

A strong user community is essential to releasing the full potential of an open source project, and this influence is particularly important now for the newly developed Apache Drill project. Drill is a highly scalable SQL query engine for interactive access to a wide range of big data sources and formats. Some of the ways users have an impact are an expected part of the development process: by trying the software and reporting their experiences and use cases, users in the Drill community provide valuable feedback to developers as well as raise awareness with a larger audience of what this big data tool has to offer.
This advantage was especially important with early versions of the software; users have helped development of Drill from early days by reporting bugs and praising features that they like. And now, as Drill is reaching maturity and refinement, users likely will also provide additional innovations: experimenting with Drill in their own projects, they may find new ways to use it that had not occurred to the developers.
Drill’s flexibility and extensibility lend themselves to innovation, but there’s also a natural tendency for this type of change because the big data and Hadoop landscape also are evolving quickly. In the case of Drill, we’re seeing the “unexpectedness benefit” of openness: the community gets out ahead of the leadership in use cases and technological change.
The first big Apache Drill design meeting in September 2012 in San Jose set the tone of openness and inclusion. This was an open meeting, organized by Drill co-founder Tomer Shiran and Drill mentor Ted Dunning, and sponsored by MapR Technologies through the Bay Area Apache Drill User Group. More than 60 people attended in person, and Webex connected a larger, international audience. I recall that in addition to speaker-led presentations and discussion, long strips of paper were mounted around the room for participants to write on during breaks in order to provide ideas or offer specific ways they might want to be involved. Practical steps like this surfaced good ideas immediately, and signaled openness for future ones.
A key design point discussed at that first meeting was whether Drill would support standard ANSI SQL syntax or use a SQL-like approach, like Apache Hive. Julian Hyde, lead developer for Apache Calcite, made a good argument in favor of standard SQL. Julien LeDem, co-founder of Apache Parquet, discussed the role of the Parquet data format and how it might fit with Drill. (Parquet is a relatively new column-based complex format that is very efficient.) In both cases, the breadth of participation led to decisions in favor of accessibility and extensibility.
The broad base of users brought many perspectives that wouldn’t have been realized with a more closely held project. Many of the committers and contributors to Drill have come from MapR, but contributors have also come from a number of other organizations, including Pentaho, Hortonworks, Microsoft, Twitter, Simba, Concurrent, Intuit, LinkedIn, Drawn to Scale, Cisco, and the University of Wisconsin-Madison. Additional feedback from the business community and early users has come from people at many other organizations as well.
Fast-forward to Drill today: Based on early and broad user feedback, Drill has been developed to offer standard SQL query syntax with flexibility to deal with multiple data formats, including Parquet and JSON (even when nested) and with schema-on-the-fly but without sacrificing performance. Not only are queries fast, but Drill’s ability to deal with data in situ can greatly shorten the time required before a query is ready to execute. This flexibility and agility enable the user to approach data in an interactive way, even at large scale: the results of an initial query can spur design of the next query quickly, without a prohibitive requirement for extensive data preparation, as depicted in Figure 1.
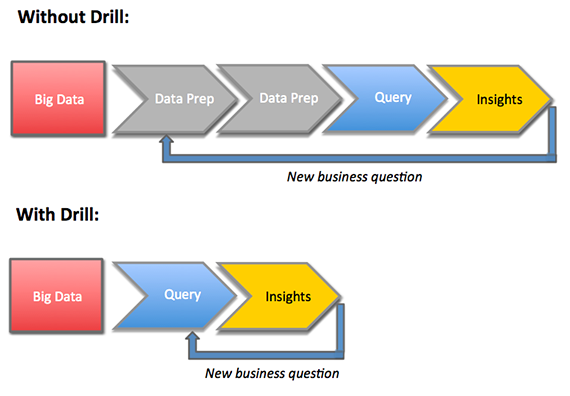
Figure 1: Drill provides improved time-to-value and greater agility. Image courtesy of Ellen Friedman.
These capabilities facilitate the variety of uses and architectures Drill is now deployed for. During a recent O’Reilly webinar, Piyush Bhargava, Cisco IT engineer, commented that Drill’s combination of flexibility and performance is what is needed in a big data SQL query engine for enterprise use cases. People want to continue to use familiar BI tools, but also to be able to connect efficiently with very large data sets. Jacques Nadeau, a leading architect of Drill and also on the webinar panel, pointed out that one reason Drill can manage this combination of flexibility and performance is that it was designed from the start to have these capabilities. He offered an analogy to trying to carry a heavy load of soil with a car: you may be able to do it by attaching a trailer to extend the automobile’s capabilities, but it’s not the same as having a made-for-purpose pickup truck for hauling. Other SQL-on-Hadoop tools have, over time, added features that can help them carry out many of the tasks that Drill can handle, but often there is a trade-off that diminishes one or more of these capabilities (performance, flexibility, and in situ data access). Drill was designed to have all these capabilities together.
Putting these advantages to work
Querying extremely large data sets: The scale may surprise even those who have already been working in the big data world. For example, one MapR customer reports they already are using Drill in production to successfully deal with hundreds of billions of rows of input data where intermediate query steps exploded data to 1015 rows.
Correlation and aggregation of separate data sources: An analytics service company is already using Drill in production to help with their goal of correlating and eventually aggregating very large amounts of customer data from different data streams. They’re employing complex multi-step SQL queries to accomplish these goals at a scale that proved impossible to support with other systems. They have chosen to take advantage of the efficiency of the Parquet data format in the output of their initial query step. Here’s where Drill’s flexibility and performance pay off: Drill lets them further query this Parquet data very rapidly despite its complexity and huge volume.
Rapid response to customer engagement: Telecoms, streaming video companies, and other service providers often make use of log data in JSON or similar data formats, and their marketing goals require the ability for rapid interactive analysis of their data. Apache Drill provides the flexibility and rapid time-to-value needed to meet these goals with the large volume of semi-structured data often found in these situations. This ability for rapid response can help a company offer targeted marketing that reduces churn by improving customer loyalty.
Handling changing schema: Some telecoms make a business of providing reports to other communications-related companies based on network data relating to cell tower activity and usage. It’s very difficult to process this data over time because of the need to update schema in response to changes in network protocols. Steve Wooledge, VP of product marketing at MapR, reported in the O’Reilly webinar about a telecom that is putting Drill to use in a customer-facing example. The customer uses Drill to bypass the need for extensive ETL and instead to query log files directly, thus handling schema updates easily. This is a real-world example of realizing an improved time-to-value.
Impact of the Drill community
The preceding examples that show how people already use Drill are only a sampling of the possibilities. As more users try Drill and report on their experiences, the community in turn benefits from hearing about a wider range of use cases. For instance, from early on, there has been feedback from the business community expressing a desire to be able to use familiar BI tools. That input found fertile ground: George Chow and the team at Simba developed a Drill ODBC connector early on so that BI tools such as Tableau work with Drill. Now, a JDBC connector has also been contributed by the larger Drill community. These capabilities make Drill attractive to help with centralized approaches that make use of both traditional and big data tools, including design of enterprise data hubs or for use cases such as 360-degree-customer-view data aggregation.
Another development in response to user needs is a MongoDB plug-in for Drill that was contributed from a developer in the community, making it possible for Drill to provide standard SQL for use cases beyond Hadoop. Connectors for Elasticsearch and Cassandra are also in the pipeline.
What’s the secret sauce?
How can a project foster and benefit from a strong user community? From the first public design meeting to current discussions via user and developer mailing lists and a weekly live Drill Google Hangout (see the Apache Drill website), the broader Drill community continues to contribute to this open source project. Other ways in which users can provide feedback or raise awareness are through:
- Presentations at meetups and conferences
- Drill training
- Drill on Twitter @ApacheDrill
- Blogs and articles
Conclusions
Apache Drill provides people who work with big data a powerful new tool to meet the needs of evolving systems and new business approaches. Drill opens the door to using standard SQL easily, in a highly scalable way, with the flexibility needed to make use of a wide range of data sources and formats while maintaining performance. These capabilities reflect input from a community of users, developers, and architects. As more people begin to use Drill, their experiences can have further impact on the ongoing improvements and refinements of the software.
My thanks to Aman Sinha, Parth Chandra, and Jason Altekruse of the Apache Drill team at MapR Technologies who chatted with me about Drill. Many insights reported here are from them. Any errors are entirely my own.
For more detail on what Drill was built to do and how users can put it to work, watch the free O’Reilly webinar “Easy, Real-Time Access to Apache Drill.”
For a hands-on experience: attend the Apache Drill Bootcamp at Strata + Hadoop World NYC conference Tuesday, September 29, 2015, hosted by Tomer Shiran and Jacques Nadeau.
This post is a collaboration between O’Reilly and MapR. See our statement of editorial independence.
Image on article and category pages via The Google Art Project on Wikimedia Commons.