
Amazon S3 / EC2 / AWS outage this morning...
Many of Amazon.com's Web Services were down this morning with some customers reporting outages lasting over three hours. Sites that depend on services that depend on EC2 or S3 are down as well.
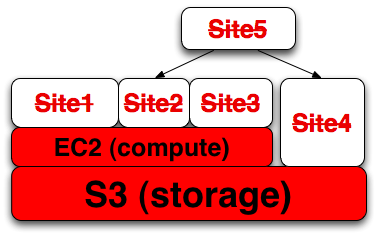
Failures like this happen in every system, and anyone that promises otherwise is foolish or lying (or both). Amazon does not promise that their systems won't fail, they offer service credits when S3 does fail in accordance with their Service Level Agreement. (see: earlier Radar post, video of my panel discussion about SLAs and regulation)
Nick Carr mentions what happened after the Salesforce outage in 2006:
[...] I feel compelled to point out the inevitable glitches that are going to happen along the way. How the supplier responds - in keeping customers apprised of the situation and explaining precisely what went wrong and how the source of the problem is being addressed - is crucial to building the trust of current and would-be users. When Salesforce.com suffered a big outage two years ago, it was justly criticized for an incomplete explanation; the company subsequently became much more forthright about the status of its services and the reasons behind outages. Given that entire businesses run on S3 and related services, Amazon has a particularly heavy responsibility not only to fix the problem quickly but to explain it fully.
Nick is referring to trust.salesforce.com which is currently the gold standard of availability reporting for Software as a Service providers. I hope this incident provides both pressure and incentive for other services to adopt similar standards soon.
Updated: David Ulevitch of OpenDNS added:
we've been providing a similar site to Trust.Salesforce.com since we launched -- and we find that the milage it brings us in user trust far outweighs the embarrassment of whatever we have to put up there. Our site's version is at http://system.opendns.com.
(Disclosure: OpenDNS is a Minor Ventures company along with Swivel where I am an Advisor.)
Phil Gross of Intuit Quickbase points to http://service.quickbase.com adding:
[...] We have found that being as clear and upfront as possible when there are issues goes a long way towards keeping customers happy, and it's also just the right thing to do. One thing to remember, if other companies are thinking about developing a similar service, is *not* to host your service page with your main web host or data center. Our service page is at our disaster recovery center, in a completely separate region of the country, so that if there were a network outage, we could still get the word out, and update on when we'd be back up.
My friend Scott Ruthfield points out DoubleClick's dashboard at http://qos.doubleclick.net/
Updated: Official update posted on the on AWS forums:
Here’s some additional detail about the problem we experienced earlier today.
Early this morning, at 3:30am PST, we started seeing elevated levels of authenticated requests from multiple users in one of our locations. While we carefully monitor our overall request volumes and these remained within normal ranges, we had not been monitoring the proportion of authenticated requests. Importantly, these cryptographic requests consume more resources per call than other request types.
Shortly before 4:00am PST, we began to see several other users significantly increase their volume of authenticated calls. The last of these pushed the authentication service over its maximum capacity before we could complete putting new capacity in place. In addition to processing authenticated requests, the authentication service also performs account validation on every request Amazon S3 handles. This caused Amazon S3 to be unable to process any requests in that location, beginning at 4:31am PST. By 6:48am PST, we had moved enough capacity online to resolve the issue.
As we said earlier today, though we're proud of our uptime track record over the past two years with this service, any amount of downtime is unacceptable. As part of the post mortem for this event, we have identified a set of short-term actions as well as longer term improvements. We are taking immediate action on the following: (a) improving our monitoring of the proportion of authenticated requests; (b) further increasing our authentication service capacity; and (c) adding additional defensive measures around the authenticated calls. Additionally, we’ve begun work on a service health dashboard, and expect to release that shortly.
Are there any other companies that provide similar reporting on their availability and performance?
tags: internet policy, operations, platform plays, startups, web 2.0
| comments: 18
| Sphere It
submit: ![]()
![]()
![]()
![]()
0 TrackBacks
TrackBack URL for this entry: http://blogs.oreilly.com/cgi-bin/mt/mt-t.cgi/6310
Comments: 18
We've gotten so good at reducing adoption friction, that we'll see a lot of this kind of thing. It just isn't possible to plan for it.
More on my blog:
http://smoothspan.wordpress.com/2008/02/15/google-reports-iphone-usage-50x-other-handsets-amazon-s3-goes-down-low-friction-has-a-cost/
Best,
BW
We host all our images on S3 here at Shutterpond Photo Contests. It was a very small hit, nothing to fuss about.
Customers should start looking for other alternatives such as Nirvanix, who offer an SLA and better customer support than Amazon. Amazon focused on one data center, Nirvanix has nodes across the world so that if one node goes down another one can step in and takeover the workload.
Not to toot our own horn, but we've been providing a similar site to Trust.Salesforce.com since we launched -- and we find that the milage it brings us in user trust far outweighs the embarrassment of whatever we have to put up there.
Our site's version is at http://system.opendns.com/
If S3 was bigger than it is now, outages would be financially more damaging that they are now. Especially if it occurred to a gambling site before the superbowl, or an e-comerce site before christmas.
I'd prefer it if an insurance company did an audit of your business, and offered insurance to cover full 'loss of revenue' if S3 goes down... paying more for some incidents than others.
Then it would be a no-brainer to use S3.
To Kim Lane: What matters is that people are designing their systems with the assumption that Failure Happens. It may be that a company says "we're willing to take the risk in exchange for reduced operating cost. We choose to take an outage if our Infrastructure as a Service goes down". That's totally acceptable so long as it's a decision made in advance and in the open.
To Bob Warfield: I agree that this will happen more as XaaS becomes a reality, and I'm betting that people who figure this out early will be winners in the space.
To Thorsten: I totally agree!
To David Ulevitch: Thanks for pointing that out. I bumped your comment to the main post.
To bex: What is not well understood is how corporate compliance requirements come into play with XaaS.
Dad, my cell phone broke!
Last summer my 15 year old greeted me - “Dad! My cell phone is broke and I can’t text my friends!” “mmm.. this is serious. What did you use to do before I bought you the phone?” “I wasn’t able to text back then, dah!!”
Today’s uproar re: the Amazon S3 outage takes me back to that funny moment when my daughter finally got my point - that I enabled her to enjoy the world of texting. And, like many AWS bloggers today, she did not appreciate that I gave her this gift.
So, to put a big picture perspective on today’s outage - most of us start ups, if not for AWS, would have burned thru our angel and round A funds to replicate AWS before we would have hit the tipping point and had the luxury of telling our customers that “we are experiencing an outage.”
Looking back on my old “school days” of expensive networks, users running out of storage and the constant flow of cash to admin staff, I must admit to having a soft spot for the AWS team and service. In those days, a two hour outage was considered an opportunity for our users to chat with the cube neighbor or go down to the cafeteria for a donut. Fast forward to today’s demanding customers and an outage of minutes starts Armageddon. Now, imagine if by some miracle, these customers actually pay for the start up’s service.
Today, I welcomed the outage as it reinforced my need for AWS. How would my small team respond to an outage? We don’t have the talented staff nor the passion the AWS team has. We forget that Amazon is in the small group of visionary “start-ups” who helped get the net to where we are today.
Phil Easter
CTO/AirMe
I work in the eBay Developers Program, and while we don't post the availability numbers for our Web services, we are willing to post our bug list and link to it from our home page http://developer.ebay.com/. Check out the bottom right side.
You can see all the open (and recently closed) bugs in our APIs, workarounds (if any), and the ETA for a fix (if we know it). Besides the web, you can even subscribe to these via e-mail, RSS, and NNTP.
Our attitude is, while we wish our APIs are always 100% bug free, they're not. Until we get there, instead of hiding this, and having our developers waste time trying to "debug" something that's not their fault, we'd rather be open with our community because it's how we'd want to be treated.
Nick, I agree. System reporting pages are worth the effort.
At Intuit QuickBase, we also have a live system status page that shows all outages and slowdown history for the last 30 days, and our uptime percentage over the past 90 days (including scheduled maintenance, which most companies don't report as part of their downtime...). We used to report outages to our blog, which we didn't find anywhere near as helpful for our customers. We have found that being as clear and upfront as possible when there are issues goes a long way towards keeping customers happy, and it's also just the right thing to do.
One thing to remember, if other companies are thinking about developing a similar service, is *not* to host your service page with your main web host or data center. Our service page is at our disaster recovery center, in a completely separate region of the country, so that if there were a network outage, we could still get the word out, and update on when we'd be back up.
The most impressive external monitoring of a core service that I've seen is DoubleClick's DART dashboard at http://qos.doubleclick.net/.
It includes, among other things, views into their Gomez and Sitescope monitors, information on their most recent release, overall ad performance right now, etc. (Some features seem to work better in IE.)
Businesses that depend on DART for revenue benefit from a quick place to check service status (and I expect it reduces DART support calls as well).
I agree with those who say we are being too hard on Amazon. All systems fail at some point or another (or, do they?).
Our grandchildren will see Amazon in their history books (or history blogs, or history holograms, or whatever) the same way we saw Thomas Edison in ours - as a pioneer (except that AWS, EC2, S3, etc., is a helluva lot more reliable than Edison's first DC electric utility was).
The problem now, though, is we are dealing with Moore's law. It took electricity decades to become ubiquitous, while fledgling utility - COMPUTING - only a couple of years in the offing, will be ubiquitous very soon.
We do not have decades to get the kinks out and have the equivalent of dial tone for utility computing.
Check out 3tera's AppLogic - multiple nines out of the box, standard infrastructure components, standard app code, any presentation layer you want, supports RDBMSs, easy to use, great value.
Amazon is, truly, the Edison of utility computing. We are grateful to them and admire them for that. 3tera is the General Electric!
It occurs to me that these external-facing service dashboards provide a juicy target for someone trying to hurt a company's service and reputation.
It's easy to believe that these dashboards are either
--hosted on the same infrastructure (HW, bandwidth, etc.) as the core service, or
--hosted on significantly weaker infrastructure (a couple of boxes in a separate data center, etc.)
So if I wanted to take down Salesforce, I could have one attack on their core service and a second, probably simpler and more-standard DDOS attack on their dashboard.
Protecting against this is possible, of course, and it's certainly not clear that people have such high expectations of external service monitoring that they would panic if the dashboards were down. Still, it's yet another thing, possibly an easy one, to put in the way of a service provider maintaining control over their technology and their message.
Jesse, the relationship you're diagrammatically displaying is really a critical lifeline, like tree roots or a circulatory system.
It might look more like this:
http://complexdiagrams.com/docs/dependency_tree.png
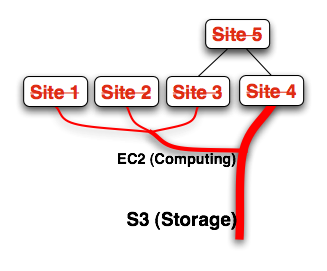{kind=link}
Site 5 doesn't have a direct dependency on AWS, but is still affected by referencing sites that do.
There is a very important question you have to ask yourself before deciding whether to use S3: what are you really looking for - remote storage, content delivery, or both. These are crucial to distinguish.
What I observe is that most people treat Amazon S3 as a content delivery service. While this is not inherently wrong, one has to notice that S3 was especially designed to be a STORAGE service. S3 does not claim to be a CDN.
The point is, since terabyte hard drives are affordable nowadays and internet traffic grows steadily, the stress goes much more on content delivery and network infrastructure rather than on storage. If you are not concerned about using remote storage, there are much better services especially suited for content delivery.
SteadyOffload.com provides an innovative, subtle and convenient way to offload static content. The whole mechanism there is quite different from Amazon S3. Instead of permanently uploading your files to a third-party host, their cachebot crawls your site and mirrors the content in a temporary cache on their servers. Content remains stored on your server while it is being delivered from the SteadyOffload cache. The URL of the cached object on their server is dynamically generated at page loading time, very scrambled and is changing often, so you don’t have to worry about hotlinking. This means that there is an almost non-existent chance that the cached content gets exposed outside of your web application.
It’s definitely worth trying because it’s not a storage service like S3 but exactly a service for offloading static content.
Watch that:
http://video.google.com/videoplay?docid=-8193919167634099306 (the video shows integration with WordPress, but it is integrable with any other webpage)
http://www.steadyoffload.com/
http://codex.wordpress.org/WordPress_Optimization/Offloading
Cost of bandwidth comes under $0.2 per GB - affordable, efficient and convenient. Looks like a startup but lures me very much. Definitely simpler and safer than Amazon S3.
Post A Comment:
STAY CONNECTED
RECENT COMMENTS
- Blagovest on Amazon S3 / EC2 / AWS outage this morning...: There is a very importa...
- Noah Iliinsky on Amazon S3 / EC2 / AWS outage this morning...: Jesse, the relationship...
- Scott Ruthfield on Amazon S3 / EC2 / AWS outage this morning...: It occurs to me that th...
- Barry X Lyn on Amazon S3 / EC2 / AWS outage this morning...: I agree with those who ...
- Scott Ruthfield on Amazon S3 / EC2 / AWS outage this morning...: The most impressive ex...
- Phil Gross on Amazon S3 / EC2 / AWS outage this morning...: Of course, it would hel...
- Phil Gross on Amazon S3 / EC2 / AWS outage this morning...: Nick, I agree. System r...
- Martin on Amazon S3 / EC2 / AWS outage this morning...: I did see this outage t...
- Adam Trachtenberg on Amazon S3 / EC2 / AWS outage this morning...: I work in the eBay Deve...
- Phil Easter on Amazon S3 / EC2 / AWS outage this morning...: Dad, my cell phone brok...
RADAR TOPICS
Kin Lane [02.15.08 09:42 AM]
WOW...this is a real black eye for Amazon. Some really scared and frustrated people on that forum.
Gives some fuel to the argument that you should always have a Plan B, even with Amazon Web Services.