
Service Monitoring Dashboards are mandatory for production services!
Google App Engine went down earlier today. GAE is still a developer preview release, and currently lacks a public monitoring dashboard. Unfortunately this means that many people either found out from their app and/or admin consoles being unavailable or from Mike Arrington's post on TechCrunch.
Google has a strong Web Operations culture, and there are numerous internal monitoring tools in use across the company, along with a smaller set available to customers. It's suprising that Google launched a developer platform without providing something beyond an email group, although they are by no means the first to do so.
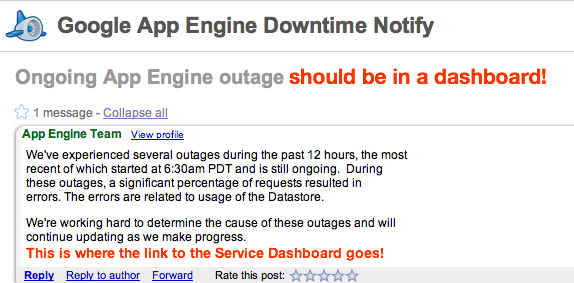
Service Monitoring Dashboards are mandatory for production services and platforms!
- If you launch a platform that people pay you money for, you need to have a real time service dashboard. Ideally this should be decoupled from the rest of your infrastructure.
- Don't rely on platforms that lack service monitoring dashboards for production.
Many companies are initially reluctant to provide this kind of monitoring to the public, and only do so in reaction to an outage. However, it seems that every company that offers such a dashboard uses it as a source of competitive advantage.
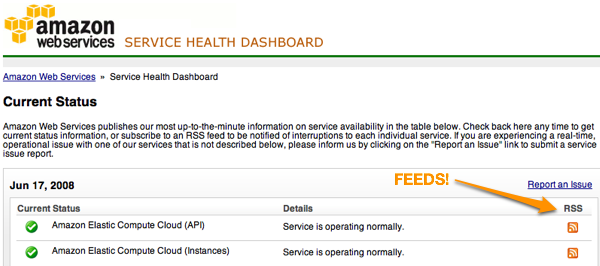
The best example of this is trust.salesforce.com which they launched after series of outages in 2006. Amazon (eventually) launched a status dashboard for AWS, and added RSS feeds for specific services which I think is pretty cool.
Javier Soltero at Hyperic points out
1. The reports of service outages arrive long after anyone who depends on the services can possibly do anything to mitigate their effect.
2. The services themselves seem incapable of providing any visibility into the circumstances that might lead to future outages.[...]Even TechCrunch points out that the Google Apps blog doesn’t even mention the outage. Other clouds rely on blogs such as this one, this one, or maybe even this one (from our good friends at Mosso). These are all places where outages can be discussed, but not the right means for people to find out whether it their application that crashed, or the cloud that it depends on.
(Updated:Niall Kennedy pointed out that GAE is still a preview release, and I agree that my original wording was wrong. My intent is to emphasize the importance of providing a public service dashboard and so I've edited accordingly.)
tags: failure happens, google app engine, infrastructure, internet policy, monitoring, operations, outages, platform plays, platforms, saas, velocity, web 2.0, web services, webops
| comments: 6
| Sphere It
submit: ![]()
![]()
![]()
![]()
0 TrackBacks
TrackBack URL for this entry: http://blogs.oreilly.com/cgi-bin/mt/mt-t.cgi/6561
Comments: 6
IMO, the dashboard and feed should be in a separate domain. Because if your DNS goes down, that's the kind of thing you need to provide news on. This is what burned SourceForge in their big datacentre outage -the dashboard disappeared too.
Just as a followup, Hyperic launched www.cloudstatus.com at the Velocity conference to address this very need. We'll be adding additional visibility into AWS and additional clouds over the coming months.
Most of the posts seem to look at having this service level dashboards for cloud-type services, such as Google or Amazon. Of course a great idea.
I haven't seen widespread adoption of that type of end-user performance dashboard for just regular services within a typical data-center.
Thoughts?
I am blogging about these types of conversations and observations at www.realuserwebops.com
I would love to hear other people's thoughts....not sure I get pinged when people comment on this blog.
As much as we dread to hear of outages, you'd have to be prepared to face the fact that these things will continue to happen and exploring alternatives to provide users and the public as well with monitoring tools will likely be a key factor in the adoption of cloud compute services.
You may want to take a look at what we've set up at Mor.ph for our Morph Appspaces
Best.
alain.
Post A Comment:
STAY CONNECTED
RECENT COMMENTS
- friarminor on Service Monitoring Dashboards are mandatory for production services!: As much as we dread to ...
- Tim T on Service Monitoring Dashboards are mandatory for production services!: Most of the posts seem ...
- Javier A. Soltero on Service Monitoring Dashboards are mandatory for production services!: Just as a followup, Hyp...
- Steve Loughran on Service Monitoring Dashboards are mandatory for production services!: IMO, the dashboard and ...
- Jesse Robbins on Service Monitoring Dashboards are mandatory for production services!: Thanks for pointing tha...
- Niall Kennedy on Service Monitoring Dashboards are mandatory for production services!: Google App Engine is cu...
RADAR TOPICS
Niall Kennedy [06.17.08 06:53 PM]
Google App Engine is currently in preview release stages. No charge, no SLA, risky for a production service. Two weeks ago they allowed more developers through the doors to stress test the system and it looks like someone tripped a BigTable issue this morning.
Looks like a rogue query brought down the whole BigTable structure causing 502 errors. They also pushed a client update this morning and it looks like they had many external devs testing the bulk loader (write heavy).