"datashow" entries

Data science makes an impact on Wall Street
The O'Reilly Data Show Podcast: Gary Kazantsev on how big data and data science are making a difference in finance.
Learn more about Next:Money, O’Reilly’s conference focused on the fundamental transformation taking place in the finance industry.
 Having started my career in industry, working on problems in finance, I’ve always appreciated how challenging it is to build consistently profitable systems in this extremely competitive domain. When I served as quant at a hedge fund in the late 1990s and early 2000s, I worked primarily with price data (time-series). I quickly found that it was difficult to find and sustain profitable trading strategies that leveraged data sources that everyone else in the industry examined exhaustively. In the early-to-mid 2000s the hedge fund industry began incorporating many more data sources, and today you’re likely to find many finance industry professionals at big data and data science events like Strata + Hadoop World.
Having started my career in industry, working on problems in finance, I’ve always appreciated how challenging it is to build consistently profitable systems in this extremely competitive domain. When I served as quant at a hedge fund in the late 1990s and early 2000s, I worked primarily with price data (time-series). I quickly found that it was difficult to find and sustain profitable trading strategies that leveraged data sources that everyone else in the industry examined exhaustively. In the early-to-mid 2000s the hedge fund industry began incorporating many more data sources, and today you’re likely to find many finance industry professionals at big data and data science events like Strata + Hadoop World.
During the latest episode of the O’Reilly Data Show Podcast, I had a great conversation with one of the leading data scientists in finance: Gary Kazantsev runs the R&D Machine Learning group at Bloomberg LP. As a former quant, I wanted to know the types of problems Kazantsev and his group work on, and the tools and techniques they’ve found useful. We also talked about data science, data engineering, and recruiting data professionals for Wall Street. Read more…
The tensor renaissance in data science
The O'Reilly Data Show Podcast: Anima Anandkumar on tensor decomposition techniques for machine learning.

After sitting in on UC Irvine Professor Anima Anandkumar’s Strata + Hadoop World 2015 in San Jose presentation, I wrote a post urging the data community to build tensor decomposition libraries for data science. The feedback I’ve gotten from readers has been extremely positive. During the latest episode of the O’Reilly Data Show Podcast, I sat down with Anandkumar to talk about tensor decomposition, machine learning, and the data science program at UC Irvine.
Modeling higher-order relationships
The natural question is: why use tensors when (large) matrices can already be challenging to work with? Proponents are quick to point out that tensors can model more complex relationships. Anandkumar explains:
Tensors are higher order generalizations of matrices. While matrices are two-dimensional arrays consisting of rows and columns, tensors are now multi-dimensional arrays. … For instance, you can picture tensors as a three-dimensional cube. In fact, I have here on my desk a Rubik’s Cube, and sometimes I use it to get a better understanding when I think about tensors. … One of the biggest use of tensors is for representing higher order relationships. … If you want to only represent pair-wise relationships, say co-occurrence of every pair of words in a set of documents, then a matrix suffices. On the other hand, if you want to learn the probability of a range of triplets of words, then we need a tensor to record such relationships. These kinds of higher order relationships are not only important for text, but also, say, for social network analysis. You want to learn not only about who is immediate friends with whom, but, say, who is friends of friends of friends of someone, and so on. Tensors, as a whole, can represent much richer data structures than matrices.
Coming full circle with Bigtable and HBase
The O'Reilly Data Show Podcast: Michael Stack on HBase past, present, and future.

Subscribe to the O’Reilly Data Show to explore the opportunities and techniques driving big data and data science.
At least once a year, I sit down with Michael Stack, engineer at Cloudera, to get an update on Apache HBase and the annual user conference, HBasecon. Stack has a great perspective, as he has been part of HBase since its inception. As former project leader, he remains a key contributor and evangelist, and one of the organizers of HBasecon.
In the beginning: Search and Bigtable
During the latest episode of the O’Reilly Data Show Podcast, I decided to broaden our conversation to include the beginnings of the very popular Apache HBase project. Stack reminded me that in the early days much of the big data community in the SF Bay Area was centered around search technologies, such as HBase. In particular, HBase was inspired by work out of Google (Bigtable), and the early engineers had ties to projects out of the Internet Archive:
At the time, I was working at the Internet Archive, and I was working on crawlers and search. The Bigtable paper looked really interesting to us because the archive, as you know, we used to host — or still do — the Wayback Machine. The Wayback Machine is a picture of the Web that goes back to 1998, and you could look at the Web at any particular time. What pages looked liked at a particular time. Bigtable was very interesting at the Internet Archive because it had this time dimension.
…
A group had started up to talk about the possibility of implementing a Bigtable clone. It was centered at a place called Powerset, a startup that was in San Francisco back then. That was about doing a search, so I went and talked to them. They said, ‘Come on over and we’ll make a space for doing a Bigtable clone.’ They had a very intricate search pipeline, and it was based on early Amazon AWS, and every time they started up their pipeline, they’d get a phone call from Amazon saying, ‘Please stop whatever it is you’re doing.’ … The first engineer would be a fellow called Jim Kellerman. The actual first 30 classes came from Mike Cafarella. He was instrumental in getting the first versions of Hadoop going. He was hanging around Apache Nutch at the time. … Doug [Cutting] used to work at the Internet archive, and the first actual versions of Hadoop were run on racks at the Internet archive. Doug was working on fulltext search. Then he moved on to go to Yahoo, to work on Hadoop full time.
Building big data systems in academia and industry
The O'Reilly Data Show Podcast: Mikio Braun on stream processing, academic research, and training.
Mikio Braun is a machine learning researcher who also enjoys software engineering. We first met when he co-founded a real-time analytics company called streamdrill. Since then, I’ve always had great conversations with him on many topics in the data space. He gave one of the best-attended sessions at Strata + Hadoop World in Barcelona last year on some of his work at streamdrill.
I recently sat down with Braun for the latest episode of the O’Reilly Data Show Podcast, and we talked about machine learning, stream processing and analytics, his recent foray into data science training, and academia versus industry (his interests are a bit on the “applied” side, but he enjoys both).
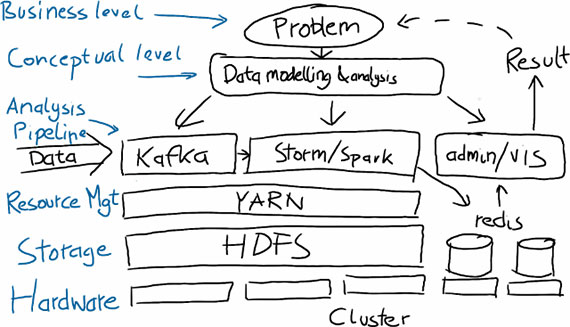
An example of a big data solution. Source: Mikio Braun, used with permission.
Redefining power distribution using big data
The O'Reilly Data Show Podcast: Erich Nachbar on testing and deploying open source, distributed computing components.
 When I first hear of a new open source project that might help me solve a problem, the first thing I do is ask around to see if any of my friends have tested it. Sometimes, however, the early descriptions sound so promising that I just jump right in and try it myself — and in a few cases, I transition immediately (this was certainly the case for Spark).
When I first hear of a new open source project that might help me solve a problem, the first thing I do is ask around to see if any of my friends have tested it. Sometimes, however, the early descriptions sound so promising that I just jump right in and try it myself — and in a few cases, I transition immediately (this was certainly the case for Spark).
I recently had a conversation with Erich Nachbar, founder and CTO of Virtual Power Systems, and one of the earliest adopters of Spark. In the early days of Spark, Nachbar was CTO of Quantifind, a startup often cited by the creators of Spark as one of the first “production deployments.” On the latest episode of the O’Reilly Data Show Podcast, we talk about the ease with which Nachbar integrates new open source components into existing infrastructure, his contributions to Mesos, and his new “software-defined power distribution” startup.
Ecosystem of open source big data technologies
When evaluating a new software component, nothing beats testing it against workloads that mimic your own. Nachbar has had the luxury of working in organizations where introducing new components isn’t subject to multiple levels of decision-making. But, as he notes, everything starts with testing things for yourself:
“I have sort of my mini test suite…If it’s a data store, I would just essentially hook it up to something that’s readily available, some feed like a Twitter fire hose, and then just let it be bombarded with data, and by now, it’s my simple benchmark to know what is acceptable and what isn’t for the machine…I think if more people, instead of reading papers and paying people to tell them how good or bad things are, would actually set aside a day and try it, I think they would learn a lot more about the system than just reading about it and theorizing about the system. Read more…
Turning Ph.D.s into industrial data scientists and data engineers
The O'Reilly Data Show Podcast: Angie Ma on building a finishing school for science and engineering doctorates.

Editor’s note: The ASI will offer a two-day intensive course, Practical Machine Learning, at Strata + Hadoop World in London in May.
Back when I was considering leaving academia, the popular exit route was financial engineering. Many science and engineering Ph.D.s ended up in big Wall Street banks; I chose to be the lead quant at a small hedge fund — it was a natural choice for many of us. Financial engineering was topically close to my academic interests, and working with traders meant access to resources and interesting problems.
Today, there are many more options for people with science and engineering doctorates. A few organizations take science and engineering Ph.D.s, and over the course of 8-12 weeks, prepare them to join the ranks of industrial data scientists and data engineers.
I recently sat down with Angie Ma, co-founder and president of ASI, a London startup that runs a carefully structured “finishing school” for science and engineering doctorates. We talked about how Angie and her co-founders (all ex-physicists) arrived at the concept of the ASI, the structure of their training programs, and the data and startup scene in the UK. [Full disclosure: I’m an advisor to the ASI.] Read more…
Topic models: Past, present, and future
The O'Reilly Data Show Podcast: David Blei, co-creator of one of the most popular tools in text mining and machine learning.

I don’t remember when I first came across topic models, but I do remember being an early proponent of them in industry. I came to appreciate how useful they were for exploring and navigating large amounts of unstructured text, and was able to use them, with some success, in consulting projects. When an MCMC algorithm came out, I even cooked up a Java program that I came to rely on (up until Mallet came along).
I recently sat down with David Blei, co-author of the seminal paper on topic models, and who remains one of the leading researchers in the field. We talked about the origins of topic models, their applications, improvements to the underlying algorithms, and his new role in training data scientists at Columbia University.
Generating features for other machine learning tasks
Blei frequently interacts with companies that use ideas from his group’s research projects. He noted that people in industry frequently use topic models for “feature generation.” The added bonus is that topic models produce features that are easy to explain and interpret:
“You might analyze a bunch of New York Times articles for example, and there’ll be an article about sports and business, and you get a representation of that article that says this is an article and it’s about sports and business. Of course, the ideas of sports and business were also discovered by the algorithm, but that representation, it turns out, is also useful for prediction. My understanding when I speak to people at different startup companies and other more established companies is that a lot of technology companies are using topic modeling to generate this representation of documents in terms of the discovered topics, and then using that representation in other algorithms for things like classification or other things.”
Forecasting events, from disease outbreaks to sales to cancer research
The O'Reilly Data Show Podcast: Kira Radinsky on predicting events using machine learning, NLP, and semantic analysis.
Editor’s note: One of the more popular speakers at Strata + Hadoop World, Kira Radinsky was recently profiled in the new O’Reilly Radar report, Women in Data: Cutting-Edge Practitioners and Their Views on Critical Skills, Background, and Education.
When I first took over organizing Hardcore Data Science at Strata + Hadoop World, one of the first speakers I invited was Kira Radinsky. Radinsky had already garnered international recognition for her work forecasting real-world events (disease outbreak, riots, etc.). She’s currently the CTO and co-founder of SalesPredict, a start-up using predictive analytics to “understand who’s ready to buy, who may buy more, and who is likely to churn.”
I recently had a conversation with Radinsky, and she took me through the many techniques and subject domains from her past and present research projects. In grad school, she helped build a predictive system that combined newspaper articles, Wikipedia, and other open data sets. Through fine-tuned semantic analysis and NLP, Radinsky and her collaborators devised new metrics of similarity between events. The techniques she developed for that predictive software system are now the foundation of applications across many areas. Read more…
The evolution of GraphLab
The O'Reilly Data Show Podcast: Carlos Guestrin on the early days of GraphLab and the evolution of GraphLab Create.
I only really started playing around with GraphLab when the companion project GraphChi came onto the scene. By then I’d heard from many avid users and admired how their user conference instantly became a popular San Francisco Bay Area data science event. For this podcast episode, I sat down with Carlos Guestrin, co-founder/CEO of Dato, a start-up launched by the creators of GraphLab. We talked about the early days of GraphLab, the evolution of GraphLab Create, and what’s he’s learned from starting a company.
MATLAB for graphs
Guestrin remains a professor of computer science at the University of Washington, and GraphLab originated when he was still a faculty member at Carnegie Mellon. GraphLab was built by avid MATLAB users who needed to do large scale graphical computations to demonstrate their research results. Guestrin shared some of the backstory:
“I was a professor at Carnegie Mellon for about eight years before I moved to Seattle. A couple of my students, Joey Gonzales and Yucheng Low were working on large scale distributed machine learning algorithms specially with things called graphical models. We tried to implement them to show off the theorems that we had proven. We tried to run those things on top of Hadoop and it was really slow. We ended up writing those algorithms on top of MPI which is a high performance computing library and it was just a pain. It took a long time and it was hard to reproduce the results and the impact it had on us is that writing papers became a pain. We wanted a system for my lab that allowed us to write more papers more quickly. That was the goal. In other words so they could implement this machine learning algorithms more easily, more quickly specifically on graph data which is what we focused on.”
A brief look at data science’s past and future
In this O'Reilly Data Show Podcast: DJ Patil weighs in on a wide range of topics in data science and big data.
Back in 2008, when we were working on what became one of the first papers on big data technologies, one of our first visits was to LinkedIn’s new “data” team. Many of the members of that team went on to build interesting tools and products, and team manager DJ Patil emerged as one of the best-known data scientists. I recently sat down with Patil to talk about his new ebook (written with Hilary Mason) and other topics in data science and big data.
Subscribe to the O’Reilly Data Show Podcast
Here are a few of the topics we touched on:
Proliferation of programs for training and certifying data scientists
Patil and I are both ex-academics who learned learned “data science” in industry. In fact, up until a few years ago one acquired data science skills via “on-the-job training.” But a new job title that catches on usually leads to an explosion of programs (I was around when master’s programs in financial engineering took off). Are these programs the right way to acquire the necessary skills? Read more…