"data wrangling" entries

Metadata services can lead to performance and organizational improvements
The O’Reilly Data Show podcast: Joe Hellerstein on data wrangling, distributed systems, and metadata services.
Subscribe to the O’Reilly Data Show Podcast to explore the opportunities and techniques driving big data and data science: Stitcher, TuneIn, iTunes, SoundCloud, RSS.

In this episode of the O’Reilly Data Show, I spoke with one of the most popular speakers at Strata+Hadoop World: Joe Hellerstein, professor of Computer Science at UC Berkeley and co-founder/CSO of Trifacta. We talked about his past and current academic research (which spans HCI, databases, and systems), data wrangling, large-scale distributed systems, and his recent work on metadata services.
Data wrangling and preparation
The most interactive tasks that people do with data are essentially data wrangling. You’re changing the form of the data, you’re changing the content of the data, and at the same time you’re trying to evaluate the quality of the data and see if you’re making it the way you want it. … It’s really actually the most immersive interaction that people do with data and it’s very interesting.

Building pipelines to facilitate data analysis
A new operator from the magrittr package makes it easier to use R for data analysis.

In every data analysis, you have to string together many tools. You need tools for data wrangling, visualisation, and modelling to understand what’s going on in your data. To use these tools effectively, you need to be able to easily flow from one tool to the next, focusing on asking and answering questions of the data, not struggling to jam the output from one function into the format needed for the next. Wouldn’t it be nice if the world worked this way! I spend a lot of my time thinking about this problem, and how to make the process of data analysis as fast, effective, and expressive as possible. Today, I want to show you a new technique that I’m particularly excited about.
R, at its heart, is a functional programming language: you do data analysis in R by composing functions. However, the problem with function composition is that a lot of it makes for hard-to-read code. For example, here’s some R code that wrangles flight delay data from New York City in 2013. What does it do? Read more…
Streamlining feature engineering
Researchers and startups are building tools that enable feature discovery.
Why do data scientists spend so much time on data wrangling and data preparation? In many cases it’s because they want access to the best variables with which to build their models. These variables are known as features in machine-learning parlance. For many0 data applications, feature engineering and feature selection are just as (if not more important) than choice of algorithm:
Good features allow a simple model to beat a complex model.
(to paraphrase Alon Halevy, Peter Norvig, and Fernando Pereira)
The terminology can be a bit confusing, but to put things in context one can simplify the data science pipeline to highlight the importance of features:
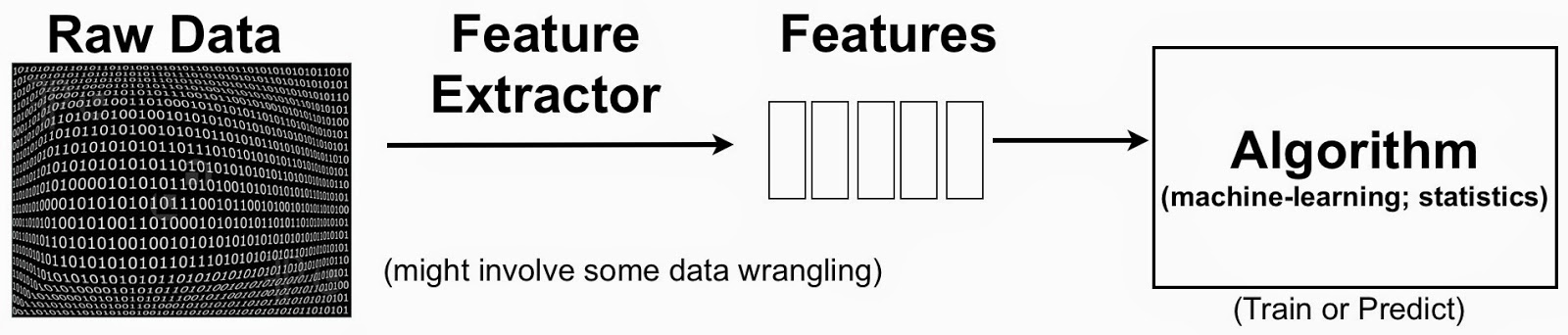
Feature Engineering or the Creation of New Features
A simple example to keep in mind is text mining. One starts with raw text (documents) and extracted features could be individual words or phrases. In this setting, a feature could indicate the frequency of a specific word or phrase. Features1 are then used to classify and cluster documents, or extract topics associated with the raw text. The process usually involves the creation2 of new features (feature engineering) and identifying the most essential ones (feature selection).