functionality for Hbase users).
Some attendees I ran into were interested in the progress of another early stage machine-learning startup (GraphLab). Co-founder Carlos Guestrin, gave examples of how GraphLab easily scales popular graph algorithms to massive graphs.
Realtime Analytical Processing
As (near) realtime applications derived from massive data sets become the norm, many companies struggle with how to process and mine3 large data streams. There were a few sessions on these topics, but a couple were especially popular among people I talked with. Jason Dai of Intel4 discussed how they leverage Spark, Spark Streaming, and Shark, to develop tools for complex analytics, including time-series and graph analysis, and machine learning. Jun Fang of Facebook described their software stack for processing data from many different sources:
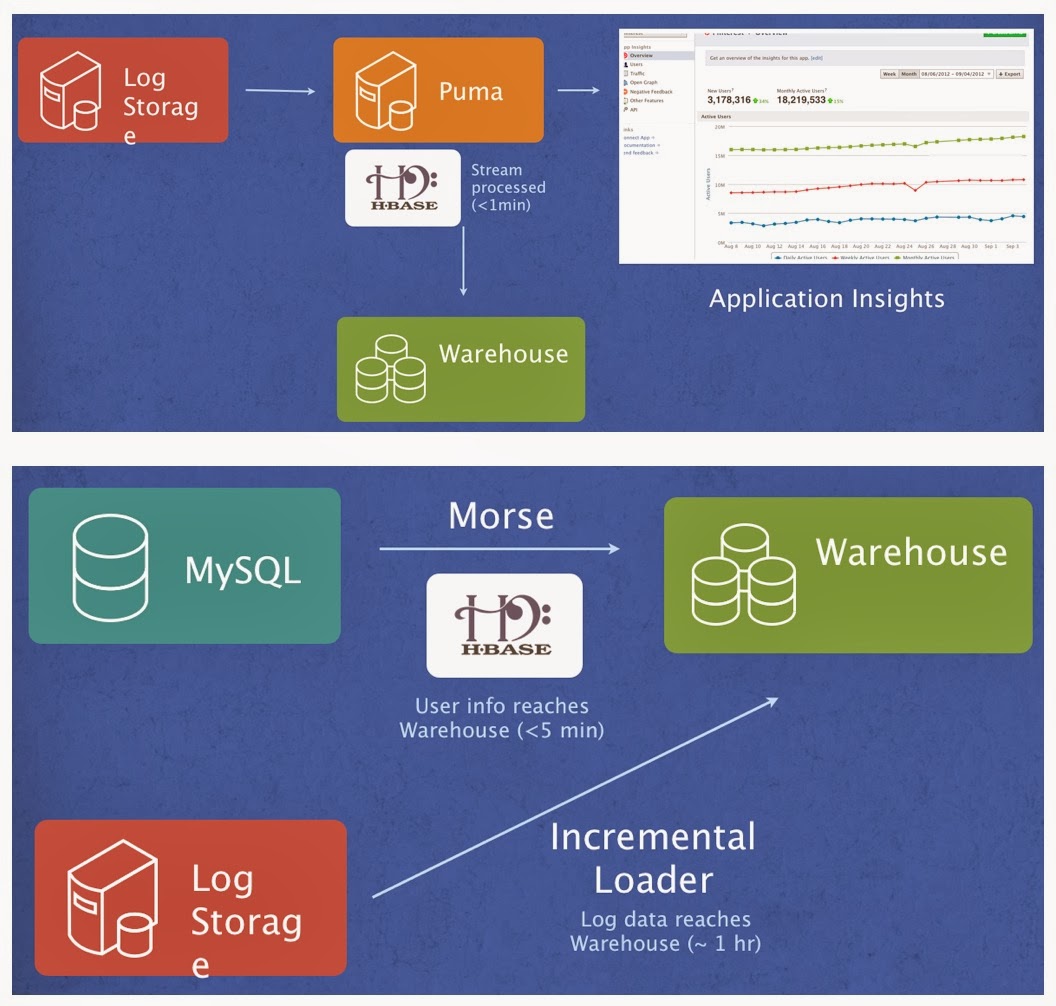
People also enjoyed tracking the progress of tools like HBase (see [1] and [2]), and Tachyon (the BDAS in-memory file system).
Attendees love Hardcore Data Science
Many attendees told me they really enjoyed the Hardcore Data Science track. It was good to have a day devoted to important topics that data scientists don’t normally get to immerse themselves in. Popular sessions covered Adversarial Analytics, Transfer Learning, and Recommendations via anomalous co-occurences. The good news is that we’re again having a day of Hardcore Data Science at Strata Santa Clara 2014!
Related posts:
- Data Science Tools: Fast, easy to use, and scalable (my summary of Strata Santa Clara 2013)
- Interactive Big Data analysis using approximate answers
- Stream Mining essentials
(1) By most accounts, Hive remains one of the most popular tools in the Hadoop ecosystem.
(2) Querying complex data types: Hadapt founders Daniel Abadi and Justin Borgman told me this feature was inspired by conversations with several customers.
(3) As I noted in my recent post on stream mining, approximation techniques are popular.
(4) Intel developers have contributed to Shark and Spark.