
The new internet traffic spikes
Theo Schlossnagle, author of Scalable Internet Architectures, gave a great explanation of how internet traffic spikes are shifting:
Lately, I see more sudden eyeballs and what used to be an established trend seems to fall into a more chaotic pattern that is the aggregate of different spike signatures around a smooth curve. This graph is from two consecutive days where we have a beautiful comparison of a relatively uneventful day followed by long-exposure spike (nytimes.com) compounded by a short-exposure spike (digg.com):
The disturbing part is that this occurs even on larger sites now due to the sheer magnitude of eyeballs looking at today's already popular sites. Long story short, this makes planning a real bitch.
[...]What isn't entirely obvious in the above graphs? These spikes happen inside 60 seconds. The idea of provisioning more servers (virtual or not) is unrealistic. Even in a cloud computing system, getting new system images up and integrated in 60 seconds is pushing the envelope and that would assume a zero second response time. This means it is about time to adjust what our systems architecture should support. The old rule of 70% utilization accommodating an unexpected 40% increase in traffic is unraveling. At least eight times in the past month, we've experienced from 100% to 1000% sudden increases in traffic across many of our clients.
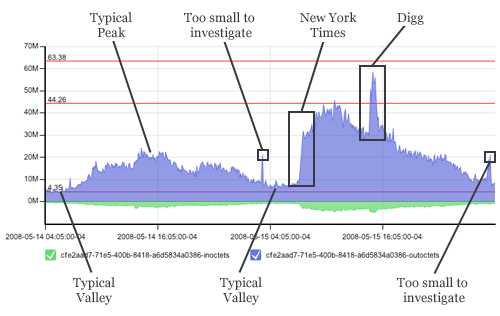
[Link]
tags: operations, trends, velocity, web 2.0, worries
| comments: 5
| Sphere It
submit: ![]()
![]()
![]()
![]()
0 TrackBacks
TrackBack URL for this entry: http://blogs.oreilly.com/cgi-bin/mt/mt-t.cgi/6579
Comments: 5
Indeed. Ensuring that you can easily scale horizontally isn't "optimization", at least, not the way that I think Knuth meant it. This would actually be a great question to ask him, as it seems to be so often misused.
-Jesse
Excellent post. It seems that you need to have a sufficient number of servers always available, maybe sitting at 25-50% of a spike load. When a spike comes, you begin ramping up horizontally with some dropouts, but withing a few minutes you should be able to support the spike with no dropouts. As the spike subsides, the servers will begin sleeping again and reach pre-spike levels. This should all happen automatically in software. This would be ideal, I think :) Thoughts?
We've seen similar spikes in the near past, and now we're keeping about 10x capacity online for our front end web servers. Diggnation seems to put extra special effort into load testing our front end, and I easily can see a 5x spike from a front page link there.
Keeping hits in the database tier as low as possible from very early on, caching as much as possible, and keeping your web infrastructure online with caches primed seems to be the best option.
The flip side to these intense spikes and to this article is, that rarely do the 10x spikes last long, and it does give you the wakeup call you sometimes need to re engineer for scalability.
ive noticed this as well.
'a period of increased volatility'
is the n.taleb-ian phrase that comes to mind
Post A Comment:
STAY CONNECTED
RECENT COMMENTS
- dylan halberg on The new internet traffic spikes: ive noticed this as wel...
- Ken DeMaria on The new internet traffic spikes: We've seen similar spik...
- Jesse Chan on The new internet traffic spikes: Excellent post. It see...
- Jesse Robbins on The new internet traffic spikes: Indeed. Ensuring that ...
- Allspaw on The new internet traffic spikes: My favorite part of The...
RADAR TOPICS
Allspaw [06.29.08 07:07 AM]
My favorite part of Theo's post:
"Understanding what is and isn't "premature" is what separates senior engineers from junior engineers."
(referring to the (in)famous Knuth quote that, IMHO, is followed so blindly these days)