"bdas" entries

Interface Languages and Feature Discovery
It's easier to "discover" features with tools that have broad coverage of the data science workflow
Here are a few more observations based on conversations I had during the just concluded Strata Santa Clara conference.
Interface languages: Python, R, SQL (and Scala)
This is a great time to be a data scientist or data engineer who relies on Python or R. For starters there are developer tools that simplify setup, package installation, and provide user interfaces designed to boost productivity (RStudio, Continuum, Enthought, Sense).
Increasingly, Python and R users can write the same code and run it against many different execution1 engines. Over time the interface languages will remain constant but the execution engines will evolve or even get replaced. Specifically there are now many tools that target Python and R users interested in implementations of algorithms that scale to large data sets (e.g., GraphLab, wise.io, Adatao, H20, Skytree, Revolution R). Interfaces for popular engines like Hadoop and Apache Spark are also available – PySpark users can access algorithms in MLlib, SparkR users can use existing R packages.
In addition many of these new frameworks go out of their way to ease the transition for Python and R users. wise.io “… bindings follow the Scikit-Learn conventions”, and as I noted in a recent post, with SFrames and Notebooks GraphLab, Inc. built components2 that are easy for Python users to learn.
Big Data systems are making a difference in the fight against cancer
Open source, distributed computing tools speedup an important processing pipeline for genomics data
As open source, big data tools enter the early stages of maturation, data engineers and data scientists will have many opportunities to use them to “work on stuff that matters”. Along those lines, computational biology and medicine are areas where skilled data professionals are already beginning to make an impact. I recently came across a compelling open source project from UC Berkeley’s AMPLab: ADAM is a processing engine and set of formats for genomics data.
Second-generation sequencing machines produce more detailed and thus much larger files for analysis (250+ GB file for each person). Existing data formats and tools are optimized for single-server processing and do not easily scale out. ADAM uses distributed computing tools and techniques to speedup key stages of the variant processing pipeline (including sorting and deduping):
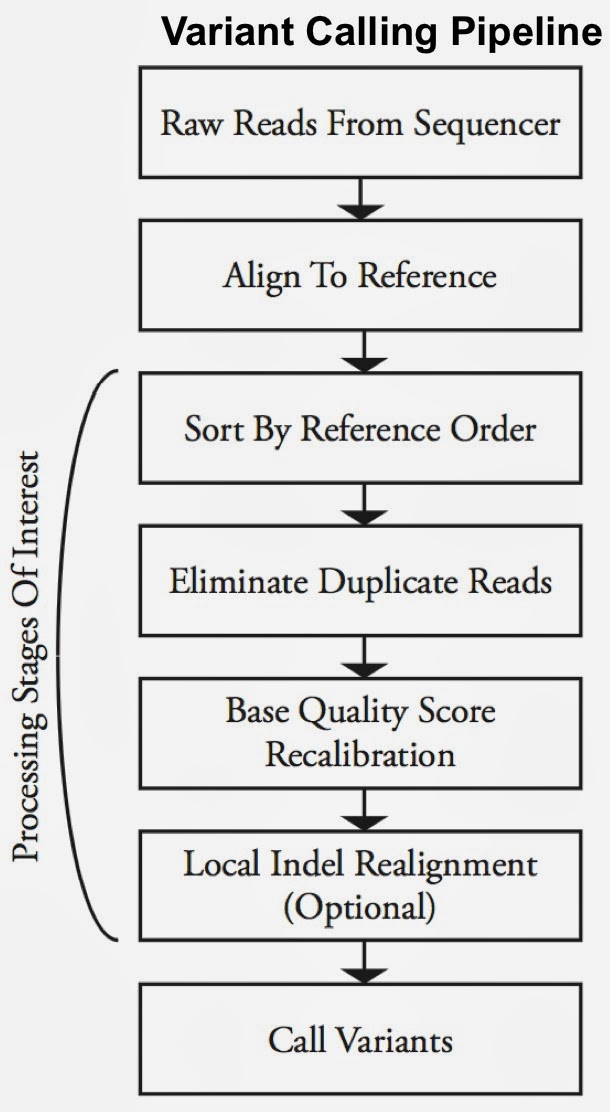
Very early on the designers of ADAM realized that a well-designed data schema (that specifies the representation of data when it is accessed) was key to having a system that could leverage existing big data tools. The ADAM format uses the Apache Avro data serialization system and comes with a human-readable schema that can be accessed using many programming languages (including C/C++/C#, Java/Scala, php, Python, Ruby). ADAM also includes a data format/access API implemented on top of Apache Avro and Parquet, and a data transformation API implemented on top of Apache Spark. Because it’s built with widely adopted tools, ADAM users can leverage components of the Hadoop (Impala, Hive, MapReduce) and BDAS (Shark, Spark, GraphX, MLbase) stacks for interactive and advanced analytics.
Expanding options for mining streaming data
New tools make it easier for companies to process and mine streaming data sources
Stream processing was in the minds of a few people that I ran into over the past week. A combination of new systems, deployment tools, and enhancements to existing frameworks, are behind the recent chatter. Through a combination of simpler deployment tools, programming interfaces, and libraries, recently released tools make it easier for companies to process and mine streaming data sources.
Of the distributed stream processing systems that are part of the Hadoop ecosystem0, Storm is by far the most widely used (more on Storm below). I’ve written about Samza, a new framework from the team that developed Kafka (an extremely popular messaging system). Many companies who use Spark express interest in using Spark Streaming (many have already done so). Spark Streaming is distributed, fault-tolerant, stateful, and boosts programmer productivity (the same code used for batch processing can, with minor tweaks, be used for realtime computations). But it targets applications that are in the “second-scale latencies”. Both Spark Streaming and Samza have their share of adherents and I expect that they’ll both start gaining deployments in 2014.

Behind the Scenes of the First Spark Summit
How it All Started
Spark is a popular open source cluster computing engine for Big Data analytics and a central component of the Berkeley Data Analytics Stack (BDAS). It started as a research project in the UC Berkeley AMPLab and was developed with a focus on attracting production users as well as a diverse community of open source contributors. A community quickly began to grow around Spark, even as a young project in the AMPLab. Before long, this community began gathering at monthly meetups and using mailing lists to discuss development efforts and share their experiences using Spark. More recently the project entered the Apache Incubator.
This year, the core Spark team spun out of the AMPLab to found Databricks, a startup that is using Spark to build next-generation software for analyzing and extracting value from data. At Databricks, we are dedicated to the success of the Spark project and are excited to see the community growing rapidly. This growth demonstrates the need for a larger event that brings the entire community together beyond the meetups. Thus we began planning the first Spark Summit. The Summit will be structured like a super-sized meetup. Meetups typically consist of a single talk, a single sponsor, and dozens of attendees, whereas the Summit will consist of 30 talks, 18 sponsors, hundreds of attendees, and a full day of training exercises.
We understand that an open source project is only as successful as its underlying community. Therefore, we want the Summit to be a community driven event.
Behind the Scenes with the Summit Ops and the Program Committee
The first thing we did was bring in a third-party event producer with a track record of creating high quality open source community events. By separating out the event production we allowed all of the community leaders to share ownership of the technical portion of the event. For example, instead of inviting speakers directly, we hosted an open call for talk submissions. Then we assembled a Program Committee consisting of representatives from 12 of the leading organizations in the Spark community. Finally, the PC members voted on all of the talk submissions to decide the final summit agenda.
The event has been funded by assembling a sponsor network consisting of organizations within the community. With sponsors that are driving the development of the platform, the summit will be an environment that facilitates connections between developers with Spark skills and organizations searching for such developers. We decided that Databricks would participate in the Summit as a peer in this sponsor network.
Day-Long Immersions and Deep Dives at Strata Santa Clara 2014
Tutorials for designers, data scientists, data engineers, and managers
As the Program Development Director for Strata Santa Clara 2014, I am pleased to announce that the tutorial session descriptions are now live. We’re pleased to offer several day-long immersions including the popular Data Driven Business Day and Hardcore Data Science tracks. We curated these topics as we wanted to appeal to a broad range of attendees including business users and managers, designers, data analysts/scientists, and data engineers. In the coming months we’ll have a series of guest posts from many of the instructors and communities behind the tutorials.
Analytics for Business Users
We’re offering a series of data intensive tutorials for non-programmers. John Foreman will use spreadsheets to demonstrate how data science techniques work step-by-step – a topic that should appeal to those tasked with advanced business analysis. Grammar of Graphics author, SYSTAT creator, and noted Statistician Leland Wilkinson, will teach an introductory course on analytics using an innovative expert system he helped build.
Data Science essentials
Scalding – a Scala API for Cascading – is one of the most popular open source projects in the Hadoop ecosystem. Vitaly Gordon will lead a hands-on tutorial on how to use Scalding to put together effective data processing workflows. Data analysts have long lamented the amount of time they spend on data wrangling. But what if you had access to tools and best practices that would make data wrangling less tedious? That’s exactly the tutorial that distinguished Professors and Trifacta co-founders, Joe Hellerstein and Jeff Heer, are offering.
The co-founders of Datascope Analytics are offering a glimpse into how they help clients identify the appropriate problem or opportunity to focus on by using design thinking (see the recent Datascope/IDEO post on Design Thinking and Data Science). We’re also happy to reprise the popular (Strata Santa Clara 2013) d3.js tutorial by Scott Murray.
How companies are using Spark
The inaugural Spark Summit will feature a wide variety of real-world applications
When an interesting piece of big data technology gets introduced, early1 adopters tend to focus on technical features and capabilities. Applications get built as companies develop confidence that it’s reliable and that it really scales to large data volumes. That seems to be where Spark is today. With over 90 contributors from 25 companies, it has one of the largest developer communities among big data projects (second only to Hadoop MapReduce).

I recently became an advisor to Databricks (a startup commercializing Spark) and a member of the program committee for the inaugural Spark Summit. As I pored over submissions to Spark’s first community gathering, I learned how companies have come to rely on Spark, Shark, and other components of the Berkeley Data Analytics Stack (BDAS). Spark is at that stage where companies are deploying it, and the upcoming Spark Summit in San Francisco will showcase many real-world applications. These applications cut across many domains including advertising, marketing, finance, and academic/scientific research, but can generally be grouped into the following categories:
Data processing workflows: ETL and Data Wrangling
Many companies rely on a wide variety of data sources for their analytic products. That means cleaning, transforming, and fusing (unstructured) external data with internal data sources. Many companies – particularly startups – use Spark for these types of data processing workflows. There are even companies that have created simple user interfaces that open up batch data processing tasks to non-programmers.
Databricks aims to build next-generation analytic tools for Big Data
A new startup will accelerate the maturation of the Berkeley Data Analytics Stack
Key technologists behind the Berkeley Data Analytics Stack (BDAS) have launched a company that will build software – centered around Apache Spark and Shark – for analyzing big data. Details of their product and strategy are sparse, as the company is operating in stealth mode. But through conversations with the founders of Databricks, I’ve learned that they’ll be building general purpose analytic tools that can leverage HDFS, YARN, as well as other components of BDAS.
It will be interesting to see how the team transitions to the corporate world. Their Series A funding round of $14M is being led by Andreessen Horowitz. The board will be composed of Ben Horowitz, Scott Shenker, Matei Zaharia, and Ion Stoica.
Running batch and long-running, highly available service jobs on the same cluster
Moving different workloads and frameworks onto the same collection of machines increases efficiency and ROI
As organizations increasingly rely on large computing clusters, tools for leveraging and efficiently managing compute resources become critical. Specifically, tools that allow multiple services and frameworks run on the same cluster can significantly increase utilization and efficiency. Schedulers1 take into account policies and workloads to match jobs with appropriate resources (e.g., memory, storage, processing power) in a large compute cluster. With the help of schedulers, end users begin thinking of a large cluster as a single resource (like “a laptop”) that can be used to run different frameworks (e.g., Spark, Storm, Ruby on Rails, etc.).
Multi-tenancy and efficient utilization translates into improved ROI. Google’s scheduler, Borg, has been in production for many years and has led to substantial savings2. The company’s clusters handle a variety of workloads that can be roughly grouped into batch (compute something, then finish) and services (web or infrastructure services like BigTable). Researchers recently examined traces from several Google clusters and observed that while “batch jobs” accounted for 80% of all jobs, “long service jobs” utilize 55-60% of resources.
There are other benefits of multi-tenancy. Being able to run analytics (batch, streaming) and long running services (e.g., web applications) on the same cluster significantly lowers latency3, opening up the possibility for real-time, analytic applications. Bake-offs can be done more effectively as competing tools, versions, and frameworks can be deployed on the same cluster. Data scientists and production engineers leverage the same compute resources, making it easier for teams to work together across the analytic lifecycle. An additional benefit is that data science teams learn to build products and services that factor in efficient utilization and availability.
Mesos, Chronos, and Marathon
Apache Mesos is a popular open source scheduler that originated from UC Berkeley’s AMPlab. Mesos is based on features in modern kernels for resource isolation (cgroups in Linux). It has been in production for a few years at Twitter4, airbnb5, and many other companies – AMPlab simulations showed Mesos comfortably handling clusters with 30K servers.
Interactive Big Data analysis using approximate answers
As data sizes continue to grow, interactive query systems may start adopting the sampling approach central to BlinkDB
Interactive query analysis for (Hadoop scale data) has recently attracted the attention of many companies and open source developers – some examples include Cloudera’s Impala, Shark, Pivotal’s HAWQ, Hadapt, CitusDB, Phoenix, Sqrrl, Redshift, and BigQuery. These solutions use distributed computing, and a combination of other techniques including data co-partitioning, caching (into main memory), runtime code generation, and columnar storage.
One approach that hasn’t been exploited as much is sampling. By this I mean employing samples to generate approximate answers, and speed up execution. Database researchers have written papers on approximate answers, but few working (downloadable) systems are actually built on this approach.
Approximate query engine from U.C. Berkeley’s Amplab
An interesting, open source database released yesterday0 uses sampling to scale to big data. BlinkDB is a massively-parallel, approximate query system from UC Berkeley’s Amplab. It uses a series of data samples to generate approximate answers. Users compose queries by specifying either error bounds or time constraints, BlinkDB uses sufficiently large random samples to produce answers. Because random samples are stored in memory1, BlinkDB is able to provide interactive response times:

Tightly integrated engines streamline Big Data analysis
A new set of analytic engines make the case for convenience over performance
The choice of tools for data science includes1 factors like scalability, performance, and convenience. A while back I noted that data scientists tended to fall into two camps: those who used an integrated stack, and others who tended to stitch together frameworks. Being able to stick with the same programming language and environment is a definite productivity boost since it requires less setup time and context-switching.
More recently I highlighted the emergence of composable analytic engines, that leverage data stored in HDFS (or HBase and Accumulo). These engines may not be the fastest available, but they scale to data sizes that cover most workloads, and most importantly they can operate on data stored in popular distributed data stores. The fastest and most complete set of algorithms will still come in handy, but I suspect that users will opt for slightly slower2, but more convenient tools, for many routine analytic tasks.