"Big Data and Artificial Intelligence: Intelligence Matters" entries

Small brains, big data
How neuroscience is benefiting from distributed computing — and how computing might learn from neuroscience.
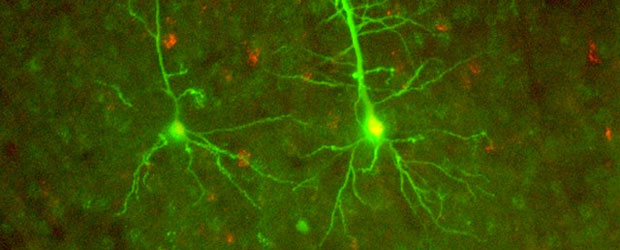
When we think about big data, we usually think about the web: the billions of users of social media, the sensors on millions of mobile phones, the thousands of contributions to Wikipedia, and so forth. Due to recent innovations, web-scale data can now also come from a camera pointed at a small, but extremely complex object: the brain. New progress in distributed computing is changing how neuroscientists work with the resulting data — and may, in the process, change how we think about computation. Read more…

In search of a model for modeling intelligence
True artificial intelligence will require rich models that incorporate real-world phenomena.

An orrery, a runnable model of the solar system that allows us to make predictions. Photo: Wikimedia Commons.
In my last post, we saw that AI means a lot of things to a lot of people. These dueling definitions each have a deep history — ok fine, baggage — that has massed and layered over time. While they’re all legitimate, they share a common weakness: each one can apply perfectly well to a system that is not particularly intelligent. As just one example, the chatbot that was recently touted as having passed the Turing test is certainly an interlocutor (of sorts), but it was widely criticized as not containing any significant intelligence.
Let’s ask a different question instead: What criteria must any system meet in order to achieve intelligence — whether an animal, a smart robot, a big-data cruncher, or something else entirely? Read more…

How to build and run your first deep learning network
Step-by-step instruction on training your own neural network.

When I first became interested in using deep learning for computer vision I found it hard to get started. There were only a couple of open source projects available, they had little documentation, were very experimental, and relied on a lot of tricky-to-install dependencies. A lot of new projects have appeared since, but they’re still aimed at vision researchers, so you’ll still hit a lot of the same obstacles if you’re approaching them from outside the field.
In this article — and the accompanying webcast — I’m going to show you how to run a pre-built network, and then take you through the steps of training your own. I’ve listed the steps I followed to set up everything toward the end of the article, but because the process is so involved, I recommend you download a Vagrant virtual machine that I’ve pre-loaded with everything you need. This VM lets us skip over all the installation headaches and focus on building and running the neural networks. Read more…
What is deep learning, and why should you care?
Announcing a new series delving into deep learning and the inner workings of neural networks.

Editor’s note: this post is part of our Intelligence Matters investigation.
When I first ran across the results in the Kaggle image-recognition competitions, I didn’t believe them. I’ve spent years working with machine vision, and the reported accuracy on tricky tasks like distinguishing dogs from cats was beyond anything I’d seen, or imagined I’d see anytime soon. To understand more, I reached out to one of the competitors, Daniel Nouri, and he demonstrated how he used the Decaf open-source project to do so well. Even better, he showed me how he was quickly able to apply it to a whole bunch of other image-recognition problems we had at Jetpac, and produce much better results than my conventional methods.
I’ve never encountered such a big improvement from a technique that was largely unheard of just a couple of years before, so I became obsessed with understanding more. To be able to use it commercially across hundreds of millions of photos, I built my own specialized library to efficiently run prediction on clusters of low-end machines and embedded devices, and I also spent months learning the dark arts of training neural networks. Now I’m keen to share some of what I’ve found, so if you’re curious about what on earth deep learning is, and how it might help you, I’ll be covering the basics in a series of blog posts here on Radar, and in a short upcoming ebook. Read more…
AI’s dueling definitions
Why my understanding of AI is different from yours.

SoftBank’s Pepper, a humanoid robot that takes its surroundings into consideration.
Editor’s note: this post is part of our Intelligence Matters investigation.
Let me start with a secret: I feel self-conscious when I use the terms “AI” and “artificial intelligence.” Sometimes, I’m downright embarrassed by them.
Before I get into why, though, answer this question: what pops into your head when you hear the phrase artificial intelligence?
For the layperson, AI might still conjure HAL’s unblinking red eye, and all the misfortune that ensued when he became so tragically confused. Others jump to the replicants of Blade Runner or more recent movie robots. Those who have been around the field for some time, though, might instead remember the “old days” of AI — whether with nostalgia or a shudder — when intelligence was thought to primarily involve logical reasoning, and truly intelligent machines seemed just a summer’s work away. And for those steeped in today’s big-data-obsessed tech industry, “AI” can seem like nothing more than a high-falutin’ synonym for the machine-learning and predictive-analytics algorithms that are already hard at work optimizing and personalizing the ads we see and the offers we get — it’s the term that gets trotted out when we want to put a high sheen on things. Read more…

Streamlining feature engineering
Researchers and startups are building tools that enable feature discovery.
Why do data scientists spend so much time on data wrangling and data preparation? In many cases it’s because they want access to the best variables with which to build their models. These variables are known as features in machine-learning parlance. For many0 data applications, feature engineering and feature selection are just as (if not more important) than choice of algorithm:
Good features allow a simple model to beat a complex model.
(to paraphrase Alon Halevy, Peter Norvig, and Fernando Pereira)
The terminology can be a bit confusing, but to put things in context one can simplify the data science pipeline to highlight the importance of features:
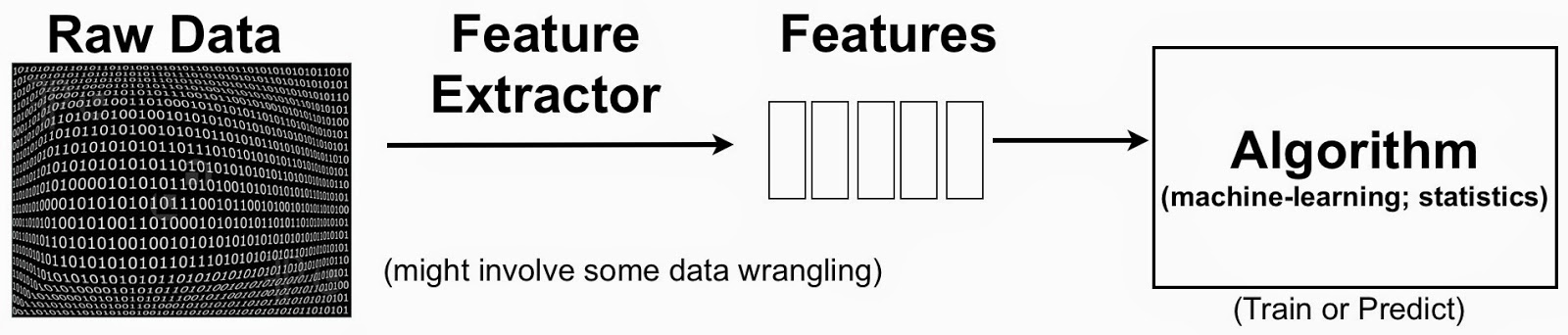
Feature Engineering or the Creation of New Features
A simple example to keep in mind is text mining. One starts with raw text (documents) and extracted features could be individual words or phrases. In this setting, a feature could indicate the frequency of a specific word or phrase. Features1 are then used to classify and cluster documents, or extract topics associated with the raw text. The process usually involves the creation2 of new features (feature engineering) and identifying the most essential ones (feature selection).
Untapped opportunities in AI
Some of AI's viable approaches lie outside the organizational boundaries of Google and other large Internet companies.

Editor’s note: this post is part of an ongoing series exploring developments in artificial intelligence.
Here’s a simple recipe for solving crazy-hard problems with machine intelligence. First, collect huge amounts of training data — probably more than anyone thought sensible or even possible a decade ago. Second, massage and preprocess that data so the key relationships it contains are easily accessible (the jargon here is “feature engineering”). Finally, feed the result into ludicrously high-performance, parallelized implementations of pretty standard machine-learning methods like logistic regression, deep neural networks, and k-means clustering (don’t worry if those names don’t mean anything to you — the point is that they’re widely available in high-quality open source packages).
Google pioneered this formula, applying it to ad placement, machine translation, spam filtering, YouTube recommendations, and even the self-driving car — creating billions of dollars of value in the process. The surprising thing is that Google isn’t made of magic. Instead, mirroring Bruce Scheneier’s surprised conclusion about the NSA in the wake of the Snowden revelations, “its tools are no different from what we have in our world; it’s just better funded.” Read more…
“It works like the brain.” So?
There are many ways a system can be like the brain, but only a fraction of these will prove important.

Editor’s note: this post is part of an ongoing series exploring developments in artificial intelligence.
Here’s a fun drinking game: take a shot every time you find a news article or blog post that describes a new AI system as working or thinking “like the brain.” Here are a few to start you off with a nice buzz; if your reading habits are anything like mine, you’ll never be sober again. Once you start looking for this phrase, you’ll see it everywhere — I think it’s the defining laziness of AI journalism and marketing.
Surely these claims can’t all be true? After all, the brain is an incredibly complex and specific structure, forged in the relentless pressure of millions of years of evolution to be organized just so. We may have a lot of outstanding questions about how it works, but work a certain way it must. Read more…
Welcome to Intelligence Matters
Casting a critical eye on the exciting developments in the world of AI.
Editor’s note: this post was co-authored by Ben Lorica and Roger Magoulas. It’s the kick-off to our Intelligence Matter series.

Siri screenshot.
True AI has been “just around the corner” for 60 years, so why should O’Reilly start covering AI in a big way now? As computing power catches up to scientific and engineering ambitions, and as our ability to learn directly from sensory signals — i.e., big data — increases, intelligent systems are having a real and widespread impact. Every Internet user benefits from these systems today — they sort our email, plan our journeys, answer our questions, and protect us from fraudsters. And, with the Internet of Things, these system have already started to keep our houses and offices comfortable and well-lit, our data centers running more efficiently, our industrial processes humming, and even are driving our cars. Read more…