"Mesos" entries

Swarm v. Fleet v. Kubernetes v. Mesos
Comparing different orchestration tools.

Buy Using Docker Early Release.
Most software systems evolve over time. New features are added and old ones pruned. Fluctuating user demand means an efficient system must be able to quickly scale resources up and down. Demands for near zero-downtime require automatic fail-over to pre-provisioned back-up systems, normally in a separate data centre or region.
On top of this, organizations often have multiple such systems to run, or need to run occasional tasks such as data-mining that are separate from the main system, but require significant resources or talk to the existing system.
When using multiple resources, it is important to make sure they are efficiently used — not sitting idle — but can still cope with spikes in demand. Balancing cost-effectiveness against the ability to quickly scale is difficult task that can be approached in a variety of ways.
All of this means that the running of a non-trivial system is full of administrative tasks and challenges, the complexity of which should not be underestimated. It quickly becomes impossible to look after machines on an individual level; rather than patching and updating machines one-by-one they must be treated identically. When a machine develops a problem it should be destroyed and replaced, rather than nursed back to health.
Various software tools and solutions exist to help with these challenges. Let’s focus on orchestration tools, which help make all the pieces work together, working with the cluster to start containers on appropriate hosts and connect them together. Along the way, we’ll consider scaling and automatic failover, which are important features.

A tale of two clusters: Mesos and YARN
With Myriad, analytics can be performed on the same hardware that runs your production services.
This is a tale of two siloed clusters. The first cluster is an Apache Hadoop cluster. This is an island whose resources are completely isolated to Hadoop and its processes. The second cluster is the description I give to all resources that are not a part of the Hadoop cluster. I break them up this way because Hadoop manages its own resources with Apache YARN (Yet Another Resource Negotiator). Which is nice for Hadoop, but all too often those resources are underutilized when there are no big data workloads in the queue. And then when a big data job comes in, those resources are stretched to the limit, and they are likely in need of more resources. That can be tough when you are on an island.
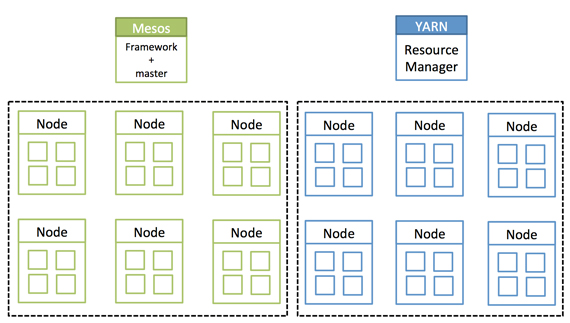
Isolated clusters. Source: Mesosphere and MapR, used with permission.
Hadoop was meant to tear down walls — albeit, data silo walls — but walls, nonetheless. What has happened is that while tearing some walls down, other types of walls have gone up in their place.
Another technology, Apache Mesos, is also meant to tear down walls — but Mesos has often been positioned to manage the “second cluster,” which are all of those other, non-Hadoop workloads.
This is where the story really starts, with these two silos of Mesos and YARN. They are often pitted against each other, as if they were incompatible. It turns out they work together, and therein lies my tale. Read more…