
As I talk to people and companies building the next generation of tools for data scientists, collaboration and reproducibility keep popping up. Collaboration is baked into many of the newer tools I’ve seen (including ones that have yet to be released). Reproducibility is a different story. Many data science projects involve a series of interdependent steps, making auditing or reproducing1 them a challenge. How data scientists and engineers reproduce long data workflows depends on the mix of tools they use.
Scripts
The default approach is to create a set of well-documented programs and scripts. Documentation is particularly important if several tools and programming languages are involved in a data science project. It’s worth pointing out that the generation of scripts need not be limited to programmers: some tools that rely on users executing tasks through a GUI also generate scripts for recreating data analysis and processing steps. A recent example is the DataWrangler project, but this goes back to Excel users recording VBA macros.
Workflow tools
Scripts for executing interdependent data science tasks are usually tied together by workflow tools. Tools like Chronos and Ambrose simplify the creation, maintenance, and monitoring of long data workflows. And at least within airbnb, Chronos is heavily used by business analysts:
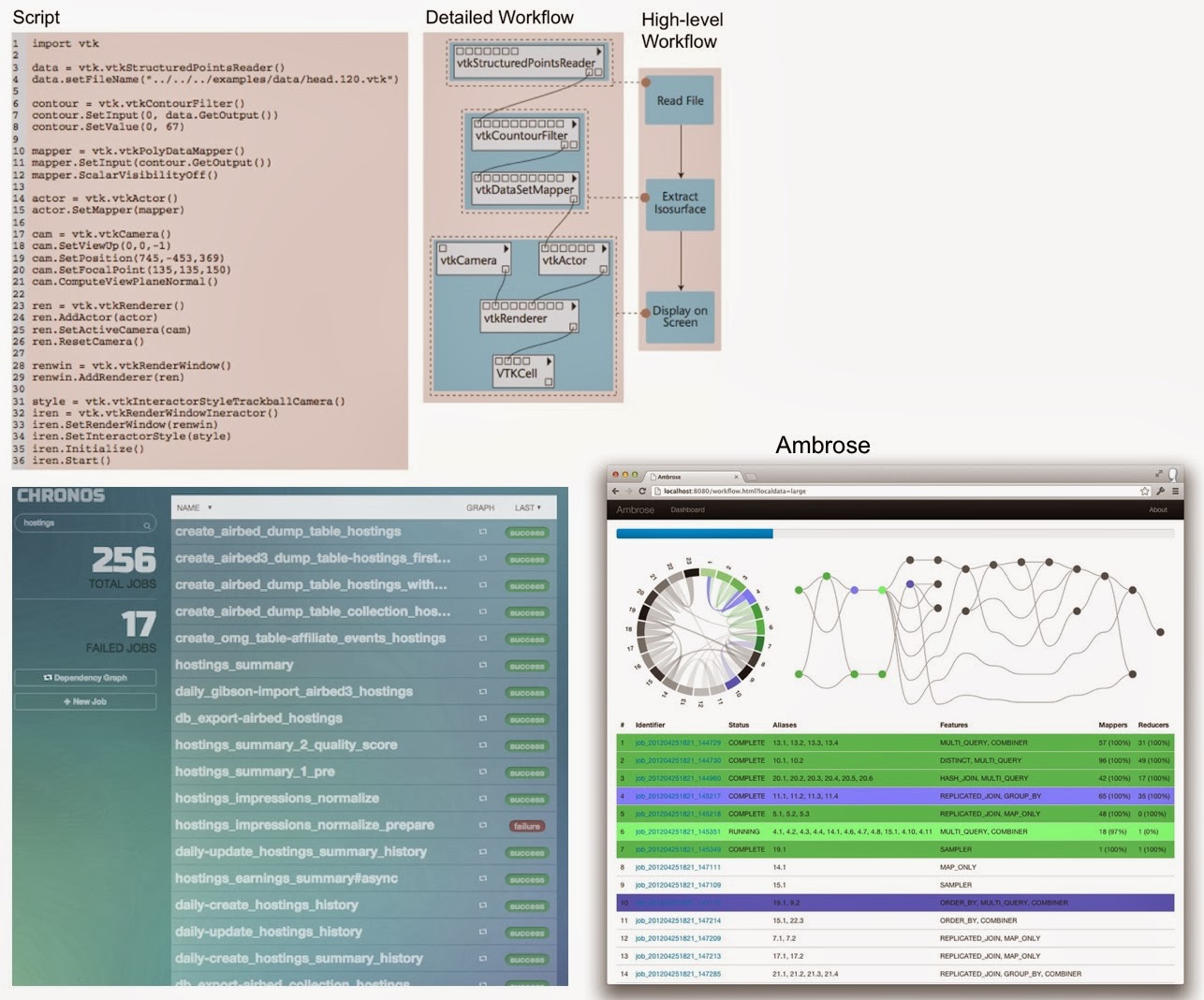
By having users focus on discrete tasks that are available through a UI, there’s no reason why business users can’t stitch together data science projects that involve advanced analysis. Startup Alpine Data Labs uses a “workflow interface” to enable business users to execute, reproduce, and audit complex analytic projects.
Notebooks and Workbooks
Notebooks and workbooks are increasingly2 being used to reproduce, audit, and maintain data science workflows. I wrote about iPython notebooks in an earlier post, and I continue to see and hear about them from many users. Notebooks mix text (documentation), code, and graphics in one file, making them natural tools for maintaining complex data projects. Along the same lines, many tools aimed at business users have some notion of a workbook: a place where users can save their series3 of (visual/data) analysis, data import and wrangling steps. These workbooks can then be viewed and copied by others, and also serve as a place where many users can collaborate.
What next
Notebooks, workbooks, and workflow tools are the most popular methods for managing complex data projects. There are bits that I like from each of them. Notebooks are cool because narrative and documentation are extremely easy to incorporate (after all the original Mathematica notebooks were used for instructional purposes). Workflow tools can be used to peruse data projects comprised of many steps (nowadays they usually come with a zoomable DAG viewer). Chronos has tools designed to make it easy to manage production workflows (scheduling, retries, dependencies). Many workbooks (associated with commercial software products) have collaboration, security, and sharing built-in.
Beyond a mashup of features from these three popular approaches, are there completely different ways of thinking about reproducibility, lineage, sharing, and collaboration in the data science and engineering context? I certainly hope that there are startups rethinking these problems. The good news is that academic researchers are developing tools for lineage and provenance for computational tasks. So maybe a new wave of startups and open source projects are on the way.
Related content:
- The companies and open source communities behind some of the most interesting data science tools will be on site at Strata Santa Clara 2014
- Data Science tools: Are you “all in” or do you “mix and match”?
- Simpler workflow tools enable the rapid deployment of models
(1) reproducibility includes redoing an analysis at a latter date, or copying and forking portions of a long data science project.
(2) I would even venture to guess that notebooks and workbooks are the most popular means on handling data science workflows.
(3) In essence a workbook is a place where users save all the data analysis and processing they’ve performed.

O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata in Santa Clara: February 11-13 | Santa Clara, CA