
An important reason why pydata tools and Spark appeal to data scientists is that they both cover many data science tasks and workloads (Spark users can move seamlessly between batch and streaming). Being able to use the same programming style and syntax for workflows that span a variety of tasks is a huge productivity boost. In the case of Spark (and Hadoop), the emergence of a variety of scalable analytic engines have made distributed computing applications much easier to build.
Delite: a framework for embedded, parallel, and high-performance DSLs
Another way to boost productivity is to use a family of high-performance languages that cover many data science tasks. Ideally you want languages that allow programmers to focus on applications (not on low-level details of parallel programming) and that can run efficiently on different machines and architectures1 (CPU, GPU). And just like pydata and Spark, syntax and context-switching shouldn’t get in the way of tackling complex data science workflows.
The Delite framework from Stanford’s Pervasive Parallelism Lab (PPL) has been used to produce a family of high-performance domain specific languages (DSLs) that target different data analysis tasks. DSLs are programming languages2 with restricted expressiveness (for a particular domain) and tend to be high-level in nature (they are often declarative and deterministic). Delite is a compiler and runtime infrastructure that allows language designers to use aggressive, domain-specific optimizations to deliver high-performance DSLs. Using Delite, the team at Stanford produced DSLs embedded in a functional language (Scala) with performance results comparable to hand-optimized implementations (e.g. MATLAB, LINQ) across different domains.
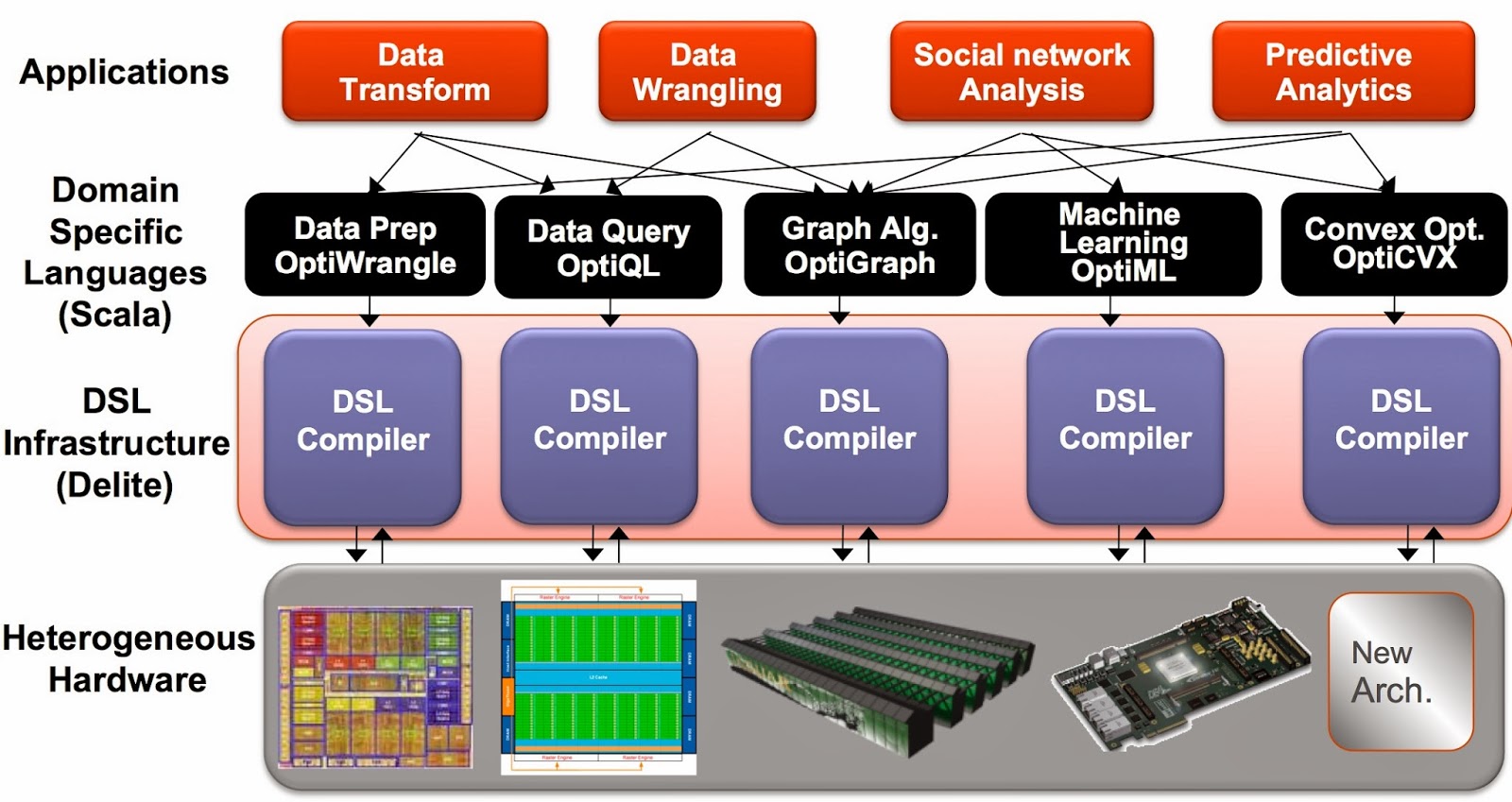
It’s about to get easier to use and deploy these DSLs
Besides speed3, another reason to be excited about these DSLs is that the team behind them has been focusing on usability and ease of deployment. Over the next two months, PPL will release tools that make it simple to deploy and run these DSLs across clusters4. This means that data scientists will be able to easily use these high-performance DSLs for a variety of tasks including data wrangling (OptiWrangle), interactive query analysis (OptiQL), machine-learning (OptiML), graph analytics (OptiGraph), and optimization (OptiCVX).
While each of these DSLs is embedded in Scala, users don’t need to know much Scala in order to be productive in them. Their simple and intuitive syntax make it seamless to jump from one DSL to another in the course of a long data science workflow5 (e.g., OptiQL is SQL embedded in Scala ; OptiML combines “functional operators” with MATLAB-like syntax for doing matrix math):
/* OptiML example: k-means clustering */
untilconverged (centroids, tol){ centroid =>
// assign each sample to the closest centroid
val clusters = samples.groupRowsBy { sample =>
// calculate distances to current centroids
val allDistances = centroids mapRows { centroid =>
dist(sample, centroid)
}
allDistances.minIndex
}
// move each cluster centroid to the
// mean of the points assigned to it
val newCentroids = clusters.map(e => e.sum / e.length)
newCentroids
}
In addition, the team behind Delite is building Python6 wrappers for each of these DSLs, and at some point data scientists will be able to use them within IPython.
To learn more about how these DSLs can be used to solve challenging data problems, come to Chris Re’s talk at Strata Santa Clara 2014.
Related content:
- Data Science tools: Are you “all in” or do you “mix and match”?
- Reproducing Data Projects
- It’s getting easier to build Big Data applications
- Data Analysis: Just one component of the Data Science workflow
(0) Big thanks to Kunle Olukotun for walking me through the details and history of Delite, and for sharing some of the team’s future plans.
(1) Soon to include FGPAs! According to Kunle, several teams who work in Deep Learning are very interested in FPGAs. Kunle also uses the term “forward scalability” to describe DSLs and runtimes that evolve and take advantage of new hardware features.
(2) Well-known DSLs include MATLAB, TeX, and OpenGL.
(3) According to the Delite team’s benchmarks, their DSLs run much faster than Spark. See Figures 3 and 4 in the recent paper “Forge: Generating a High Performance DSL Implementation from a Declarative Specification”. For additional background on Delite, see Kunle Olukotun’s ICFP 2012 keynote talk.
(4) Since many data analytics clusters run Hadoop and HDFS, the team will release tools to make it easy for users to analyze data in HDFS and run Delite DSLs on top of YARN.
(5) The Delite team have tools and techniques for piecing together these DSLs across long data science workflows (“DSL Composability”).
(6) Python and Scala are certainly popular among data types! I recently wrote about the popularity of Python and Scala among data scientists and engineers in the SF Bay Area.
![]() O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
O’Reilly Strata Conference — Strata brings together the leading minds in data science and big data — decision makers and practitioners driving the future of their businesses and technologies. Get the skills, tools, and strategies you need to make data work.
Strata in Santa Clara: February 11-13 | Santa Clara, CA