
Data scientists were among the earliest and most enthusiastic users of crowdsourcing services. Lukas Biewald noted in a recent talk that one of the reasons he started CrowdFlower was that as a data scientist he got frustrated with having to create training sets for many of the problems he faced. More recently, companies have been experimenting with active learning (humans1 take care of uncertain cases, models handle the routine ones). Along those lines, Adam Marcus described in detail how Locu uses Crowdsourcing services to perform structured extraction (converting semi/unstructured data into structured data).
Another area where crowdsourcing is popping up is feature engineering and feature discovery. Experienced data scientists will attest that generating features is as (if not more) important than choice of algorithm. Startup CrowdAnalytix uses public/open data sets to help companies enhance their analytic models. The company has access to several thousand data scientists spread across 50 countries and counts a major social network among its customers. Its current focus is on providing “enterprise risk quantification services to Fortune 1000 companies”.
CrowdAnalytix breaks up projects in two phases: feature engineering and modeling. During the feature engineering phase, data scientists are presented with a problem (independent variable(s)) and are asked to propose features (predictors) and brief explanations for why they might prove useful. A panel of judges evaluate2 features based on the accompanying evidence and explanations. Typically 100+ teams enter this phase of the project, and 30+ teams propose reasonable features.
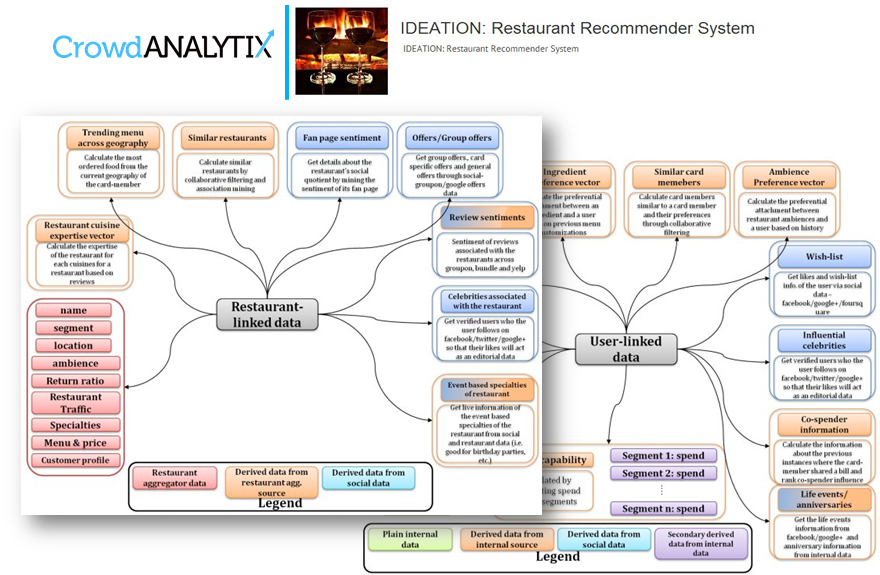
The modeling phase is a traditional machine-learning competition (entries compete on standard quantitative metrics), using data sets that incorporate features culled from the earlier phase. More than algorithms3, companies gain access to models that incorporate ideas generated by teams of data scientists. CrowdAnalytix enriches data sets with features proposed by teams of data scientists, surfacing (potentially unconventional) ideas that may prove useful for their models.
Related Content:
- Sessions at Strata 2014: “How I Learned to Stop Worrying and Love the Crowd” (by Adam Marcus) and “Organizing Big Data with the Crowd” (by Lukas Biewald)
- The emergence of Crowdsourcing specialists
- Strata 2014 Complete Video Compilation
(1) The key question that I pointed out in my earlier post was: can this approach scale? Panos Ipeirotis recently noted: “… Google Books and ReCAPTCHA project are really testing the scalability limits of this approach.”
(2) Judging is subjective, and is based on the “explanation and rationale” that accompany each feature.
(3) In the end, many teams who enter machine-learning competitions coalesce around a few algorithms (Random Forest is a favorite). Winners tend to distinguish themselves through feature engineering.