

I rarely work with social network data, but I’m familiar with the standard problems confronting data scientists who work in this area. These include questions pertaining to network structure, viral content, and the dynamics of information cascades.
At last year’s Strata + Hadoop World NYC, Cornell Professor and Nevanlinna Prize Winner Jon Kleinberg walked the audience through a series of examples from social network analysis, looking at the content of shared photos and text, as well as the structures of the networks. It was a truly memorable presentation from one of the foremost experts in network analysis. Each of the problems he discussed would be of interest to marketing professionals, and the analytic techniques he described were accessible to many data scientists. What struck me is that while these topics are easy to describe, framing the right question requires quite a bit of experience with the underlying data.
Predicting whether an information cascade will double in size
Can you predict if a piece of information (say a photo) will be shared only a few times or hundreds (if not thousands) of times? Large cascades are very rare, making the task of predicting eventual size difficult. You either default to a pathological answer (after all most pieces of information are shared only once), or you create a balanced data set (comprised of an equal number of small and large cascades) and end up solving an artificial task.
Thinking of a social network as an information transport layer, Kleinberg and his colleagues instead set out to track the evolution of cascades. In the process, they framed an interesting balanced algorithmic prediction problem: given a cascade of size k, predict whether it will reach size 2k (it turns out 2k is roughly the median size of a cascade conditional on whether it reaches size k).
Their resulting predictive model used many features, ranging from content (was text overlaid on a photo), the root node (degree), temporal factors (time to reach size k, acceleration), and many others. To no surprise, they found that the temporal features are the most predictive — cascades that reach a certain size very quickly are likely to keep growing in size. But they also found feature redundancy: removing all the temporal features still led to models that produced decent results.
The role of content in cascades: characterizing “memorable” quotes
What role does content have in the formation of these cascades? Social networks are difficult environments to study such questions, as they make it hard to assess what caused a piece of content to go viral (was it the content itself, or another factor, like the person who shared it). What would be nice is to have a laboratory where viral content is being generated and is paired adjacently with less viral content.
By examining roughly 1,000 open source movie scripts, Kleinberg and his collaborators found an ideal setting. Scripts contain viral (“memorable”) quotes next to lines — spoken by the same character in a film — that didn’t become famous.
Is there something in the text that one can use to predict whether or not it will become memorable? They measured the memorability of a quote using search engines (Google/Bing) and IMDB. As a baseline, one can build a simple bag-of-words classifier (memorable/non-memorable) using the resulting term vectors. The team also considered features like distinctiveness of text (unigram, bigram, trigram frequency from the AP newswire) and “part-of-speech” composition.
These latter factors (distinctiveness and part of speech) turn out to be important in predicting whether a piece of text becomes memorable. Kleinberg and his collaborators found that memorable quotes tended to be comprised of “… a sequence of unusual words built on a scaffolding of common parts-of-speech patterns.” They subsequently found that some of their findings extended to comment threads in social networks: threads are longer when text is more distinctive.
Relying solely on network structure to detect significant relationships
Given a person’s network neighborhood, can we identify their most significant social ties? A natural starting point is to use an embeddedness metric for an edge e (defined to be the number of mutual friends shared by endpoints of e). It’s natural to think that if an edge is highly embedded, it’s likely to be a stronger tie.
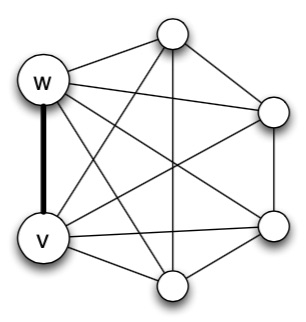
Edge between v and w has embeddedness 4, because they have 4 mutual friends. Source: Jon Kleinberg.
Given a user v, can we rely only on network structure to detect his/her significant other (“relationship partner”)? It turns out, using embeddedness alone to rank a person’s friends fares poorly at this task. Embeddedness finds nodes from the largest clusters in a person’s network graph, and in practice, this is frequently a person’s co-workers.
Using a large sample of Facebook users, Lars Backstrom and Jon Kleinberg studied other metrics that might be useful for detecting strong social ties. They considered activity-based metrics such as number of photos in which v and w are both tagged, and number of times v viewed w’s profile in last 90 days. By visually studying network diagrams over an extended period of time, they noticed a pattern that led to a metric that can be derived purely from network structure. Dispersion between two nodes is a measure of the distance between their mutual friends, if the edge between them did not exist.
Backstrom and Kleinberg devised the following algorithmic problem: (1) for each user v, rank all friends w by competing metrics (embeddedness, dispersion, and activity-based metrics), and (2) determine for what fraction of users is the top-ranked friend the “relationship partner.” Dispersion performed much better than embeddedness across all categories. And for married couples, dispersion outperformed the activity-based metrics described above:
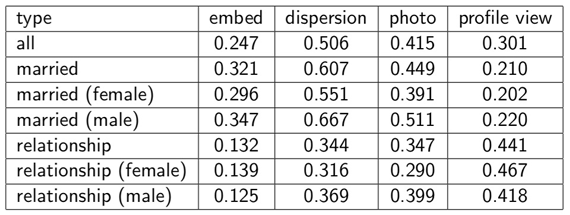
Fraction of users for which the top-ranked friend is the true “relationship partner.” (“photo” = number of photos in which v and w are both tagged; “profile view” = # of times v viewed w’s profile in last 90 days). Source: Jon Kleinberg.
The first row in the table above illustrates the power of having the correct algorithm. With the proper metric (dispersion), structural considerations outperform activity-based measures in detecting significant relationships.
These three examples provide a glimpse into the many interesting studies being conducted to understand how information, human audiences, and data come to interact. We’ll be covering related developments in future posts.
To view Jon Kleinberg’s talk, sign-up for a free trial of Safari Books Online. Kleinberg gave his presentation at Hardcore Data Science day at Strata+Hadoop World in NYC. Join me and Ben Recht as we host another amazing Hardcore Data Science lineup in San Jose on February 18, 2015, at Strata + Hadoop World, San Jose.
Cropped image on article and category pages by Joel Ormsby on Flickr, used under a Creative Commons license.