
Learning programming at scale
Bringing some of the benefits of face-to-face learning to millions of people without access to an in-person tutor.
Millions of people around the world — from aspiring software engineers to data scientists — now want to learn programming. One of the best ways to learn is by working side-by-side with a personal tutor. A good tutor can watch you as you code, help you debug, explain tricky concepts on demand, and provide encouragement to keep you motivated. However, very few of us are lucky enough to have a tutor by our side. If we take a class, there might be 25 to 50 students for every teacher. If we take a MOOC (Massive Open Online Course), there might be 1,000 to 10,000 students for every professor or TA. And if we’re learning on our own from books or online tutorials, there’s no tutor or even fellow learners in sight. Given this reality, how can computer-based tools potentially bring some of the benefits of face-to-face learning to millions of people around the world who do not have access to an in-person tutor?
I’ve begun to address this question by building open-source tools to help people overcome a fundamental barrier to learning programming: understanding what happens as the computer runs each line of a program’s source code. Without this basic skill, it is impossible to start becoming fluent in any programming language. For example, if you’re learning Python, it might be hard to understand why running the code below produces the following three lines of output:
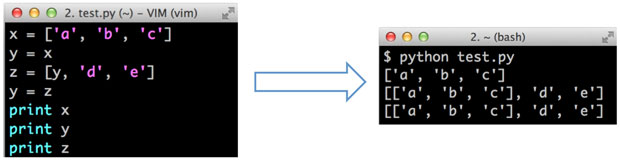
A tutor can explain why this code prints what it does by drawing the variables, data structures, and pointers at each execution step. However, what if you don’t have a personal tutor?

4 things to make your Java 8 code more dynamic
Anytime is a good time to refactor your code.

Java 8 has a few new features which should help you write more dynamic code. Of course one of the big features was the addition of a lambda syntax. But what about some of the other features that were added? Here are a couple of things that I tell people to do in order to make their code more dynamic and more functional.

What it means to “go pro” in data science
A look at what it takes to be a professional data science programmer.
 My experience of being a data scientist is not at all like what I’ve read in books and blogs. I’ve read about data scientists working for digital superstar companies. They sound like heroes writing automated (near sentient) algorithms constantly churning out insights. I’ve read about MacGyver-like data scientist hackers who save the day by cobbling together data products from whatever raw material they have around.
My experience of being a data scientist is not at all like what I’ve read in books and blogs. I’ve read about data scientists working for digital superstar companies. They sound like heroes writing automated (near sentient) algorithms constantly churning out insights. I’ve read about MacGyver-like data scientist hackers who save the day by cobbling together data products from whatever raw material they have around.
The data products my team creates are not important enough to justify huge enterprise-wide infrastructures. It’s just not worth it to invest in hyper-efficient automation and production control. On the other hand, our data products influence important decisions in the enterprise, and it’s important that our efforts scale. We can’t afford to do things manually all the time, and we need efficient ways of sharing results with tens of thousands of people.
There are a lot of us out there — the “regular” data scientists; we’re more organized than hackers but with no need for a superhero-style data science lair. A group of us met and held a speed ideation event, where we brainstormed on the best practices we need to write solid code. This article is a summary of the conversation and an attempt to collect our knowledge, distill it, and present it in one place. Read more…

Building C# objects dynamically
Using ExpandoObject to create objects that you can add properties, methods, and events to.

Buy “C# 6.0 Cookbook” in early release.
Editor’s note: This is an excerpt from “C# 6.0 Cookbook,” by Jay Hilyard and Stephen Teilhet. It offers more than 150 code recipes to common and not-so-common problems that C# programmers face every day. In it, you’ll find recipes on asynchronous methods, dynamic objects, enhanced error handling, the Rosyln compiler, and more.
Problem
You want to be able to build up an object to work with on the fly at runtime.
Solution
Use ExpandoObject to create an object that you can add properties, methods, and events to and be able to data bind to in a user interface.
We can use ExpandoObject to create an initial object to hold the Name and current Country of a person.
dynamic expando = new ExpandoObject();
expando.Name = "Brian";
expando.Country = "USA";
Once we have added properties directly, we can also add properties to our object in a more dynamic fashion using the AddProperty method we have provided for you. One example of why you might do this is to add properties to your object from another source of data. We will add the Language property.

Signals from OSCON 2015
From Pluto flybys to open source in the enterprise to engineering the future, here are key highlights from OSCON 2015.
Experts and advocates from across the open source world assembled in Portland, Ore., this week for OSCON 2015. Below you’ll find a handful of keynotes and interviews from the event that we found particularly notable.
Cracking open the IoT
In an interview at OSCON, Alasdair Allan, director at Babilim Light Industries, talked about the data coming out of the New Horizons Pluto flyby, the future of “personal space programs,” and the significance of Bluetooth LE to the Internet of Things:
Now that all the smartphones have Bluetooth LE — or at least the modern ones, there is a very easy way to produce low-power devices (wearables, embedded sensors) that anyone can access with a smartphone. … It’s a real lever to drive the Internet of Things forward, and you’re seeing a lot of the progress in the Internet of Things, a lot of the innovation, is happening — especially in Kickstarter — around BLE devices.

Get started with functional programming in Python
Start writing shorter and less bug-prone Python code.

Download Functional Programming in Python.
It is hard to get a consistent opinion on just what functional programming is, even from functional programmers themselves. A story about elephants and blind men seems apropos here. Usually we can contrast functional programming with “imperative programming” (what you do in languages like C, Pascal, C++, Java, Perl, Awk, TCL, and most others, at least for the most part). Functional programming is not object-oriented programming (OOP), although some languages are both. And it is not Logic Programming (e.g., Prolog).
I would roughly characterize functional programming as having at least several of the following characteristics:
- Functions are first class (objects). That is, everything you can do with “data” can be done with functions themselves (such as passing a function to another function). Moreover, much functional programming utilizes “higher order” functions (in other words, functions that operate on functions that operate on functions).
- Functional languages eschew side effects. This excludes the almost ubiquitous pattern in imperative languages of assigning first one, then another value to the same variable to track the program state.
- In functional programming we focus not on constructing a data collection but rather on describing “what” that data collection consists of. When one simply thinks, “Here’s some data, what do I need to do with it?” rather than the mechanism of constructing the data, more direct reasoning is often possible.
Functional programming often makes for more rapidly developed, shorter, and less bug-prone code. Moreover, high theorists of computer science, logic, and math find it a lot easier to prove formal properties of functional languages and programs than of imperative languages and programs.