"business intelligence" entries

Business analysts want access to advanced analytics
Business users are starting to tackle problems that require machine-learning and statistics
I talk with many new companies who build tools for business analysts and other non-technical users. These new tools streamline and simplify important data tasks including interactive analysis (e.g., pivot tables and cohort analysis), interactive visual analysis (as popularized by Tableau and Qlikview), and more recently data preparation. Some of the newer tools scale to large data sets, while others explicitly target small to medium-sized data.
As I noted in a recent post, companies are beginning to build data analysis tools1 that target non-experts. Companies are betting that as business users start interacting with data, they will want to tackle some problems that require advanced analytics. With business analysts far outnumbering data scientists, it makes sense to offload some problems to non-experts2.
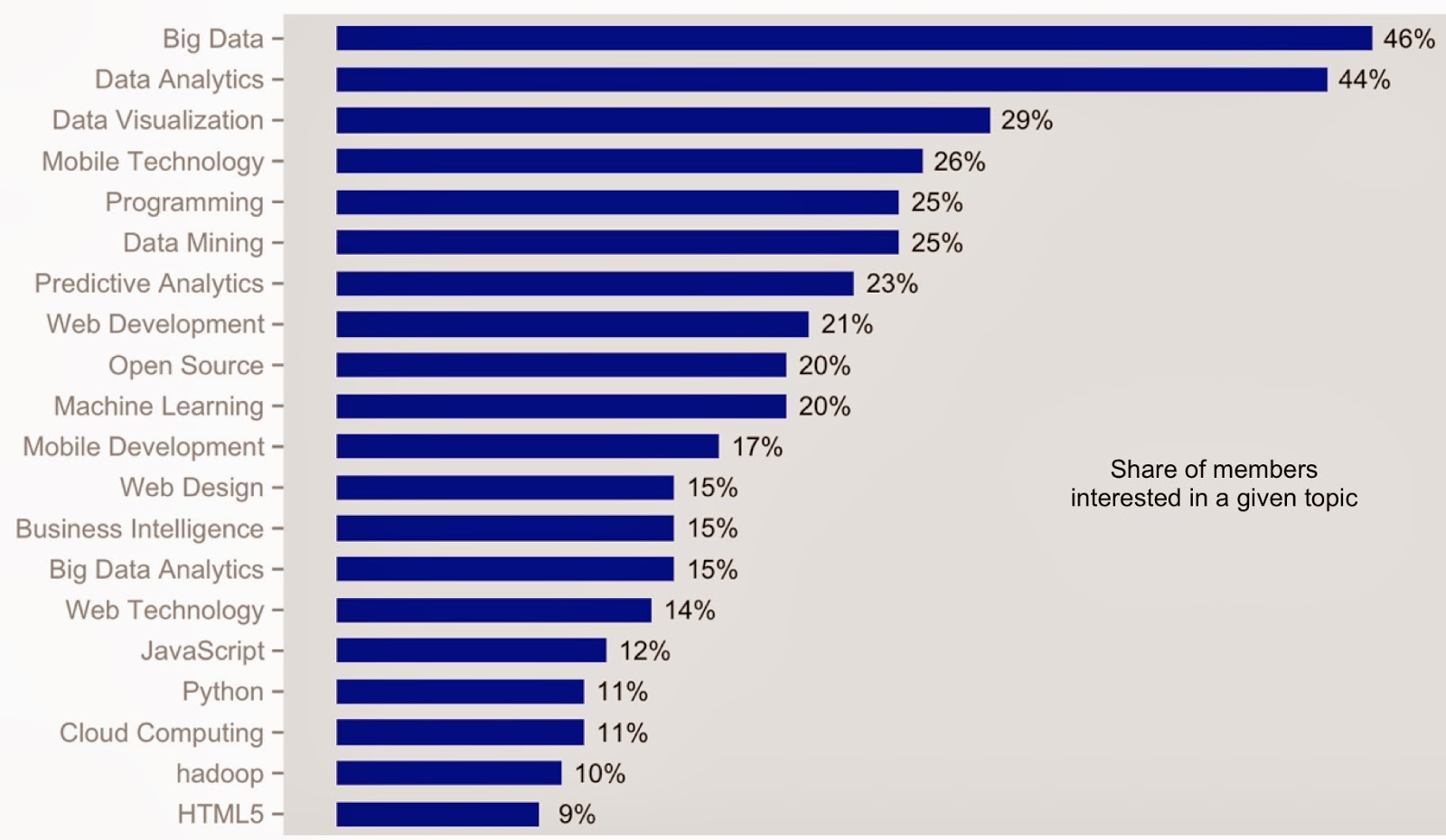
Moreover data seems to support the notion that business users are interested in more complex problems. I recently looked at data3 from 11 large Meetups (in NYC and the SF Bay Area) that target business analysts and business intelligence users. Altogether these Meetups had close to 5,000 active4 members. As you can see in the chart below, business users are interested in topics like machine learning (1 in 5), predictive analytics (1 in 4), and data mining (1 in 4):

Strata Week: Investors embrace Hadoop BI startups
Platfora, Continuuity secure funding; the Internet of Things gets connected; and personal big data needs a national awareness campaign.
Here are a few stories from the data space that caught my attention this week.
Two Hadoop BI startups secure funding
![]() There were a couple notable pieces of investment news this week. Platfora, a startup looking to democratize Hadoop as a business intelligence (BI) tool for everyday business users, announced this week that it has raised $20 million in series B funding, bringing its total funding to $25.7 million, according to a report by Derrick Harris at GigaOm.
There were a couple notable pieces of investment news this week. Platfora, a startup looking to democratize Hadoop as a business intelligence (BI) tool for everyday business users, announced this week that it has raised $20 million in series B funding, bringing its total funding to $25.7 million, according to a report by Derrick Harris at GigaOm.
Harris notes that investors seem to get the technology — CEO Ben Werther told Harris that in this funding round, discussions moved to signed term sheets in just three weeks. Harris writes that the smooth investment experience “probably has something to do with the consensus the company has seen among venture capitalists, who project Hadoop will take about 20 percent of a $30 billion legacy BI market and are looking for the startups with the vision to win that business.”
Platfora faces plenty of well-funded legacy BI competitors, but Werther told Christina Farr at Venture Beat that Platfora’s edge is speed: “People can visualize and ask questions about data within hours. There is no six-month cycle time to make Hadoop amazing.”
In other investment news, Continuuity announced it has secured $10 million in series A funding to further develop AppFabric, its cloud-based platform-as-a-service tool designed to host Hadoop-based BI applications. Alex Wilhelm reports at The Next Web that Continuuity is looking to make AppFabric “the de facto location where developers can move their big data tools from idea to product, without worrying about building their own backend, or fretting about element integration.”
Strata Week: Data mining for votes
Candidates are data mining behind the scenes, data mining gets a PR campaign, Google faces privacy policy issues, and Hadoop and BI.
Here are a few stories from the data space that caught my attention this week.
Presidential candidates are mining your data
Data is playing an unprecedented role in the US presidential election this year. The two presidential campaigns have access to personal voter data “at a scale never before imagined,” reports Charles Duhigg at the New York Times. The candidate camps are using personal data in polling calls, accessing such details as “whether voters may have visited pornography Web sites, have homes in foreclosure, are more prone to drink Michelob Ultra than Corona or have gay friends or enjoy expensive vacations,” Duhigg writes. He reports that both campaigns emphasized they were committed to protecting voter privacy, but notes:
“Officials for both campaigns acknowledge that many of their consultants and vendors draw data from an array of sources — including some the campaigns themselves have not fully scrutinized.”
A Romney campaign official told Duhigg: “You don’t want your analytical efforts to be obvious because voters get creeped out. A lot of what we’re doing is behind the scenes.”
The “behind the scenes” may be enough in itself to creep people out. These sorts of situations are starting to tarnish the image of the consumer data-mining industry, and a Manhattan trade group, the Direct Marketing Association, is launching a public relations campaign — the “Data-Driven Marketing Institute” — to smooth things over before government regulators get involved. Natasha Singer reports at the New York Times:
“According to a statement, the trade group intends to promote such targeted marketing to lawmakers and the public ‘with the goal of preventing needless regulation or enforcement that could severely hamper consumer marketing and stifle innovation’ as well as ‘tamping down unfavorable media attention.’ As part of the campaign, the group plans to finance academic research into the industry’s economic impact, said Linda A. Woolley, the acting chief executive of the Direct Marketing Association.”
One of the biggest issues, Singer notes, is that people want control over their data. Chuck Teller, founder of Catalog Choice, told Singer that in a recent survey conducted by his company, 67% of people responded that they wanted to see the data collected about them by data brokers and 78% said they wanted the ability to opt out of the sale and distribution of that data.

Three kinds of big data
Looking ahead at big data's role in enterprise business intelligence, civil engineering, and customer relationship optimization.
 In the past couple of years, marketers and pundits have spent a lot of time labeling everything “big data.” The reasoning goes something like this:
In the past couple of years, marketers and pundits have spent a lot of time labeling everything “big data.” The reasoning goes something like this:
- Everything is on the Internet.
- The Internet has a lot of data.
- Therefore, everything is big data.
When you have a hammer, everything looks like a nail. When you have a Hadoop deployment, everything looks like big data. And if you’re trying to cloak your company in the mantle of a burgeoning industry, big data will do just fine. But seeing big data everywhere is a sure way to hasten the inevitable fall from the peak of high expectations to the trough of disillusionment.
We saw this with cloud computing. From early idealists saying everything would live in a magical, limitless, free data center to today’s pragmatism about virtualization and infrastructure, we soon took off our rose-colored glasses and put on welding goggles so we could actually build stuff.
So where will big data go to grow up?
Once we get over ourselves and start rolling up our sleeves, I think big data will fall into three major buckets: Enterprise BI, Civil Engineering, and Customer Relationship Optimization. This is where we’ll see most IT spending, most government oversight, and most early adoption in the next few years. Read more…

Why data visualization matters
The best data visualizations expose something new.
Effective data visualizations go beyond aesthetics; they also allow organizations to make quick and correct decisions from massive amounts of information.

Top Stories: November 28-December 2, 2011
Info overload vs. consumption, how big data is shaping business, and why we need the "paperless book."
This week on O'Reilly: Author Clay Johnson explained why information consumption, not overload, is what needs to be managed. Also, Alistair Croll looked at the relationship between business intelligence and big data, and Todd Sattersten made a case for the paperless book.

Building data science teams
Data science teams need people with the skills and curiosity to ask the big questions.
A data science team needs people with the right skills and perspectives, and it also requires strong tools, processes, and interaction between the team and the rest of the company.