- The Transformation of the Workplace Through Robotics, Artificial Intelligence, and Automation — fascinating legal questions about the rise of the automated workforce. . Is an employer required to bargain if it wishes to acquire robots to do work previously performed by unionized employees working under a collective bargaining agreement? does the collective bargaining agreement control the use of robots to perform this work? A unionized employer seeking to add robots to its business process must consider these questions. (via Robotenomics)
- The Invasive Valley of Personalization (Maria Anderson) — there is a fine line between useful personalization and creepy personalization. It reminded me of the “uncanny valley” in human robotics. So I plotted the same kind of curves on two axes: Access to Data as the horizontal axis, and Perceived Helpfulness on the vertical axis. For technology to get vast access to data AND make it past the invasive valley, it would have to be perceived as very high on the perceived helpfulness scale.
- Coffee and Feature Creep — fantastic story of how a chat system became a bank. (via BoingBoing)
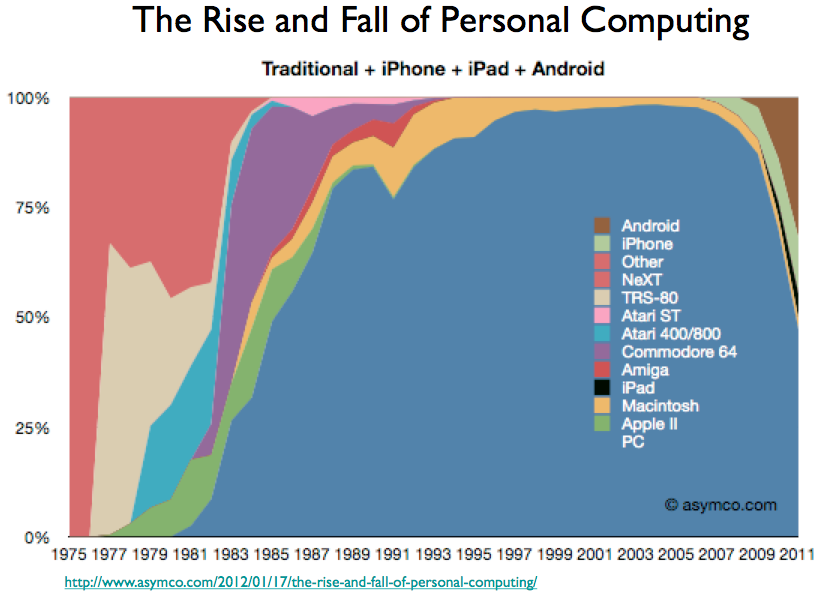
- The Rise and Fall of PCs — use this slide of market share over time by device whenever you need to talk about the “post-PC age”. (via dataisugly subreddit)
"automation" entries

Mesh networking extends IoT reach
A suitable network topology for building automation.
 Editor’s note: this article is part of a series exploring the role of networking in the Internet of Things.
Editor’s note: this article is part of a series exploring the role of networking in the Internet of Things.
Today we are going to consider the attributes of wireless mesh networking, particularly in the context of our building monitoring and energy application.
A host of new mesh networking technologies came upon the scene in the mid-2000s through start-up ventures such as Millennial Net, Ember, Dust Networks, and others. The mesh network topology is ideally suited to provide broad area coverage for low-power, low-data rate applications found in application areas like industrial automation, home and commercial building automation, medical monitoring, and agriculture.

Business models that make the Internet of Things feasible
The bid for widespread home use may drive technical improvements.
For some people, it’s too early to plan mass consumerization of the Internet of Things. Developers are contentedly tinkering with Arduinos and clip cables, demonstrating cool one-off applications. We know that home automation can save energy, keep the elderly and disabled independent, and make life better for a lot of people. But no one seems sure how to realize this goal, outside of security systems and a few high-end items for luxury markets (like the Nest devices, now being integrated into Google’s grand plan).
But what if the willful creation of a mass consumer market could make the technology even better? Perhaps the Internet of Things needs a consumer focus to achieve its potential. This view was illuminated for me through a couple recent talks with Mike Harris, CEO of the home automation software platform Zonoff.

Four short links: 19 March 2014
Legal Automata, Invasive Valley, Feature Creep, and Device Market Share
{kind=link}

Podcast: automation and an abundance-oriented economy
Jim Stogdill, Jon Bruner and Jenn Webb discuss James Burke, ninja homes, IoT standards and robots.
What happens if emerging technology and automation result in a world of abundance, where anyone at anytime can produce anything they need and there’s no need for jobs? In his recent Strata keynote, James Burke warned that society is not prepared for scarcity (and the value it brings) to be a thing of the past — an eventuality Burke predicts will occur in the next 40 years or so. This topic kicks off a discussion between Jim Stogdill, Jon Bruner and myself that we recorded while at Strata.
Link fodder from our chat includes:
- James Burke.
- Roundtable with James Burke, which Alistair Croll aptly described as the “best coffee break ever.”
- Kurt Vonnegut’s Player Piano.
- Norbert Wiener’s The Human Use Of Human Beings: Cybernetics And Society
- Ninja homes.
- Stewart Brand’s How Buildings Learn: What Happens After They’re Built.
- Why Solid, why now?
- Solid: Local in Boston — and upcoming in San Francisco.
- MarkForged carbon fiber 3D printer.
- Rethink Robotics.
- Ryan Cunningham’s Strata session
Subscribe to the O’Reilly Radar Podcast through iTunes, SoundCloud, or directly through our podcast’s RSS feed.
 If you liked this article, you might be interested in a new report, “Building a Solid World,” that explores the key trends and developments that are accelerating the growth of a software-enhanced, networked physical world. (Download the free report.)
If you liked this article, you might be interested in a new report, “Building a Solid World,” that explores the key trends and developments that are accelerating the growth of a software-enhanced, networked physical world. (Download the free report.)

The technology and jobs debate raises complex questions
Doug Hill, James Bessen and Jim Stogdill continue discussing the impact of automation.
Editor’s note: Doug Hill and I recently had a conversation here on Radar about the impact of automation on jobs. In one of our exchanges, Doug mentioned a piece by James Bessen. James reached out to me and was kind enough to provide a response. What follows is their exchange.
JAMES BESSEN: I agree, Doug, that we cannot dismiss the concerns that technology might cause massive unemployment just because technology did not do this in the past. However, in the past, people also predicted that machines would cause mass unemployment. It might be helpful to understand why this didn’t happen in the past and to ask if anything today is fundamentally different.
Many people make a simple argument: 1) they observe that machines can perform job tasks and 2) they conclude that therefore humans will lose their jobs. I argued that this logic is too simple. During the 19th century, machines took more than 98% of the labor needed to weave a yard of cloth. But the number of weavers actually grew because the lower price of cloth increased demand. This is why, contrary to Marx, machines did not create mass unemployment. Read more…
Trope or fact? Technology creates more jobs than it destroys
Will automation beget a jobless wasteland or more stimulating, creative employment? That's up for debate.
Editor’s note: We’re trying something new here. I read this back-and-forth exchange between Malcolm Gladwell and Bill Simmons, and decided we should give it a try. Or, more accurately, since we’re already having plenty of back-and-forth email exchanges like that, we just need to start publishing them. My friend Doug Hill, author of Not So Fast: Thinking Twice About Technology, agreed to be a guinea pig and chat with me about a subject that’s on both of our minds (and a lot of other people’s): technology and the jobless recovery. We’ll be diving into this topic again next week in a debate hosted at Strata. This post was lightly edited on 2/6/14 for clarity.
STOGDILL: I saw this Tweet over the holidays while I was reading your book. I mean, I literally got distracted by this tweet while I was reading your book:
Techno-utopian vision; bully for the economy, still not clear on jobs and wealth distribution. http://t.co/kPc8tfp17e cc /@jstogdill
— Ari Gesher (@alephbass) January 3, 2014
It felt like a natural moment of irony that I had to share with you. In the article Ari Gesher references in his Tweet, Vivek Whadwa obviously has an optimistic point of view, and Gesher was right to call out the inconsistency of his claims with our jobless recovery. I also recently read George Packer’s The Unwinding, his enlightening and disturbing look at the human stories behind our current malaise, and frankly it seems to better reflect the truth on the ground, at least if you get outside of the big five metro areas. But I suspect not a lot of techno optimists are spending time in places that won’t get 4G LTE for another year or two. Read more…

Upward Mobility: Your phone is your robot’s best friend
Rosie the Robot may feel more comfortable talking to Siri than to you
Recently, Glenn Martin wrote an article describing how robotics in moving out of the factory and into the house. And while Glenn restricted himself mainly to the type of robots that pop into your head when someone says the word (either the anthropomorphic variety or the industrial flavor), the reality is that there are a lot of robots already in the hands of consumers, although it might take a moment to recognize them as such.
I’m speaking of drones, and especially quadcopters, which are proliferating at an enormous rate, and are being used to do everything from documenting a cool skateboard move to creating a breathtaking overflight of a horrific disaster site.

Why feedback?
Maintaining a desired behavior
In two previous posts (Part 1 and Part 2) we introduced the idea of feedback control. The basic idea is that we can keep a system (any system!) on track, by constantly monitoring its actual behavior, so that we can apply corrective actions to the system’s input, to “nudge” it back on target, if it ever begins to go astray.
This begs the question: Why should we, as programmers, software engineers, and system administrator care? What’s in it for us?

Making Systems Operable
Velocity 2013 Speaker Series
There’s an old joke about the aviation cockpit of the future that it will contain just a pilot and a dog. The pilot will be there to watch the automation. The dog will be there to bite the pilot if he tries to touch anything.
Although they will all deny it, the majority of modern IT developers have exactly this view of automation: the system is designed to be self regulating and operators are there to watch it, not to operate it. The result is current systems are often inoperable, i.e. systems they cannot be effectively operated because their functions and capacities are hidden or inaccessible.
The conceit in the pilot-and-the-dog joke is that modern systems do not require operation, that they are autonomous. Whenever these systems are exhibited, our attention is drawn to their autonomous features. But there are no systems that actually function without operators. Even when we claim they are “unmanned”, all important systems have operators who are intimately involved in their function: UAV’s are piloted, the Mars rover is driven, the satellites are managed, surgical robots are manipulated, insulin pumps are programmed. We do not see these activities–many are performed by workers who remain anonymous–but we depend on them.

Sharing is a competitive advantage
Why the Velocity conference is coming to New York.
In October, we’re bringing our Velocity conference to New York for the first time. Let’s face it, a company expanding its conference to other locations isn’t anything that unique. And given the thriving startup scene in New York, there’s no real surprise we’d like to have a presence there, either. In that sense, we’ll be doing what we’ve already been doing for years with the Velocity conference in California: sharing expert knowledge about the skills and technologies that are critical for building scalable, resilient, high-availability websites and services.
But there’s an even more compelling reason we’re looking to New York: the finance industry. We’d be foolish and remiss if we acted like it didn’t factor in to our decision, and that we didn’t also share some common concerns, especially on the operational side of things. The Velocity community spends a great deal of time navigating significant operational realities — infrastructure, cost, risk, failures, resiliency; we have a great deal to share with people working in finance, and I’d wager, a great deal to learn in return. If Google or Amazon go down, they lose money. (I’m not saying this is a good thing, mind you.) When a “technical glitch” occurs in financial service systems, we get flash crashes, a complete suspension of the Nasdaq, and whatever else comes next — all with potentially catastrophic outcomes. Read more…