Jim Scott

Jim Scott is the director of enterprise strategy and architecture at MapR. He has held positions running operations, engineering, architecture and QA teams. Jim is the cofounder of the Chicago Hadoop Users Group (CHUG), where he has coordinated the Chicago Hadoop community for the past four years. He has worked in the consumer packaged goods, digital advertising, digital mapping, chemical and pharmaceutical industries. He's built systems that handle more than 50 billion transactions per day. Jim's work with high-throughput computing at Dow Chemical was a precursor to more standardized big data concepts like Hadoop.
Zeta Architecture: Hexagon is the new circle
An enterprise architecture solution for scale and efficiency.

Data processing in the enterprise goes very swiftly from “good enough” to “we need to be faster!” as expectations grow. The Zeta Architecture is an enterprise architecture that enables simplified business processes and defines a scalable way for increasing the speed of integrating data into the business. Following a bit of history and a description of the architecture, I’ll use Google as an example and look at the way the company deploys technologies for Gmail.
Origin story and motivation
I’ve worked on a variety of different information systems over my career, each with their own classes of challenge. The most interesting from a capacity perspective was for a company that delivers digital advertising. The biggest technical problems in that industry flow from the sheer volume of transactions that occur on a daily basis. Traffic flows in all hours of the day, but there are certainly peak periods, which means all planning must revolve around the capacity during the peak hours. This solution space isn’t altogether different than that of Amazon; they had to build their infrastructure to handle massive loads of peak traffic. Both Amazon and digital advertising, incidentally, have a Black Friday spike.
Many different architectural ideas came to my mind while I was in digital advertising. Real-time performance tracking of the advertising platform was one such thing. This was well before real-time became a hot buzzword in the technology industry. There was a point in time where this digital advertising company was “satisfied” with, or perhaps tolerated, having a two-to-three-hour delay between making changes to the system and having complete insight into the effects of the changes. After nearly a year at this company, I was finally able to get a large architectural change made to streamline log collection and management. Before the implementation started, I told everyone involved what would happen. Although this approach would enable the business to see the performance within approximately 5-10 minutes of the time a change was made, that this would not be good enough after people got a feel for what real-time could deliver. Since people didn’t have that taste in their mouths, they wouldn’t yet support going straight to real-time for this information. The implementation of this architecture was in place a few months after I departed the company for a new opportunity. The implementation worked great, and after about three months of experience with the new architecture, my former colleagues contacted me and told me they were looking to re-architect the entire solution to go to real time. Read more…
A tale of two clusters: Mesos and YARN
With Myriad, analytics can be performed on the same hardware that runs your production services.
This is a tale of two siloed clusters. The first cluster is an Apache Hadoop cluster. This is an island whose resources are completely isolated to Hadoop and its processes. The second cluster is the description I give to all resources that are not a part of the Hadoop cluster. I break them up this way because Hadoop manages its own resources with Apache YARN (Yet Another Resource Negotiator). Which is nice for Hadoop, but all too often those resources are underutilized when there are no big data workloads in the queue. And then when a big data job comes in, those resources are stretched to the limit, and they are likely in need of more resources. That can be tough when you are on an island.
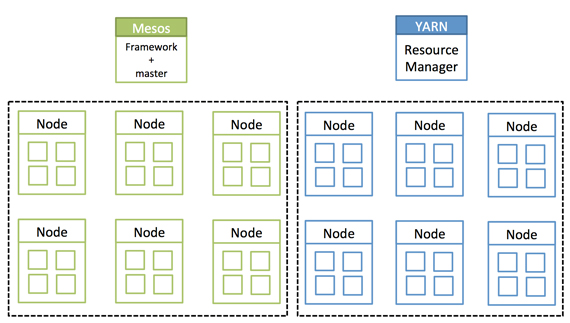
Isolated clusters. Source: Mesosphere and MapR, used with permission.
Hadoop was meant to tear down walls — albeit, data silo walls — but walls, nonetheless. What has happened is that while tearing some walls down, other types of walls have gone up in their place.
Another technology, Apache Mesos, is also meant to tear down walls — but Mesos has often been positioned to manage the “second cluster,” which are all of those other, non-Hadoop workloads.
This is where the story really starts, with these two silos of Mesos and YARN. They are often pitted against each other, as if they were incompatible. It turns out they work together, and therein lies my tale. Read more…