"machine learning products" entries

Instrumenting collaboration tools used in data projects
Built-in audit trails can be useful for reproducing and debugging complex data analysis projects
As I noted in a previous post, model building is just one component of the analytic lifecycle. Many analytic projects result in models that get deployed in production environments. Moreover, companies are beginning to treat analytics as mission-critical software and have real-time dashboards to track model performance.
Once a model is deemed to be underperforming or misbehaving, diagnostic tools are needed to help determine appropriate fixes. It could well be models need to be revisited and updated, but there are instances when underlying data sources1 and data pipelines are what need to be fixed. Beyond the formal systems put in place specifically for monitoring analytic products, tools for reproducing data science workflows could come in handy.
Business analysts want access to advanced analytics
Business users are starting to tackle problems that require machine-learning and statistics
I talk with many new companies who build tools for business analysts and other non-technical users. These new tools streamline and simplify important data tasks including interactive analysis (e.g., pivot tables and cohort analysis), interactive visual analysis (as popularized by Tableau and Qlikview), and more recently data preparation. Some of the newer tools scale to large data sets, while others explicitly target small to medium-sized data.
As I noted in a recent post, companies are beginning to build data analysis tools1 that target non-experts. Companies are betting that as business users start interacting with data, they will want to tackle some problems that require advanced analytics. With business analysts far outnumbering data scientists, it makes sense to offload some problems to non-experts2.
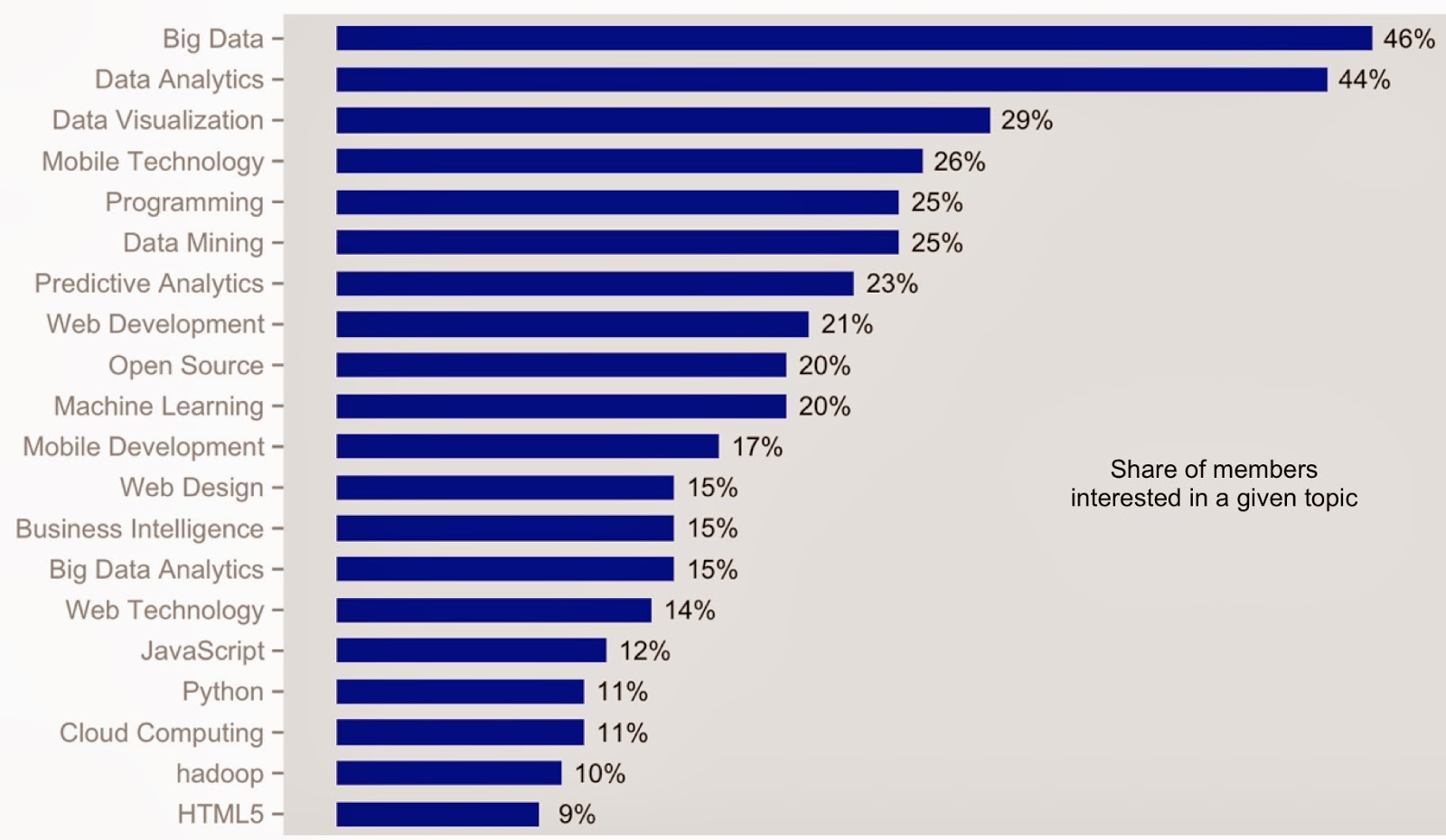
Moreover data seems to support the notion that business users are interested in more complex problems. I recently looked at data3 from 11 large Meetups (in NYC and the SF Bay Area) that target business analysts and business intelligence users. Altogether these Meetups had close to 5,000 active4 members. As you can see in the chart below, business users are interested in topics like machine learning (1 in 5), predictive analytics (1 in 4), and data mining (1 in 4):
Six reasons why I recommend scikit-learn
It's an extensive, well-documented, and accessible, curated library of machine-learning models
I use a variety of tools for advanced analytics, most recently I’ve been using Spark (and MLlib), R, scikit-learn, and GraphLab. When I need to get something done quickly, I’ve been turning to scikit-learn for my first pass analysis. For access to high-quality, easy-to-use, implementations1 of popular algorithms, scikit-learn is a great place to start. So much so that I often encourage new and seasoned data scientists to try it whenever they’re faced with analytics projects that have short deadlines.
I recently spent a few hours with one of scikit-learn’s core contributors Olivier Grisel. We had a free flowing discussion were we talked about machine-learning, data science, programming languages, big data, Paris, and … scikit-learn! Along the way, I was reminded by why I’ve come to use (and admire) the scikit-learn project.
Commitment to documentation and usability
One of the reasons I started2 using scikit-learn was because of its nice documentation (which I hold up as an example for other communities and projects to emulate). Contributions to scikit-learn are required to include narrative examples along with sample scripts that run on small data sets. Besides good documentation there are other core tenets that guide the community’s overall commitment to quality and usability: the global API is safeguarded, all public API’s are well documented, and when appropriate contributors are encouraged to expand the coverage of unit tests.
Models are chosen and implemented by a dedicated team of experts
scikit-learn’s stable of contributors includes experts in machine-learning and software development. A few of them (including Olivier) are able to devote a portion of their professional working hours to the project.
Covers most machine-learning tasks
Scan the list of things available in scikit-learn and you quickly realize that it includes tools for many of the standard machine-learning tasks (such as clustering, classification, regression, etc.). And since scikit-learn is developed by a large community of developers and machine-learning experts, promising new techniques tend to be included in fairly short order.
As a curated library, users don’t have to choose from multiple competing implementations of the same algorithm (a problem that R users often face). In order to assist users who struggle to choose between different models, Andreas Muller created a simple flowchart for users:
Simplifying interactive, realtime, and advanced analytics
Tools for unlocking big data continue to get simpler
Here are a few observations based on conversations I had during the just concluded Strata NYC conference.
Interactive query analysis on Hadoop remains a hot area
A recent O’Reilly survey confirmed SQL is an important skill for data scientists. A year after the launch of Impala, quite a few attendees I spoke with remained interested in the progress of SQL-on-Hadoop solutions. A trio from Hortonworks gave an update on recent improvements and changes to Hive1. A sign that Impala is gaining traction, Greg Rahn’s talk on Practical Performance Tuning for Impala was one of the best attended sessions in the conference. Ditto for a sponsored session on Kognitio’s latest features.
Existing SQL-on-Hadoop solutions require that users define a schema – an additional step given that a lot of data is increasingly in key-value or JSON format. In his talk Hadapt co-founder Daniel Abadi highlighted a solution2 that lets users query complex data types (Hadapt reserializes complex data types to speed up joins). I expect other SQL-on-Hadoop solutions to also offer query support for complex data types in the near future.
Empowering business users
With its launch at the conference, ClearStory joins Platfora and Datameer in the business analytics space. Each company builds tools that lets business users wade through large amounts of data, while emphasizing different areas. Platfora is for interactive visual analysis of massive data sets, while Datameer connects to many data sources (not just Hadoop), has started offering analytics, and can run on a laptop or cluster. Built primarily on the Berkeley stack (BDAS), ClearStory’s interesting platform encourages collaboration and simplifies data harmonization (fusing disparate data sources is a common bottleneck for business users). For organizations willing to tag and describe their data sets, Microsoft unveiled a tool that lets users query data using natural language (UK startup NeutrinoBI uses a similar “search interface”).
Gaining access to the best machine-learning methods
Accuracy, simplicity, speed, and interpretability are some of the factors that need to be considered
For companies in the early stages of grappling with big data, the analytic lifecycle (model building, deployment, maintenance) can be daunting. In earlier posts I highlighted some new tools that simplify aspects of the analytic lifecycle, including the early phases of model building. But while tools are allowing companies to offload routine analytic tasks to business analysts, experienced modelers are still needed to fine-tune and optimize, mission-critical algorithms.
Model Selection: Accuracy and other considerations
Accuracy1 is the main objective and a lot of effort goes towards raising it. But in practice tradeoffs have to be made, and other considerations play a role in model selection. Speed (to train/score) is important if the model is to be used in production. Interpretability is critical if a model has to be explained for transparency2 reasons (“black-boxes” are always an option, but are opaque by definition). Simplicity is important for practical reasons: if a model has “too many knobs to tune” and optimizations have to be done manually, it might be too involved to build and maintain it in production3.
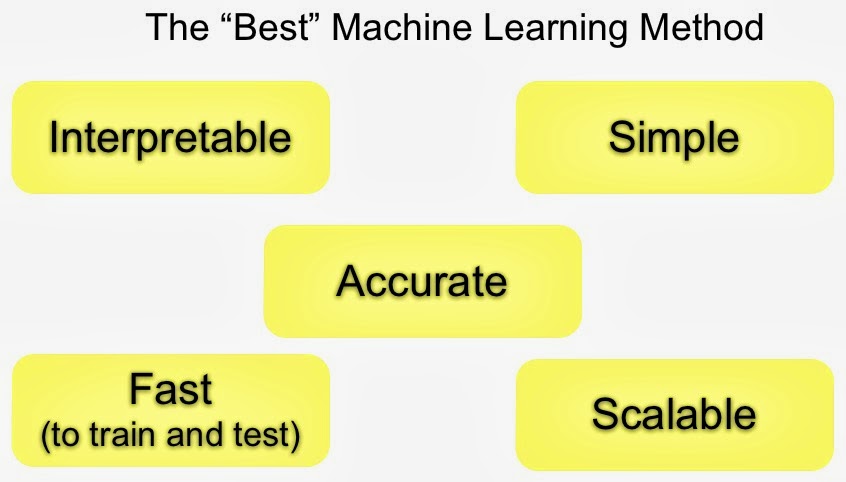
Chances are a model that’s fast, easy to explain (interpretable), and easy to tune (simple), is less4 accurate. Experienced model builders are valuable precisely because they’ve weighed these tradeoffs across many domains and settings. Unfortunately not many companies have the experts that can identify, build, deploy, and maintain models at scale. (An example from Google illustrates the kinds of issues that can come up.)
Scalable streaming analytics using a single-server
The simplest and quickest way to mine your data is to deploy efficient algorithms designed to answer key questions at scale.
For many organizations real-time1 analytics entails complex event processing systems (CEP) or newer distributed stream processing frameworks like Storm, S4, or Spark Streaming. The latter have become more popular because they are able to process massive amounts of data, and fit nicely with Hadoop and other cluster computing tools. For these distributed frameworks peak volume is function of network topology/bandwidth and the throughput of the individual nodes.
Scaling up machine-learning: Find efficient algorithms
Faced with having to crunch through a massive data set, the first thing a machine-learning expert will try to do is devise a more efficient algorithm. Some popular approaches involve sampling, online learning, and caching. Parallelizing an algorithm tends to be lower on the list of things to try. The key reason is that while there are algorithms that are embarrassingly parallel (e.g., naive bayes), many others are harder to decouple. But as I highlighted in a recent post, efficient tools that run on single servers can tackle large data sets. In the machine-learning context recent examples2 of efficient algorithms that scale to large data sets, can be found in the products of startup SkyTree.
Data Science tools: Are you “all in” or do you “mix and match”?
It helps to reduce context-switching during long data science workflows.
An integrated data stack boosts productivity
As I noted in my previous post, Python programmers willing to go “all in”, have Python tools to cover most of data science. Lest I be accused of oversimplification, a Python programmer still needs to commit to learning a non-trivial set of tools1. I suspect that once they invest the time to learn the Python data stack, they tend to stick with it unless they absolutely have to use something else. But being able to stick with the same programming language and environment is a definite productivity boost. It requires less “setup time” in order to explore data using different techniques (viz, stats, ML).
Multiple tools and languages can impede reproducibility and flow
On the other end of the spectrum are data scientists who mix and match tools, and use packages and frameworks from several languages. Depending on the task, data scientists can avail of tools that are scalable, performant, require less2 code, and contain a lot of features. On the other hand this approach requires a lot more context-switching, and extra effort is needed to annotate long workflows. Failure to document things properly makes it tough to reproduce3 analysis projects, and impedes knowledge transfer4 within a team of data scientists. Frequent context-switching also makes it more difficult to be in a state of flow, as one has to think about implementation/package details instead of exploring data. It can be harder to discover interesting stories with your data, if you’re constantly having to think about what you’re doing. (It’s still possible, you just have to concentrate a bit harder.)
Data Science Tools: Fast, easy to use, and scalable
Tools slowly democratize many data science tasks
Here are a few observations based on conversations I had during the just concluded Strata Santa Clara conference.
Spark is attracting attention
I’ve written numerous times about components of the Berkeley Data Analytics Stack (Spark, Shark, MLbase). Two Spark-related sessions at Strata were packed (slides here and here) and I talked to many people who were itching to try the BDAS stack. Being able to combine batch, real-time, and interactive analytics in a framework that uses a simple programming model is very attractive. The release of version 0.7 adds a Python API to Spark’s native Scala interface and Java API.

MLbase: Scalable machine-learning made accessible
Describe and run bleeding edge algorithms on massive data sets
In the course of applying machine-learning against large data sets, data scientists face a few pain points. They need to tune and compare several suitable algorithms – a process that may involve having to configure a hodgepodge of tools, requiring different input files, programming languages, and interfaces. Some software tools may not scale to big data, so they first sample and test ideas on smaller subsets, before tackling the problem of having to implement a distributed version of the final algorithm.
To increase productivity, ideally data scientists should be able to quickly test ideas without doing much coding, context switching, tuning and configuration. A research project0 out of UC Berkeley’s Amplab and Brown seems to do just that: MLbase aims to make cutting edge, scalable machine-learning algorithms available to non-experts. MLbase will have four pieces: a declarative language (MQL – discussed below), a library of distributed algorithms (ML-Library), an optimizer and a runtime (ML-Optimizer and ML-Runtime). Read more…

What it takes to build great machine learning products
Rich machine learning products come from skilled and knowledgeable teams.
Specific insights into a problem and careful model design separate a machine learning system that doesn't work from one that people will actually use.