
 In a recent O’Reilly webcast, “Crowdsourcing at GoDaddy: How I Learned to Stop Worrying and Love the Crowd,” Adam Marcus explains how to mitigate common challenges of managing crowd workers, how to make the most of human-in-the-loop machine learning, and how to establish effective and mutually rewarding relationships with workers. Marcus is the director of data on the Locu team at GoDaddy, where the “Get Found” service provides businesses with a central platform for managing their online presence and content.
In a recent O’Reilly webcast, “Crowdsourcing at GoDaddy: How I Learned to Stop Worrying and Love the Crowd,” Adam Marcus explains how to mitigate common challenges of managing crowd workers, how to make the most of human-in-the-loop machine learning, and how to establish effective and mutually rewarding relationships with workers. Marcus is the director of data on the Locu team at GoDaddy, where the “Get Found” service provides businesses with a central platform for managing their online presence and content.
In the webcast, Marcus uses practical examples from his experience at GoDaddy to reveal helpful methods for how to:
- Offset the inevitability of wrong answers from the crowd
- Develop and train workers through a peer-review system
- Build a hierarchy of trusted workers
- Make crowd work inspiring and enable upward mobility
What to do when humans get it wrong
It turns out there is a simple way to offset human error: redundantly ask people the same questions. Marcus explains that when you ask five different people the same question, there are some creative ways to combine their responses, and use a majority vote. One method is to use Project Troia to combine worker’s answers; another is to use a service such as CrowdFlower, where you can indicate how much redundancy you want to build into a task in order to produce high-quality data. While Project Troia and CrowdFlower can do the heavy lifting, even doing something simple like taking a majority vote for the most common answer across workers can reduce error rates quickly.

Slide courtesy of Adam Marcus.
Use human-sourced data to train your robots
Integrating data from crowd workers is an important way to train and improve your algorithm — a critical component of the active learning process. In fact, Marcus points out that if Locu turned to humans for all its labeling needs, without automating any of the decision-making with a classifier, it would cost approximately $50 billion to match just one million listings. Instead, the Locu team uses data from the crowd to train its classifiers, and according to Marcus, has produced a venue-matching algorithm that now produces higher accuracy than the crowd.
Train, and re-train workers
At Locu, crowd workers help with two types of tasks: entity resolution (e.g. matching business listings) and data entry (e.g. converting unstructured data, such as menu items, into structured data).
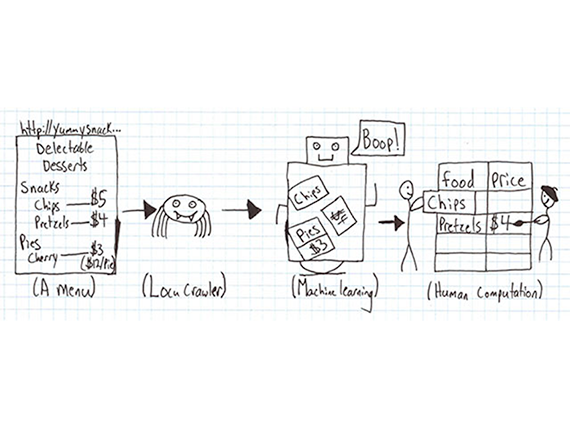
Slide courtesy of Adam Marcus.
Marcus explains that there’s a critical difference in how you approach these two types of tasks: unlike with entity resolution, you don’t want to use redundancy for data entry as a way to ensure quality. Instead, the Locu team has built a hierarchical system, where workers train each other via peer-review. Workers who produce the best quality work are awarded with “reviewer” or even “manager” status. These trusted workers review contributions from new workers and provide feedback; reviewers even review the work of other reviewers to get a bigger sense of how everyone is doing — this creates a peer-review training loop that helps improve and maintain accuracy.
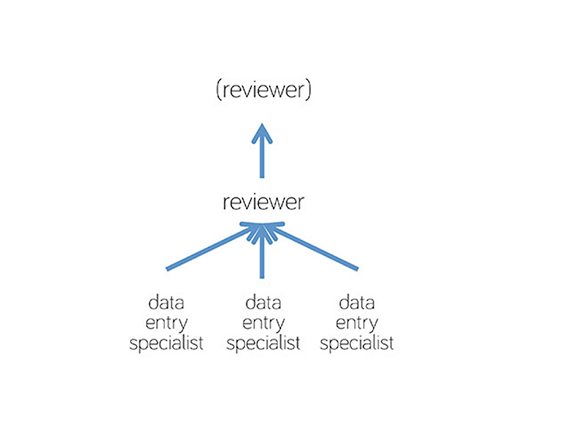
Slide courtesy of Adam Marcus.
Moving beyond microtasks: How to build effective relationships with the crowd
The flip side of crowd work, Marcus notes, is that you’re hiring people to complete uninspiring work — work so simple that a robot could do it. To address this, the Locu team strives to establish mutually beneficial, long-term relationships with workers. Using Elance/oDesk, Locu establishes contracts with workers; gets to know them; and over time, rewards high-performing workers with higher order tasks and more work. Today, Locu has benefitted from more than 500,000 hours of crowd work from Elance/oDesk, and according to Marcus, the median length of their relationships with crowd workers is greater than two years.
You can watch the free webcast, in its original format, here.
This post is part of our exploration into active learning, and the larger theme of Big Data and Artificial Intelligence: Intelligence Matters, as we continue to investigate Big Data’s Big Ideas. In our latest free report, Real-World Active Learning: Applications and Strategies for Human-in-the-Loop Machine Learning, we examine the relatively new field of “active learning,” where practical applications are proving the efficiency of combining human and machine intelligence.