"feature engineering" entries

Bridging the divide: Business users and machine learning experts
The O'Reilly Data Show Podcast: Alice Zheng on feature representations, model evaluation, and machine learning models.
Subscribe to the O’Reilly Data Show Podcast to explore the opportunities and techniques driving big data and data science.
 As tools for advanced analytics become more accessible, data scientist’s roles will evolve. Most media stories emphasize a need for expertise in algorithms and quantitative techniques (machine learning, statistics, probability), and yet the reality is that expertise in advanced algorithms is just one aspect of industrial data science.
As tools for advanced analytics become more accessible, data scientist’s roles will evolve. Most media stories emphasize a need for expertise in algorithms and quantitative techniques (machine learning, statistics, probability), and yet the reality is that expertise in advanced algorithms is just one aspect of industrial data science.
During the latest episode of the O’Reilly Data Show podcast, I sat down with Alice Zheng, one of Strata + Hadoop World’s most popular speakers. She has a gift for explaining complex topics to a broad audience, through presentations and in writing. We talked about her background, techniques for evaluating machine learning models, how much math data scientists need to know, and the art of interacting with business users.
Making machine learning accessible
People who work at getting analytics adopted and deployed learn early on the importance of working with domain/business experts. As excited as I am about the growing number of tools that open up analytics to business users, the interplay between data experts (data scientists, data engineers) and domain experts remains important. In fact, human-in-the-loop systems are being used in many critical data pipelines. Zheng recounts her experience working with business analysts:
It’s not enough to tell someone, “This is done by boosted decision trees, and that’s the best classification algorithm, so just trust me, it works.” As a builder of these applications, you need to understand what the algorithm is doing in order to make it better. As a user who ultimately consumes the results, it can be really frustrating to not understand how they were produced. When we worked with analysts in Windows or in Bing, we were analyzing computer system logs. That’s very difficult for a human being to understand. We definitely had to work with the experts who understood the semantics of the logs in order to make progress. They had to understand what the machine learning algorithms were doing in order to provide useful feedback. Read more…
Streamlining feature engineering
Researchers and startups are building tools that enable feature discovery.
Why do data scientists spend so much time on data wrangling and data preparation? In many cases it’s because they want access to the best variables with which to build their models. These variables are known as features in machine-learning parlance. For many0 data applications, feature engineering and feature selection are just as (if not more important) than choice of algorithm:
Good features allow a simple model to beat a complex model.
(to paraphrase Alon Halevy, Peter Norvig, and Fernando Pereira)
The terminology can be a bit confusing, but to put things in context one can simplify the data science pipeline to highlight the importance of features:
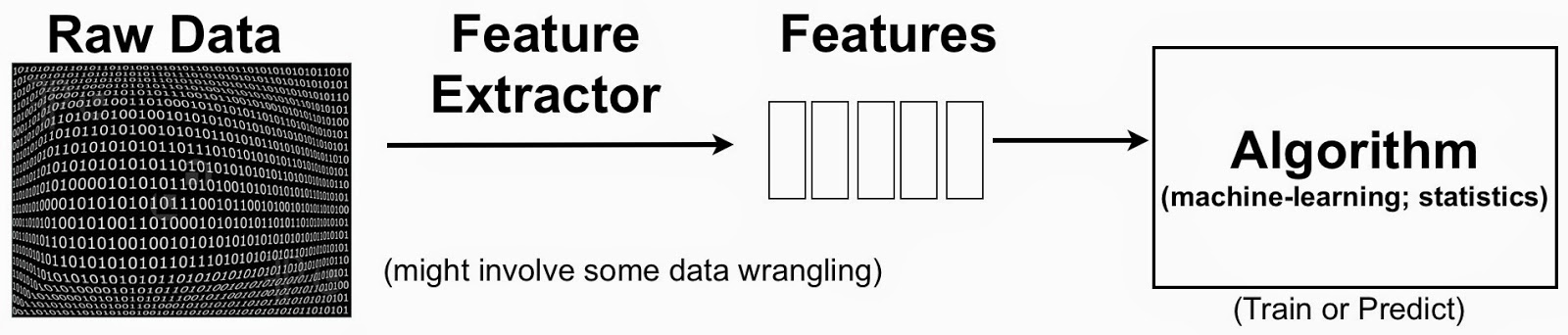
Feature Engineering or the Creation of New Features
A simple example to keep in mind is text mining. One starts with raw text (documents) and extracted features could be individual words or phrases. In this setting, a feature could indicate the frequency of a specific word or phrase. Features1 are then used to classify and cluster documents, or extract topics associated with the raw text. The process usually involves the creation2 of new features (feature engineering) and identifying the most essential ones (feature selection).