Max Neunhöffer

Max Neunhöffer is a mathematician turned database developer. In his academic career, he has worked for 16 years on the development and implementation of new algorithms in computer algebra, mainly for the open source system GAP. During this time, he has juggled a lot with mathematical big data like group orbits containing trillions of points. Recently, he has returned from St. Andrews in Scotland to Germany, has shifted his focus to NoSQL databases, and now helps to develop ArangoDB.
Data modeling with multi-model databases
A case study for mixing different data models within the same data store.
Editor’s note: Full disclosure — the author is a developer and software architect at ArangoDB GmbH, which leads the development of the open source multi-model database ArangoDB.
In recent years, the idea of “polyglot persistence” has emerged and become popular — for example, see Martin Fowler’s excellent blog post. Fowler’s basic idea can be interpreted that it is beneficial to use a variety of appropriate data models for different parts of the persistence layer of larger software architectures. According to this, one would, for example, use a relational database to persist structured, tabular data; a document store for unstructured, object-like data; a key/value store for a hash table; and a graph database for highly linked referential data. Traditionally, this means that one has to use multiple databases in the same project, which leads to some operational friction (more complicated deployment, more frequent upgrades) as well as data consistency and duplication issues.
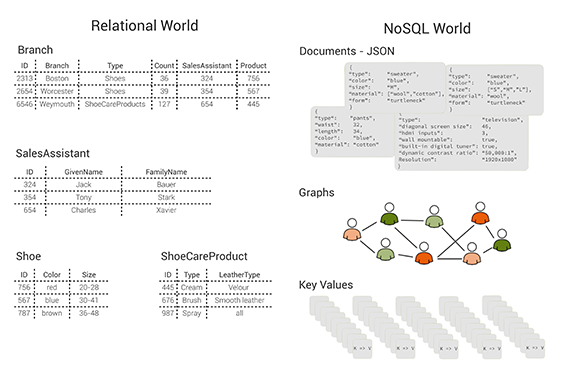
Figure 1: tables, documents, graphs and key/value pairs: different data models. Image courtesy of Max Neunhöffer.
This is the calamity that a multi-model database addresses. You can solve this problem by using a multi-model database that consists of a document store (JSON documents), a key/value store, and a graph database, all in one database engine and with a unifying query language and API that cover all three data models and even allow for mixing them in a single query. Without getting into too much technical detail, these three data models are specially chosen because an architecture like this can successfully compete with more specialised solutions on their own turf, both with respect to query performance and memory usage. The column-oriented data model has, for example, been left out intentionally. Nevertheless, this combination allows you — to a certain extent — to follow the polyglot persistence approach without the need for multiple data stores. Read more…