
Here are a few more observations based on conversations I had during the just concluded Strata Santa Clara conference.
Interface languages: Python, R, SQL (and Scala)
This is a great time to be a data scientist or data engineer who relies on Python or R. For starters there are developer tools that simplify setup, package installation, and provide user interfaces designed to boost productivity (RStudio, Continuum, Enthought, Sense).
Increasingly, Python and R users can write the same code and run it against many different execution1 engines. Over time the interface languages will remain constant but the execution engines will evolve or even get replaced. Specifically there are now many tools that target Python and R users interested in implementations of algorithms that scale to large data sets (e.g., GraphLab, wise.io, Adatao, H20, Skytree, Revolution R). Interfaces for popular engines like Hadoop and Apache Spark are also available – PySpark users can access algorithms in MLlib, SparkR users can use existing R packages.
In addition many of these new frameworks go out of their way to ease the transition for Python and R users. wise.io “… bindings follow the Scikit-Learn conventions”, and as I noted in a recent post, with SFrames and Notebooks GraphLab, Inc. built components2 that are easy for Python users to learn.
I’ve written about the many tools3 that allow SQL users to access and interact with data stored in HDFS and other distributed data stores. But SQL’s influence can be found in many other tools. As a SQL user, I’m happy to see its syntax appear in dplyr – a library for accessing and wrangling R data frames. Similarly, Python users benefit from familiar constructs in Pandas and SFrames.
I’d be remiss if I didn’t put in a plug for Scala. Delite, Scalding, Summingbird, and particularly Apache Spark (the execution engine for a variety of analytic4 tools) puts Scala in the conversation.
Feature Discovery and Feature Engineering
Chris Re reminded attendees5 of the adage, “features are more important than algorithms”. The rise of data wrangling tools (and the addition of data wrangling capabilities in existing tools) bodes well for feature discovery, particularly as business users and domain experts become increasingly empowered to take on many data analysis tasks.
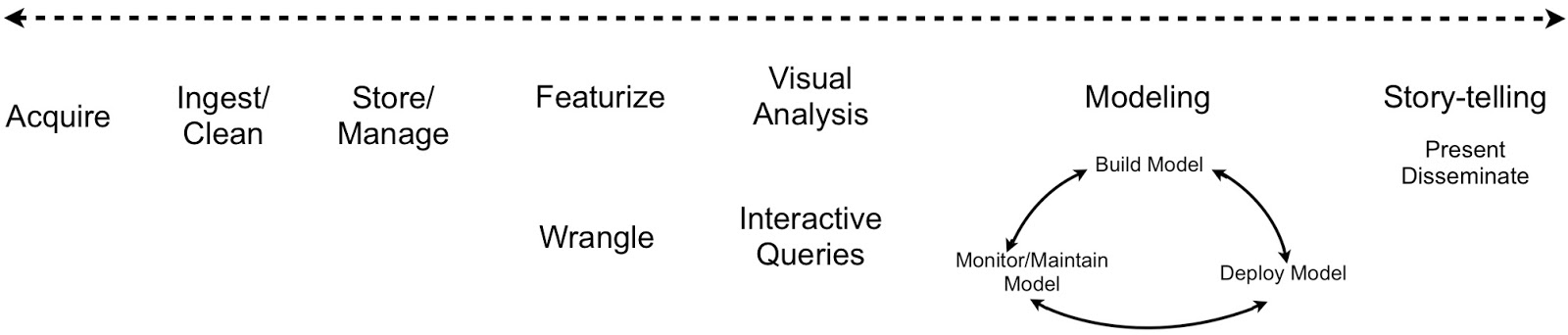
It’s easier to “discover” features with tools that have broad coverage of the data science workflow. Tools that target business users are beginning to cover data ingestion, data wrangling, and analytics (examples include Alpine, Alteryx, Datameer). Business users can work in concert with data scientists to enrich existing models with features generated from non-traditional data sources.
The same dynamic is playing out for tools that target data scientists and programmers: tools (like GraphLab, H20, Revolution R) are racing to broaden their coverage of the data science workflow. One of the main reasons why Spark is so popular is that it has a simple programming model that covers many of the tasks needed for constructing large-scale, data analysis pipelines.
Related Content:
- Strata Speaker Slides
- Strata 2014 Complete Video Compilation
- Bridging the gap between research and implementation
(0) Full disclosure: I am an advisor to Databricks – a startup commercializing Apache Spark.
(1) As DataPad founder Wes McKinney noted in his Strata talk, it’s useful to “… abstract away the execution model (where possible)”
(2) SFrames and GraphLab notebooks should be easy for users of Pandas and IPython notebooks to learn. For more on these tools, attend the upcoming GraphLab conference in SF.
(3) Here’s a recent benchmark from UC Berekeley’s AMP Lab.
(4) Shark (interactive analysis), GraphX (graph analytics), MLlib (machine-learning), Spark Streaming (stream mining), not to mention Adatao. Learn more about these tools at the upcoming Spark Summit in SF.
(5) He then proceeded to make the case for how DeepDive could help unearth new and useful features.