"O’Reilly Data Show" entries

Building systems for massive scale data applications
The O’Reilly Data Show podcast: Tyler Akidau on the evolution of systems for bounded and unbounded data processing.
Subscribe to the O’Reilly Data Show Podcast to explore the opportunities and techniques driving big data and data science.

Many of the open source systems and projects we’ve come to love — including Hadoop and HBase — were inspired by systems used internally within Google. These systems were described in papers and implemented by people who needed frameworks that could comfortably scale to massive data sets.
Google engineers and scientists continue to publish interesting papers, and these days some of the big data systems they describe in publications are available on their cloud platform.
In this episode of the O’Reilly Data Show, I sat down with Tyler Akidau one of the lead engineers in Google’s streaming and Dataflow technologies. He recently wrote an extremely popular article that provided a framework for how to think about bounded and unbounded data processing (a follow-up article is due out soon). We talked about the evolution of stream processing, the challenges of building systems that scale to massive data sets, and the recent surge in interest in all things real time:
On the need for MillWheel: A new stream processing engine
At the time [that MillWheel was built], there was, as far as I know, literally nothing externally that could handle the scale that we needed to handle. A lot of the existing streaming systems didn’t focus on out-of-order processing, which was a big deal for us internally. Also we really wanted to hit a strong focus on consistency — being able to get absolutely correct answers. … All three of these things were lacking in at least some area in [the systems we examined].
Coming full circle with Bigtable and HBase
The O'Reilly Data Show Podcast: Michael Stack on HBase past, present, and future.

Subscribe to the O’Reilly Data Show to explore the opportunities and techniques driving big data and data science.
At least once a year, I sit down with Michael Stack, engineer at Cloudera, to get an update on Apache HBase and the annual user conference, HBasecon. Stack has a great perspective, as he has been part of HBase since its inception. As former project leader, he remains a key contributor and evangelist, and one of the organizers of HBasecon.
In the beginning: Search and Bigtable
During the latest episode of the O’Reilly Data Show Podcast, I decided to broaden our conversation to include the beginnings of the very popular Apache HBase project. Stack reminded me that in the early days much of the big data community in the SF Bay Area was centered around search technologies, such as HBase. In particular, HBase was inspired by work out of Google (Bigtable), and the early engineers had ties to projects out of the Internet Archive:
At the time, I was working at the Internet Archive, and I was working on crawlers and search. The Bigtable paper looked really interesting to us because the archive, as you know, we used to host — or still do — the Wayback Machine. The Wayback Machine is a picture of the Web that goes back to 1998, and you could look at the Web at any particular time. What pages looked liked at a particular time. Bigtable was very interesting at the Internet Archive because it had this time dimension.
…
A group had started up to talk about the possibility of implementing a Bigtable clone. It was centered at a place called Powerset, a startup that was in San Francisco back then. That was about doing a search, so I went and talked to them. They said, ‘Come on over and we’ll make a space for doing a Bigtable clone.’ They had a very intricate search pipeline, and it was based on early Amazon AWS, and every time they started up their pipeline, they’d get a phone call from Amazon saying, ‘Please stop whatever it is you’re doing.’ … The first engineer would be a fellow called Jim Kellerman. The actual first 30 classes came from Mike Cafarella. He was instrumental in getting the first versions of Hadoop going. He was hanging around Apache Nutch at the time. … Doug [Cutting] used to work at the Internet archive, and the first actual versions of Hadoop were run on racks at the Internet archive. Doug was working on fulltext search. Then he moved on to go to Yahoo, to work on Hadoop full time.
Building big data systems in academia and industry
The O'Reilly Data Show Podcast: Mikio Braun on stream processing, academic research, and training.
Mikio Braun is a machine learning researcher who also enjoys software engineering. We first met when he co-founded a real-time analytics company called streamdrill. Since then, I’ve always had great conversations with him on many topics in the data space. He gave one of the best-attended sessions at Strata + Hadoop World in Barcelona last year on some of his work at streamdrill.
I recently sat down with Braun for the latest episode of the O’Reilly Data Show Podcast, and we talked about machine learning, stream processing and analytics, his recent foray into data science training, and academia versus industry (his interests are a bit on the “applied” side, but he enjoys both).
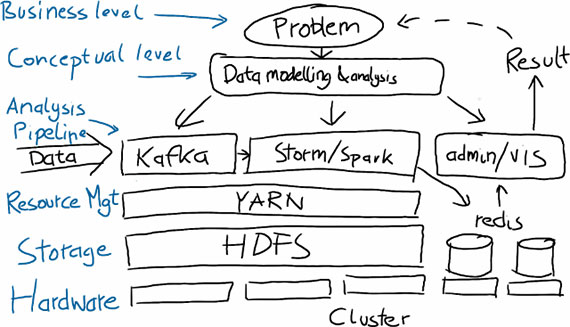
An example of a big data solution. Source: Mikio Braun, used with permission.