- Memory Allocation in Brains (PDF) — The results reviewed here suggest that there are competitive mechanisms that affect memory allocation. For example, new dentate gyrus neurons, amygdala cells with higher excitability, and synapses near previously potentiated synapses seem to have the competitive edge over other cells and synapses and thus affect memory allocation with time scales of weeks, hours, and minutes. Are all memory allocation mechanisms competitive, or are there mechanisms of memory allocation that do not involve competition? Even though it is difficult to resolve this question at the current time, it is important to note that most mechanisms of memory allocation in computers do not involve competition. Does the dissector use a slab allocator? Tip your waiter, try the veal.
- Living Foundries (DARPA) — one motivating, widespread and currently intractable problem is that of corrosion/materials degradation. The DoD must operate in all environments, including some of the most corrosively aggressive on Earth, and do so with increasingly complex heterogeneous materials systems. This multifaceted and ubiquitous problem costs the DoD approximately $23 Billion per year. The ability to truly program and engineer biology, would enable the capability to design and engineer systems to rapidly and dynamically prevent, seek out, identify and repair corrosion/materials degradation. (via Motley Fool)
- Innovate Salone — finalists from a Sierra Leone maker/innovation contest. Part of David Sengeh‘s excellent work.
- Arts, Humanities, and Complex Networks — ebook series, conferences, talks, on network analysis in the humanities. Everything from Protestant letter networks in the reign of Mary, to the repertory of 16th century polyphony, to a data-driven update to Alfred Barr’s diagram of cubism and abstract art (original here).
"analysis" entries

The Snapchat Leak
4.6 million phone numbers, is one of them yours?
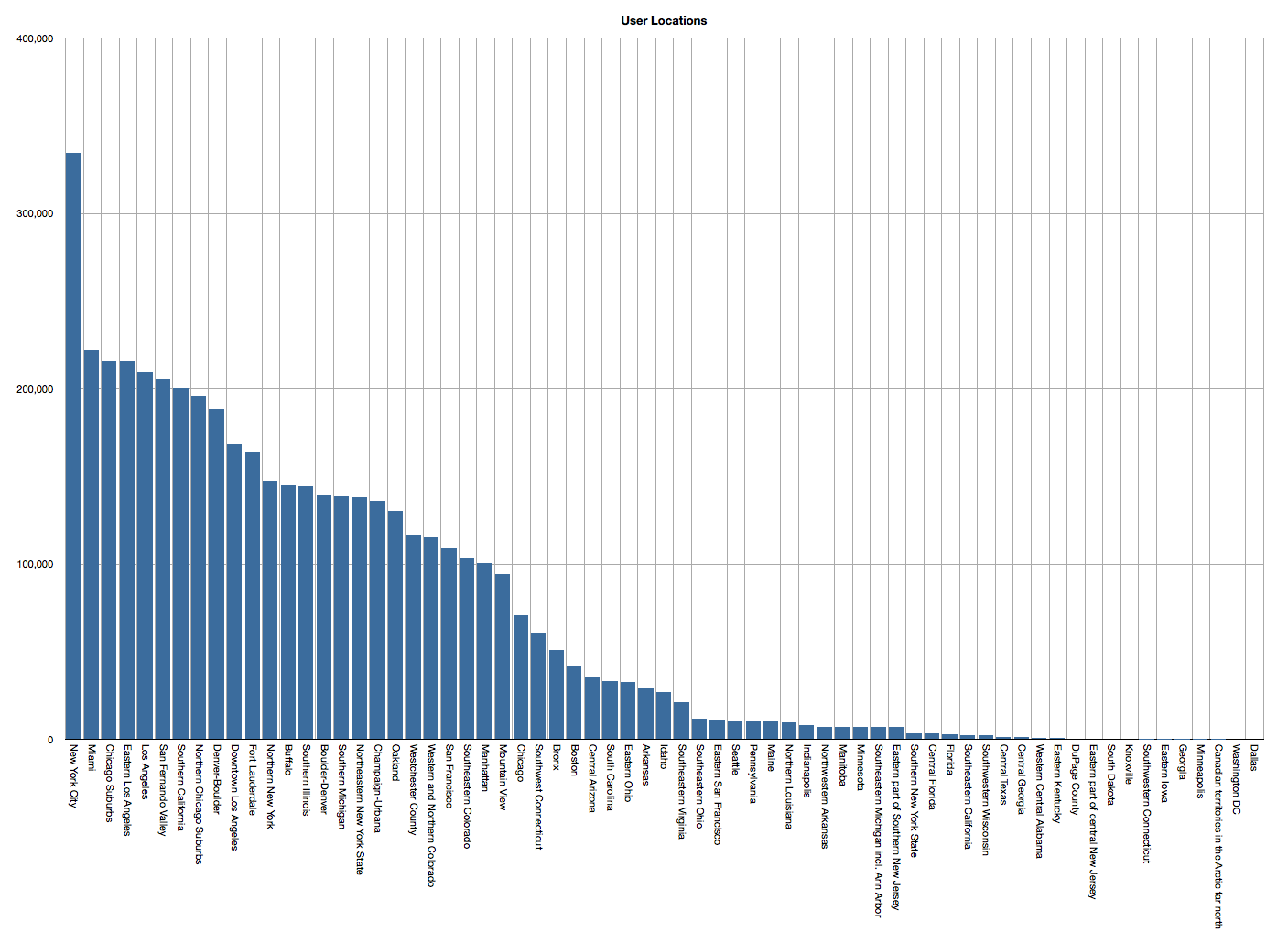
The number of Snapchat users by geographic location. Users are predominately located in New York, San Francisco and the surrounding greater New York and Bay Areas.
While the site crumbled quickly under the weight of so many people trying to get to the leaked data—and has now been suspended—there isn’t really such a thing as putting the genie back in the bottle on the Internet.
Just before Christmas the Australian based Gibson Security published a report highlighting two exploits in the Snapchat API claiming that hackers could easily gain access to users’ personal data. Snapchat dismissed the report, responding that,
Theoretically, if someone were able to upload a huge set of phone numbers, like every number in an area code, or every possible number in the U.S., they could create a database of the results and match usernames to phone numbers that way.
Adding that they had various “safeguards” in place to make it difficult to do that. However it seems likely that—despite being explicitly mentioned in the initial report four months previously—none of these safeguards included rate limiting requests to their server, because someone seems to have taken them up on their offer.

Four short links: 26 June 2013
Neural Memory Allocation, DoD Synthbio, Sierra Leone Makers, and Complex Humanities Networks
{kind=link}
Digging into the UDID data
The UDID story has conflicting theories, so the only real thing we have to work with is the data.
Over the weekend the hacker group Antisec released one million UDID records that they claim to have obtained from an FBI laptop using a Java vulnerability. In reply the FBI stated:
The FBI is aware of published reports alleging that an FBI laptop was compromised and private data regarding Apple UDIDs was exposed. At this time there is no evidence indicating that an FBI laptop was compromised or that the FBI either sought or obtained this data.
Of course that statement leaves a lot of leeway. It could be the agent’s personal laptop, and the data may well have been “property” of an another agency. The wording doesn’t even explicitly rule out the possibility that this was an agency laptop, they just say that right now they don’t have any evidence to suggest that it was.
This limited data release doesn’t have much impact, but the possible release of the full dataset, which is claimed to include names, addresses, phone numbers and other identifying information, is far more worrying.
While there are some almost dismissing the issue out of hand, the real issues here are: Where did the data originate? Which devices did it come from and what kind of users does this data represent? Is this data from a cross-section of the population, or a specifically targeted demographic? Does it originate within the law enforcement community, or from an external developer? What was the purpose of the data, and why was it collected?
With conflicting stories from all sides, the only thing we can believe is the data itself. The 40-character strings in the release at least look like UDID numbers, and anecdotally at least we have a third-party confirmation that this really is valid UDID data. We therefore have to proceed at this point as if this is real data. While there is a possibility that some, most, or all of the data is falsified, that’s looking unlikely from where we’re standing standing at the moment.

Top Stories: July 2-6, 2012
Reevaluating criticism of visualizations, why websites still matter, Amazon as friend and foe.
This week on O'Reilly: Andy Kirk made the case for open-minded criticism of visualizations, Brett Slatkin explained why you still need to own a website, and Greenleaf Book Group CEO Clint Greenleaf discussed the complicated relationship between publishers and Amazon.

Walking the tightrope of visualization criticism
The balance, fairness and realism of our visualization criticism must improve.
A creative field, such as visualization, will have many different interpretations and perspectives. The resolution and richness of this opinion is important to safeguard.
Why the finance world should care about big data and data science
Roger Magoulas on data's potential to improve finance systems and create new businesses.
O'Reilly director of market research Roger Magoulas discusses the intersection of big data and finance, and the opportunities this pairing creates for financial experts.

Re-engineering the data stack for speed
Acunu is taking a new approach to data storage. Here's what that means for developers.
Acunu CEO Tim Moreton talks about how his company has redesigned the data stack from the ground up, and what the resulting speed boost might mean for big data developers.

Data and a sense of self
Gary Wolf on how Quantified Self marries data with personal improvement.
User data isn’t the sole domain of marketing manipulation — we can harness and apply that data for our own purposes as well. In this interview, Gary Wolf explains how the Quantified Self is encouraging “the personal use of personal data.”

2010 State of the Computer Book Market, Post 5 – Wrap-Up and Digital
In this final post, I provide a summary of the first four posts, provide some insight into a view of top authors, and include some data on electronic books and how parts of the digital world are surpassing the print world.
2010 State of the Computer Book Market, Post 4 – The Languages
In the fourth post in this series, we look at programming languages and drill in a little on each language area.