
Pipes and Filters for the Internet
![]() Yahoo!'s new Pipes service is a milestone in the history of the internet. It's a service that generalizes the idea of the mashup, providing a drag and drop editor that allows you to connect internet data sources, process them, and redirect the output. Yahoo! describes it as "an interactive feed aggregator and manipulator" that allows you to "create feeds that are more powerful, useful and relevant." While it's still a bit rough around the edges, it has enormous promise in turning the web into a programmable environment for everyone.
Yahoo!'s new Pipes service is a milestone in the history of the internet. It's a service that generalizes the idea of the mashup, providing a drag and drop editor that allows you to connect internet data sources, process them, and redirect the output. Yahoo! describes it as "an interactive feed aggregator and manipulator" that allows you to "create feeds that are more powerful, useful and relevant." While it's still a bit rough around the edges, it has enormous promise in turning the web into a programmable environment for everyone.
Before I get into the details of what it is and how it works, I want to give a little background on why I'm so excited. This is something I've been waiting nearly ten years for.
Back in the summer of 1997, at our first Perl conference, Jon Udell (who is among the most prescient of technology visionaries and the prototype for my concept of the alpha geek) gave a talk that electrified me. Jon expressed a vision of web sites as data sources that could be re-used, and of a new programming paradigm that took the whole internet as its platform. This was well before web services were au courant. We don't have a record of that talk, but a few years later, in a keynote at the 8th International Python conference, he said much the same thing:
To a remarkable degree, today's Web already is a vast collection of network services. So far, these services are mainly browser-oriented. My browser "calls" a service on Yahoo to receive a page of a directory. Or it "calls" a service on AltaVista to receive a page of search results.
One of the nicest things about the Web, however, is that browsers aren't the only things that can call on the services offered by websites. Programs written in any URL-aware language -- including Python, Perl, JavaScript, and Java -- can "call" these Web services too. To these programs, the Web looks like a library of callable components. What's more, it's very easy to build new Web services out of these existing components, by combining them in novel ways. I think of this as the Web's analog to the UNIX pipeline.
I picked up Jon's theme in my own keynote at JavaOne that year, a talk entitled The Network Really is the Computer:
I want to talk about the implications for that marvelous aspect of the fundamental UNIX design: the pipe, and its ability to connect small independent programs so that they could collectively perform functions beyond the capability of any of them alone. What is the equivalent of the pipe in the age of the web? ...This is one of the REALLY BIG IDEAS that is going to shape the next five or ten years of computing.
Now, many of you may think that mashups are already the equivalent of pipes. They certainly satisfy many of the requirements that Jon and I were talking about back in 2000. They allow developers to use two websites in a way that their creators didn't quite intend, which extends them and makes them more useful. But mashups have generally been limited in their scope, pairwise combinations with their output typically being simply another web site. That is, the pipes and filter mechanism had not been generalized.
But perhaps more significantly, to develop a mashup, you already needed to be a programmer. Yahoo! Pipes is a first step towards changing all that, creating a programmable web for everyone.
Using the Pipes editor, you can fetch any data source via its RSS, Atom or other XML feed, extract the data you want, combine it with data from another source, apply various built-in filters (sort, unique (with the "ue" this time:-), count, truncate, union, join, as well as user-defined filters), and apply simple programming tools like for loops. In short, it's a good start on the Unix shell for mashups. It can extract dates and locations and what it considers to be "text entities." You can solicit user input and build URL lines to submit to sites. The drag and drop editor lets you view and construct your pipeline, inspecting the data at each step in the process. And of course, you can view and copy any existing pipes, just like you could with shell scripts and later, web pages.
Now, while I say Pipes opens up mashup programming to the non-programmer, it's not entirely for the faint of heart. At minimum, you need to be able to look at a URL line and parse out the parameters (so, for example, you can use Pipes' "URL builder" module to construct input to a site's query function), understand variables and loops, and so on. But you don't really need to know these things to get started.
Pipes can simply be used as a kind of "power browser." (something Dale Dougherty has been looking for even longer than I've been looking for pipes and filters for the web). For example, you can build a custom mashup to search for traffic along your own routes every morning, or a news aggregator that searches multiple sites for subjects you care about. All you have to do is start with one of the existing modules. (And presumably, once pipes is opened to the public tonight, there will be many more, as anyone can publish their own modules.)
Brady Forrest is writing a separate post to dig more deeply into the how-to side. But to get the concept across, let's look at Aggregated News Alerts, a pipe that aggregates news alerts from bloglines, findory, Google News, Microsoft Live News, and Yahoo! News.
A preview of the pipe's output is shown below, after I've used the text input field to search for Linux:
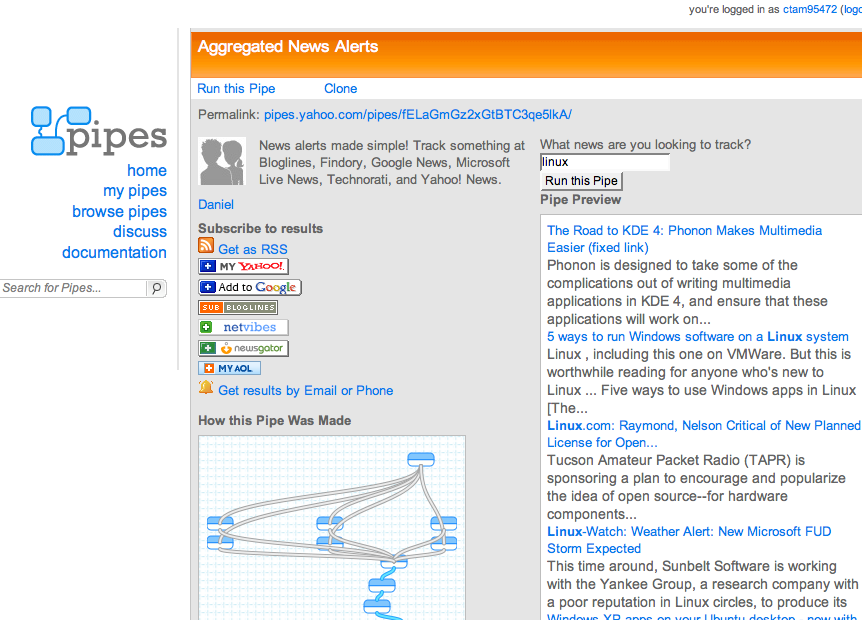
But I don't just get to look at this output on the pipes web site. I can pipe it further, as an RSS feed in its own right, I can send it to my feed aggregator of choice, and I can even get results by email or SMS.
OK. That's nice. But what's nicer is that even if I'm not much of a programmer, I can start to copy and paste to modify this pipe even further. I start by cloning the pipe. Now I have my own copy to play with. I can start by subtracting some feeds, and adding some others. For example, if I like to search for open source topics, I might want to subtract some of the general news sources and instead point to news sources like slashdot and the O'Reilly Network.
It's not quite as easy as drag and drop. I have to understand the query syntax of the sites I want to search, and modify the URL-builder modules to use that syntax rather than the syntax of the sites I'm replacing. But it's relatively easy once you play around a bit.
What's really lovely about this is that, like the Unix shell, Pipes provides a gradual introduction to web programming. You start out by modifying someone else's pipe just a bit, then branch out into something more adventurous.
As I wrote in Unix Power Tools back in 1993:
It has been said that Unix is not an operating system as much as it is a way of thinking. In The UNIX Programming Environment, Kernighan and Pike write that at the heart of the Unix philosophy "is the idea that the power of a system comes more from the relationships among programs than from the programs themselves."
Most of the nongraphical utility programs that have run under Unix since the beginning, some 30 years ago, share the same user interface. It's a minimal interface, to be sure — but one that allows programs to be strung together in pipelines to do jobs that no single program could do alone.
Most operating systems — including modern Unix and Linux systems — have graphical interfaces that are powerful and a pleasure to use. But none of them are so powerful or exciting to use as classic Unix pipes and filters, and the programming power of the shell.
A new user starts by stringing together simple pipelines and, when they get long enough, saving them for later execution in a file (Section 1.8), alias (Section 29.2), or function (Section 29.11). Gradually, if the user has the right temperament, he gets the idea that the computer can do more of the boring part of many jobs. Perhaps he starts out with a for loop (Section 28.9) to apply the same editing script to a series of files. Conditions and cases soon follow and before long, he finds himself programming.
On most systems, you need to learn consciously how to program. You must take up the study of one or more programming languages and expend a fair amount of concentrated effort before you can do anything productive. Unix, on the other hand, teaches programming imperceptibly — it is a slow but steady extension of the work you do simply by interacting with the computer.
Before long, you can step outside the bounds of the tools that have already been provided by the designers of the system and solve problems that don't quite fit the mold. This is sometimes called hacking; in other contexts, it is called "engineering." In essence, it is the ability to build a tool when the right one is not already on hand.
I think that's a pretty good description of Pipes as well. It democratizes web programming, making it easier for people to have more control over the internet information services they consume, and providing a general-purpose platform for interacting with sites that is more powerful than the browser or feed-reader alone, but without requiring full programming skills.
Pipes still has a ways to go in the ease of use department. Parsing and filtering a stream of xml isn't as easy as parsing Unix's ascii stdout. And the user interface of the editor itself needs a lot of work to make it easier to use. But it's a great start. Kudos to Pasha Sadri and the rest of the Pipes team!
tags: web 2.0
| comments: 81
| Sphere It
submit: ![]()
![]()
![]()
![]()
Comments: 81
I've been thinking about Yahoo Pipes myself, and I share your enthusiasm, Tim, but Niall Kennedy raises some good, practical considerations. I hate to greet one of the earliest feed-routing platforms with niggling technical concerns, but we still don't have a vocabulary for intelligently communicating intent with feeds, and this is going to expose the tension around that absence even more strongly.
Is the existence of a feed implicit permission for people to subscribe to it? For people to poll it frequently? For people to republish it? Amazingly, almost ten years in, we still don't have answers on those questions, and now we're getting into remixing, which is even more fraught. One man's splog generation tool is another man's pipe output.
I wish I had answers for the questions raised, and I am as hopeful for the potential as you are. But this is social software, and we should be wary of the minute a community of clone-happy spammers takes root in Pipes and starts to take all of the fun out of this fascinating milestone.
Working with these damned gui workflow components is annoying.
Why not give us a restricted set language instead so I can actually do something useful?
The UI of this amazing app must be influenced by Apple's Quartz Composer and earlier sound engineering apps such as Propellerhead's Reason.
Or perhaps the developers spent lots of time hooking up pre-dig audio and video equipment :)
Yahoo pipes just made thing a whole lot easier, didn't they? Remixing live feeds is now a doddle :-)
...although I guess that this solution isn't going to work for feeds that exist behind a firewall, at least until authenticated feed publishing systems are standardised upon and become more widespread.
To complement it, though, I'd like to see a drag'n'drop item level editor, that would let me construct 'static' RSS feeds from items taken from other feeds.
With a fully blown serialised/scheduled feed publishing platform (something like feedcycle.com on steroids), I could see feed powered publishing going a long way to make online training/elearning more effective.
PS The folks over at Grazr have also been exploring ways of lowering the barrier to entry for feed powered apps. I wonder what their take on Pipes is going to be? ;-)
Danno: Because they didn't build Yahoo Pipe for you. They build it for non-technical users, you know, the people that read "Dummies" books.
What *you* want is RSSBus (www.rssbus.com), the technical user's answer to Yahoo Pipes. It's downloadable software with the desktop version being free, if can do a lot more than Yahoo Pipes can do, and it is from /n software one of the leading vendors of Internet Protocol components for developers.
FYI, although I ran a company for over 12 years that had a long business relationship with /n software (as well as probably 500 other component vendors), I no longer run that company and hence no longer have any business relationship with /n software. My only interest in RSSbus at the moment is that I think it is an awesome product although I do wish I could convince them to make it open source.
Fascinating and quite well implemented. It isn't for joe public yet but it should help the many programmers out there who aren't RSS aware become RSS aware.
Well, I've looked and thought about it, and I'm coming up zilch. I don't see why this is interesting or that it will be of any use.
Apple's Quartz Composer is based on the same ideas (all the way to how the boxes are joined), but it didn't result in anyone writing their own programs.
There's a site called QuartzCompositions that has a few cute scripts, and it ends about there. I expect Pipes to do the same.
It finally seems, Yahoo! secretly started building a Semantic Web powerhouse, by making clunky RDF chunks (re-)deployable for the average web developer without having to care about the groundworkÖ ;-)
Hint for coders: Have a look into Pipes' debug-console at the bottom of the window.
Can we get websites/feeds with structured, machine-readable content? Please? How many years does it take to do the obvious?
This isn't revolutionary, it isn't remixing, mashing or anything else. It is what computers are meant to do - process and manipulate data. We've just been crippled by the web's idea that presentation to the end user is the direct goal and not intermediate manipulation by a machine controlled by the user. RSS feeds, web pages are just data stores. How can be build anything if content and services don't have machine-machine interfaces?
Tim, very interesting and timely post. Particularly, since IBM announced on their alphaWorks site a similar mashup tool for corporate intranets, QEDWiki!
In response to Anil's comments, it seems like you could allow a service like Pipes to not only handle the connections to services but to manage the permissions/licenses for them as well, and keep this stuff out of the feed itself (maybe including just one authorized "management ID"?). Since it's designed to be a social service, you could set up a network of permitted users of feeds and modules. I imagine the service could also detect misuses of your modules by splogs the way your computer detects viruses, and allow you to cut off the data to them.
Ideally this would be a separate but integrated feature, so you could use Yahoo or some other YASNS to control access. Does this exist yet? It seems like all YASNS's are closed boxes still, and none of the valuable network data inside is being used as an external web service, which is a pity.
Anil: I think the copyright issues will start to become a big deal now the big players are finally sniffing around this market. However, we've served just over a couple of billion requests over more than 50,000 feed digests in the last 18 months and we've had... 1 copyright complaint. Bizarrely it was a really small site involved in a spat with another, and they cleared the whole thing up themselves :)
+1 for their sense of self-deprecating humor:
"Our Pipes are clogged! We've called the plumbers!"
...when I went back to try it again. I'll come back in a few days to look at it again.
Excellent summary Tim. Is this a key step to bringing advanced data processing to "everybody"?
Blogging took off when it was no longer constrained by technological issues and it's fundamentally changing the way people process their world.
What's next?
Tim,
Following the same "Data Web" (Semantic Web - Layer 1) theme, here is a simple demostration of how far things have progress across other complimentary realms.
1. go to http://demo.openlinksw.com/isparql
2. Enter any of the following values into the "Data Source URI" field:
- http://www.oreilly.com/
- http://radar.oreilly.com/archives/2007/02/pipes_and_filte.html
- http://www.mkbergman.com/?p=336
I am query Web Data via the RDF Data Model without any assumed RDF Tax.
I will write in detail about this later, but your post flashed by my news reader and I was compelled contibute this note to the emerging "Data Web" discourse :-)
As Ivan mentioned above, if you're interested in Pipes!, you should take a look at Dappit. Dappit lets you scrape an HTML site, turn it into structured data, and provide that data as a realtime feed to anyone else.
It's quite clever and useful. It took me about 15 minutes to build my first dappit app.
I think it is a great idea. Right now there is an information overload. A solution to effectively create filters without having to write any code will be well received.
Seems mixing up Internet content is becoming all the rage. First this Tubes thing, then I just find this video on Digg, of some other browser-based mashup tool. Looks like Greasemonkey on steroids!
Am I the only one worried there will be a shortage of original content? Why do we need the web to be "alive'? Programmers can do all they need with their own dedicated server, a few fopen calls and some simple parsing. Why make it easy for script-kiddies to aggregate the entire web? Soon it will take 10 clicks to find an original article. Won't this destroy search engines? I, for one, am not excited about web 3.0. Maybe we should dub it the "Spinternet".
A great analogy for pipes is the OS from Star Trek The Next Generation. Hardcore programming through a GUI using drag and drop with visual associations and filters. The inevitable functional platform that is the internet.
As well all things Web, the issue is not how gee-whiz it is but how it scales and how stable it is. Pipes has already crashed.
I'm all for Jon Udell's vision and this is definitely a step in that direction, but it's NOT really pipes for the web.
The problem with doing this with feeds is that feeds were designed to work with client applications. They are poll based. This architecture prevents many from making feeds for their data because it's very bandwidth inefficient.
MY vision for Yahoo Pipes is like Apple's Automator, but for the web. But the primary technology needed for this is NOT RSS.
We need hooks. Web hooks. Let the applications post directly to where the user wants with the data. It's more efficient. It's real-time. It's super easy. It doesn't *need* a standard.
It will allow applications to transparently share data. It will give users access to their data and the data they create with applications in real-time. It will allow for an ecosystem of adaptor services and hook handlers that will build a *decentralized* infrastructure of meta-web programming.
DabbleDB has been the closest to doing this right with their new plugin architecture. I provide hooks for my app, DevjaVu.
I'm all for this vision. I see it very clearly. But we won't have it until we have something like web hooks. Yahoo Pipes is definitely a step forward, just like YubNub, and DabbleDB's plugins.
I know, I know, who am I... but read what I have to say and humor it at least until you get an epiphany. I'll have to write more about this in a blog post...
Patrick and Ivan -- We urged Yahoo! to get Dapper or OpenKapow integrated from the get go, and will continue to do so. It would be great to be able to have any web site as a data source, not just those with xml feeds.
I'm sure that will come. I'd also love to see a bunch of data visualization modules added. There's lots more to happen here, but it's a great start.
This seems to be part of the trend of thinking about the web as a database exposed as HTML/XML. My favorite so far is still Kapow because it's a lot more powerful. Dapper and QEDwiki are other interesting examples that do slightly different things.
Phil, it's not so much that it "crashed" as we grossly underestimated interest and are reprovisioning the system to better address demand. This wasn't anything we ever expected to be "scalable" upon launch, and we peppered the site and messaging with the "beta" moniker to be clear about this, etc. (And while "beta" has just become a fashion accessory, we actually meant it.) Definitely "our bad" and lesson learned, but honestly the downtime today is simply a reflection of how interesting folks are finding this idea.
Yahoo! Pipes seem to be offering a fantastic user interface that will allow many more people to "play" with RSS.
It would be interesting to find out what data representation format is used by Pipes to pass information inside pipelines.
Article "Yahoo! Pipes: The Modules For Building Pipes" says they have created wrappers for several services that did not expose their data as RSS. This might hint that RSS (plus some extensions) is being used as "water" in the pipeline. If so they may as well be limiting what information Yahoo! Pipes can work with. Richer information from sources such as SIOC profiles or FOAF friends lists will be lost during conversion to RSS.
If they have found a common format that all other formats can be converted to (without loss of information) then this service can potentially extend beyond RSS. In this case it should be easily adaptable to both consume and generate RDF, in which you should be able to express any knowledge or data.
It is a tad amazing that it toook this long to appear.
Having said that, has Yahoo considered the potential copyright violations?
This long to appear? What about the Ajax API they flopped. I think this was rather early for them to release something new.
And now we know what they've been smoking!
"Having said that, has Yahoo considered the potential copyright violations?"
I'd like to know if Yahoo has considered the potential for patent infringements. Not that I'll be using the service personally - as far as I'm concerned Yahoo is persona non grata since its despicable submission to the Gowers Review went even so far as to whine about the lack of availability of business method patents in the UK and Europe:
"The exclusion of, or extreme difficulty involved in, patenting inventions implemented using software (or, for that matter, business method-related inventions) is in our view an inherent weakness of the European approach to patents."
Being an interested novice, I just wondered if the widget on OSX which allows you to grab any part of any web page and display it with all your others favourites, is using this type of technology?
Long time ago but I thought "The Web as API" was Andrew Schulman's talk. Whoever it was, it was great. I 'got it' and I left my job and went to work for a company who's tagline was "Automate the Web" for the next five years.
It's great beginnig, but it suffers from child diseases. The most notable are troubles with text encodings.
BTW: it seems, that pipes use canvas element that makes it useles in Internet Explorer. Can not belive it ;)
Wow, I read the entire article and all of the comments and I still don't understand it. I guess I'm the John Q. Public you are all talking about.
Unfortunally, a service like this one, will permit a new era of spammers getting better content to their horrible only for adsense sites.
Ed -- you asked if the Web as API wasn't Andrew Schulman's talk. I remember Andrew's talk being closely related -- it was about the URL as command line, and what a powerful concept the URL was. But I don't remember it being about pipes and filters. Andrew was a windows guy, not a Unix guy, so I tend to think he wouldn't have hit that them. But your question raised enough doubt in my mind that I asked Jon. Here's what he replied:
"The Andrew Schulman talk I remember best -- not sure if it was from that conference or not, but I think it may have been -- was about the magic of URLs as human readable/transferable encapsulations of a whole bunch of computation. I remember him saying, over and over: Look, just 40 bytes, and every Fedex package can have its own home page. I also remember him saying that if MS had designed the URL it would look like
a GUID. Which of course, years later, came true in the case of their (ahem, our) blog platform :-)
We should ask him about the pipes theme, I just don't remember. [I will ask Andrew.]
I'm not exactly sure what my talk was at the first Perl conference. But I did write this in late 1996:
http://www.byte.com/art/9611/sec9/art1.htm
[Note: formatting is rather botched in the Byte copy. Here's a clean copy: http://jonudell.net/OnlineComponentware.html ]
For me that was the lightbulb moment. So I'd guess the topic of the web as a library of components might have been part of my talk in Aug 1997.
OTOH, now that you mention it, I don't remember you reacting to that theme then, or at the Perl conference the following summer. What you did react to was this:
http://www.byte.com/documents/s=146/byt19990906s0008/index.htm
Which was in 1999.
I remember you saying that this web pipeline stuff should be its own book :-)
But really, the whole web pipeline idea was (I assume) completely obvious to the Roy Fieldings of the world who created HTTP and the toolkits like libwww. So obvious that they didn't bother to articulate it, which is all that I did."
This is a very good concept,Internet is changing rapidly,Yahoo is catching up with google fast
Very interesting indeed! For all those of you who remember the old Amiga days: There has been a MIDI sequencer programm "Bars&Pipes" (very few information still in the net, e.g. http://fromwithin.com/liquidmidi/whatis.html) in the early 90's that featured a "pipeline" concept. The similarities of the user interfaces are striking. As always: The good ideas sometimes come back!
I think its extremmely easy to use, and making it easier to use would only make it less powerful. Don't change it at all!
Yahoo Pipes is a great way to create new applications from pre-existing ("pre-fab") modules.
However, this is nothing new. Way back in the early 1980s, a company called Metaphor Computer Systems had a similar tool. Called Capsule, you drag-and-drop (Yes, drag and drop. Metaphor's GUI desktop was based on Xerox Star.) different modules such as spreadsheets, documents and data accessor connector objects to process the data and produce the result you need.
Go to http://patricklogan.blogspot.com/2003/05/metaphor-computer-systems.html for the history and to http://www.meta5.com/M5Product/Product.asp for info on its current incarnation.
More on whether it was Jon Udell or Andrew Schulman who gave the pipes for the web talk at the first perl conference.
I should probably at least have credited Andrew (who is also a prototypical alpha geek) as well as Jon. Based on some memories and links from Andrew, it sounds like we were all talking about this idea *before* the conference.
Jon was the guy who started it all with some of the things he was building and talking about. Andrew, who was working for me as an editor at the time, got all fired up about Jon's ideas, and started working on a book (which he was working on in April of 97, a few months before the conference) about the idea. He never finished it, but based on his outline, I asked him to talk at the conference. His talk was probably the one I remember from the conference. (None of us remember exactly what Jon talked about.)
So, it was Jon's original idea, and possibly talks by both of them, that were at that conference.
Andrew Schulman wrote in email:
I think Jon gets precedence here, possibly from an earlier talk at the same conference. My reasoning below:
Let's see, looks like 1st Perl Conference was August 1997. I remember both Eric Raymond and I spoke. Here's a report from the time:
http://hydra.nac.uci.edu/indiv/dwatanab/perlconf.html
-------
Keynote - The Web as an API - Andrew Schulman
Andrew Schulman showed how the Web was becoming the command line of the future.
Andrew talked about the change in the concept of what computers can do because of the web. Specifically how some companies that make operating systems and GUI word processors have said that it would be impossible to be doing things that the web is now doing, so programmers are now having a whole new way of doing things open to them.
A large part of time was spent on how complex URLs can be used to cause programs to run on another machine and produce large ranges of data. (e.g.
http://www.zip2.com/scripts/map.dll?type=jdir&sType=street&
dType=street&dType=street&dstreet=103+MORRIS+ST&dcity=SEBASTOPOL&
dstate=CA&streetaddr=N+1st+St&userid=1184558&userpw=xtv0J_txAwt8t
E_FD0C&version=91450&java=no&sType=street&streetaddr=1st+st.& city=san+jose&state=CA&ccity=SEBASTOPOL&cstate=CA&ck=3599047&adrVer=
872139786&ver=d3.0 )
His talk is at: http://www.sonic.net/~undoc/perl/talk/webapi1.html
-------
And what do you know (I sure didn't remember), the talk is still there:
http://www.sonic.net/~undoc/perl/talk/webapi1.html
"The Web is the API"
... "Distributed Computation in the Guise of Hypertext!"
... "Snarfing Cycles
Or, using URLs to control processes on some other machine"
Using then-amazing example of tracking UPS packages. And there it is:
http://www.sonic.net/~undoc/perl/talk/webapi6.html
"As Jon Udell pointed out in his Perl conference talk, the UPS form was probably the first major example where a company used the web to 'open up
its business procedures to its customers.'"
With a link to http://dev5.byte.com/perlcon/perlcon.zip, which is busted. And not at archive.org. But clearly before my talk. Earlier at the same conference?
And later, he wrote:
In addition to my previous email about the 1997 Perl Conference and the reference I made in my talk to Jon's work, I remembered that I had explicitly discussed "pipes" in a book that I started writing on the subject. One thing is that I was almost oblivious to the security implications, but I did identify the problem of sites changes out from under a program ("bit rot", brittleness). It looks like I posted this material to sonic.net in April 1997:
http://www.sonic.net/~undoc/book/
... Using what seem at first like some "stupid web tricks" (hooking up NetCraft to the URL-minder), this chapter will show how to pipe one CGI process into another. That you can do this suggests that web sites are really tools, or software components. So perhaps a better chapter title would be "The Tools Approach to the Web."...
http://www.sonic.net/~undoc/book/chap5.html
... the point is how multiple processes on the web can sometimes be combined, in much the same the same that the output from one Unix program can be piped into another. Web Pipes, really. Problem: "bit rot", brittleness....
And yet another reference to Jon, so it really does seem he was way before me on all this:
... CGI processes: I say "processes" rather than "programs" to emphasize that these things are running today, right now, on machines across the planet, and you can employ them, without having to write one yourself. You do have to figure out what their "API" is, though (see Jon Udell articles on implicit CGI APIs). And this API can change out from under you (so what else is new?)....
... This chapter should also discuss CGI processes whose output is an embedable image: Web-Counter, US Naval Observatory time, etc. Not pipe-able, but embeddable...
I would have thought that google would have come up with something like this first but. I guess they do not know everything after all.
While the concept of pipes/pipelines is not new (unix, cocoon, webMethods flow services), the trend of providing powerful tools to users is amazing in my opinion. Any tools that make programming easier are a 'good thing' in my opinion (and I'm a programmer).
This type of product is similar to what integration middleware does in part. The biggest challenge is usually getting access to the data since there's often no API. I agree that a major hurdle is getting sites to provide content in some XML format. For example financial annual reports posted on SEDAR are in text format (PDF, etc) and getting the data from the tables within the pdf is not trivial nor in a standard layout or location. But hopefully products such as these will drive demand for for 'XML data sources'.
MORE HYPE HYPE HYPE!
RSS HAS NOT CHANGED THE WORLD OR THE INTERNET NEITHER WILL PIPES!
MORE CRAP!
Pipes provide the ability to take other people's content and then filter, refine, recombine and reuse it in interesting and innovative ways...right?
I just don't get why this is thought so significant. Surely most people who aren't producing interesting new content themselves (ie 95% of us) aren't capable of doing anything good with the output of the other 5%?
P.Andrews -- What I find significant is not that everyone will use this functionality, but that something that has been a black box to ordinary people has been made an order of magnitude more approachable.
This is important, because the small percentage of people who do use it will be brought that much further towards being masters of their computing environment, rather than passive consumers.
Think about the progress of computing from the glass house to today. A huge part of the progress is in putting control in the hands of a larger and larger group of people.
It's also significant to me because it highlights a way of thinkng about the internet, as a set of reusable components. That "architecture of participation" is something that keeps the internet interesting. Open is better than closed because it keeps things more innovative and interesting.
Pipes is a way of opening up web services to a whole new class of user.
This is really interesting. It looks very similiar to a "Business Process Management" tool my company just licensed for something like $90,000. It allows you to grab data from a web service and they tie it into other outputs... Something like give me all new customers from today and then send them a welcome email. The whole idea is orchestrating new workflows, etc. from existing web services, and this definetly looks just like that.
In response to the various postings that are saying various flavors of "this is great - but I need more machine readable content to make it fly" take a look at something I've been playing with.
There's a web service out there at http://sws.clearforest.com that takes unstructured text or xml and automagically finds all the people, companies, organizations and a few other things in it and returns these to you in xml. When I first got on pipes I was all excited that I would be able to build something cool by integrating this - but sigh - RSS only for the time being.
Anyway take a look at the ClearForest Semantic Web Services stuff - really quite cool.
Indeed, the main thing that Yahoo Pipes has done is that it's made a difficult programming chore more accessible to mainstream users. Just as so many programming languages make assembly language more accessible. However, there is still quite a learning curve for the average end-user. I have created some video tutorials to help lessen this curve. With your permission, here is the link: http://usefulvideo.blogspot.com/2007/02/yahoo-pipes-tutorials.html
This looks to be another big step in technological development for web tools and no doubt can be used by consumers and businesses alike but is it really a massive stepped change in the life of the internet. Take a look at this blog http://luddites-or-laggards.blogspot.com/2007/02/blogged-pipes-are-they-something-to.html comments welcome
>The UI of this amazing app must be influenced by Apple's Quartz Composer and earlier sound engineering apps such as Propellerhead's Reason.
Hey Jamie, check this out ;) http://soarack.blogspot.com
I took a quick look at Pipes and am looking forward to playing around with it some more.
macro.scopia It is a visual framework that allows the user to create processes as block diagrams.
These processes can retrieve information from several internet sources, mix, filter and then visualize them with different representations.
Similar to Yahoo Pipes
macro.scopia It is a visual framework that allows the user to create processes as block diagrams.
These processes can retrieve information from several internet sources, mix, filter and then visualize them with different representations.
Similar to Yahoo Pipes
Docs http://wikimacro.scopia.es/doku.php?id=documentation:english:english_docs
Apatar Open Source can be used to compliment Yahoo Pipes. It can extract data from on-premise systems and feed mashups in situations where large amounts of data need to be extracted from databases like MySQL or Oracle, transformed and loaded into a target like Amazon or SalesForce.com, or into an XML feed.
This new filtering method, will help users who dig for information on the same topic each and every day. Is like writing a book, then other and so on.
That's great. I just played around with and I love it.
But (of course there is a but) it would be great if there would be a sitescraper source could be added to extract data from websites without feeds. You probably didn't do it for IP reasons, I guess.
What I couldn't find is a way to manipulate items of a feed but maybe I haven't looked hard enough. Eg. I mixed several feeds into one and wanted to add the source of an Item to the title...
This is absolutely one of the best service in the history of Internet. I totally agree with Tim Oreilly when he mentions this as a milestone!
I am sure most of the people around dont even know what the pipe is all about lol...most people would end up here thinking that it has something to do with pipes and stuff... i mean it would be good if someone explained in details.. i mean i know a little about it but for a laymen this could be tuff to get hold of..but again a good move to be honest..
to quote
"This new filtering method, will help users who dig for information on the same topic each and every day. Is like writing a book, then other and so o"
I found a video tutorial that might be useful for you showing live how to use the new service from yahoo:
youtube.com/watch?v=bijSL5KR558
I agree that this is bound to lead to copyright violations - as others have alluded to.
Let's wait and see. It should be interesting. Thanks for sharing Tim.
very nice article. great work Tim. but little curious why google is not competing them in this thing. they always come parallel to thier competition. really confusing. but yahoo really did something new
Bars&Pipes also remembers me on an old MIDI sequencer program on the AMIGA, that´s a long time ago...
My Firm belief on this is that Yahoo have lead the way in many things but google will eventually master this technology. Google is probably looking to see how things pan out with this with Yahoo and then look to pounce on it.
Very nice things started by Yahoo. But i think when google will start this, they may also some into thier competition. but yahoo took the first step and thats awesome
Pipes with the function to geocode your favorite feeds and browse the items on an interactive map is really nice and useful, i´m working on it...
"..milestone in the history of the internett" - first I didn't think so, but now believe it more and more. I use it in my job and i think its really great thing. copyright violations - mmm... Yahoo rules!
Yes, I agreed. Yahoo may have a copyright problems about it. But I didn't find any info about troubles like that. So Yahoo going forward as it should be.
This is the "perfect" tool for me to illustrate to my coworkers a number of concepts relating to blogging, rss, and the universal database of participation all of us have been building.
In my opinion Yahoo Pipes are the first step to web 3.0.
Check this site to see a lot of Yahoo Pipes in actions: MacrosReader
A bit late to comment, but I guess this is worth checking: http://qerio.com; built using the technology available at http://virtual-devices.net
Post A Comment:
STAY CONNECTED
RECENT COMMENTS
- dj on Pipes and Filters for the Internet: A bit late to comment, ...
- oliver simon on Pipes and Filters for the Internet: Try http://www.websnips...
- Dan N. Moldovan on Pipes and Filters for the Internet: In my opinion Yahoo Pip...
- Thomas Lord on Pipes and Filters for the Internet: Pipes aren't much good ...
- franco on Pipes and Filters for the Internet: This is the "perfect" t...
- Daniel on Pipes and Filters for the Internet: Yes, I agreed. Yahoo ma...
- Vitali on Pipes and Filters for the Internet: "..milestone in the his...
- Arno on Pipes and Filters for the Internet: Pipes with the function...
- Karry on Pipes and Filters for the Internet: Very nice things starte...
- Mayoor on Pipes and Filters for the Internet: My Firm belief on this ...
RADAR TOPICS
YAMPS [02.07.07 09:44 PM]
I tried Anothr.com to subscribe the pipe service, it's awfully intersting and fun and just in time. The future of Micropipeline is coming, eventually. Yahoo made faster steps than Google. Fortuntely to them.