- Test, Learn, Adapt (PDF) — UK Cabinet Office paper on randomised trials for public policy. Ben Goldacre cowrote.
- UK EscapeTheCity Raises GBP600k in Crowd Equity — took just eight days, using the Crowdcube platform for equity-based crowd investment.
- DIY Bio SOPs — CC-licensed set of standard operating procedures for a bio lab. These are the SOPs that I provided to the Irish EPA as part of my “Consent Conditions” for “Contained Use of Class 1 Genetically Modified Microorganisms”. (via Alison Marigold)
- Shuffling Cards — shuffle a deck of cards until it’s randomised. That order of cards probably hasn’t ever been seen before in the history of mankind.
"policy" entries

An innovation agenda to help people win the race against the machines
Policy recommendations to get the engines of democracy firing on all cylinders.
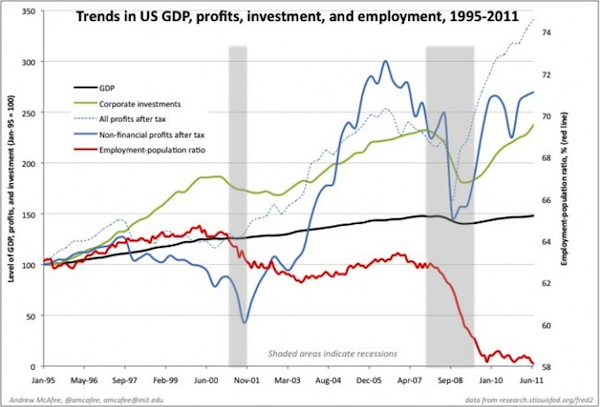
If the country is going to have a serious conversation about innovation, unemployment and job creation, we must talk about our race against the machines. For centuries, we’ve been automating people out of jobs. Today’s combination of big data, automation and artificial intelligence, however, looks like something new, from self-driving cars to e-discovery software to “robojournalism” to financial advisors to medical diagnostics. Last year, venture capitalist Marc Andreessen wrote that “software is eating the world.”
Computers and distributed systems are now demonstrating skills in the real world that we once thought would always be the domain of human beings. “That’s just not the case any more,” said MIT research professor Andrew McAfee, in an interview earlier this year at the Strata Conference in Santa Clara, Calif.:
McAfee and his research partner, MIT economics professor Erik Brynjolfsson, remain fundamentally optimistic about the effect of the digital revolution on the world economy. But the drivers of joblessness that they explore in their book, Race Against The Machine, deserved to have had more discussion in this year’s political campaign. Given the tepid labor market recovery in the United States and a rebound that has stayed flat, the Obama administration, given an opportunity for a second term, should pull some new policy levers.
What could — or should — the new administration do? On Tuesday, I had the pleasure of speaking at a panel at the Center for Technology Innovation at the Brookings Institute to talk about what a “First 100 Days Innovation Agenda” might look like for the new administration. (Full disclosure: earlier this year, I was paid to moderate a workshop that discussed this issue and contributed to the paper on building an innovation economy that was published this week.) The event was live streamed and is available on-demand.
Below are recommendations from the paper and from professors McAfee and Brynjolfsson, followed by the suggestions I made during the forum, drawing from my conversations with people around the United States on this topic over the past two years.

Four short links: 21 June 2012
Randomized Trials for Policy, Crowdfunding Equity, Safe DIYBio, and Easy Unique Experiences
Four short links: 11 January 2012
CAPTCHA Commerce, Tech Policy, Mobile Data, London Event
- Virtual Sweatshops Defeat CAPTCHAs — I knew there was an industry around solving CAPTCHAs (to spam comments on blogs, sign up for millions of gmail accounts, etc.) but this is the first time I’ve seen how much you can be paid for it: employees can expect to earn between $0.35 to $1 for every thousand CAPTCHAs they solve […] Most of our staff is from China, India, Pakistan and Vietnam. (via BoingBoing)
- Lockdown — transcription of Cory Doctorow’s excellent talk, “The Coming War on General-Purpose Computation”. The entertainment industry is just the first belligerents to take up arms, and we tend to think of them as particularly successful. […] But the reality is that copyright legislation gets as far as it does precisely because it’s not taken seriously by politicians. […] Regardless of whether you think these are real problems or hysterical fears, they are, nevertheless, the political currency of lobbies and interest groups far more influential than Hollywood and big content. Every one of them will arrive at the same place: “Can’t you just make us a general-purpose computer that runs all the programs, except the ones that scare and anger us? Can’t you just make us an Internet that transmits any message over any protocol between any two points, unless it upsets us?”
- Mobile Data Consumption Numbers (Luke Wroblewski) — the most eye-catching statistic is 1% of bandwidth consumers account for half of all wireless traffic worldwide in the World. The top 10% of users are consuming 90% of wireless bandwidth. In my land of pay-through-the-nose-for-a-modicum-of-mobile-bandwidth, this was also of note: Voice recognition software Siri has prompted owners of the iPhone 4S to use almost twice as much data as iPhone 4 users.
- Monkigras — event in London that looks interesting. The Redmonk chaps are fellow travellers on the O’Reilly storytelling path: they see many of the same interesting trends as we do, and their speakers cover everything from platform services to open source, startups, and alpha geeks (Biddulph, I’m looking at you). And, also, beer.
Four short links: 29 June 2011
Crowdsourced Economics, Education Gold, Meme Analytics, Hacktivism
- Billion Prices Project — rather than wait for official inflation figures, the BPP from MIT scans online retailer prices from around the planet. (via The Economist)
- Readings in Education — Dan Meyer has linked to some of the best papers he’s been reading at grad school. If you have opinions about education, or are thinking of doing something to “fix education”, you have to read Public Goods, Private Goods (PDF). It brilliantly, concisely, and clearly sums up the reason that conversations about education are so broken. The other papers Dan linked to are equally wow. Another paper (PDF) on the difference in mindsets between educational researcher and practicing teacher says: The initial [teacher] impulse is still to intervene and fix the problem, or critique the actions of the teacher who made the mistake. It also often leads students to frame their own research around educational success stories. The idea is to pick an intervention that promises to improve education—a new teaching technique, curriculum approach, instructional technology, reform effort, or administrative structure—and study it in practice. The desired outcome is that the intervention works rather well, and the function of the study is to document this and suggest how the approach could be improved in the future. This often leads to an approach to scholarship (and eventually to a kind of scholarly literature) that is relentlessly, unrealistically, sometimes comically optimistic—one that suggests that there is an implementable answer to every educational problem and that help is always on the way. He could be writing about every educational startup.
- Truthy — a research project that helps you understand how memes spread online. With our images and statistics, you can help identify misuse of Twitter. (via Pete Warden)
- Hackers Are Being Radicalised By Government Policy (Guardian) — As long as it seems that direct action is more effective than democratic engagement, it’s clear that the former will appear a more attractive option to many. The official line that the internet is a dangerous territory to be subdued is responsible for an alarming radicalisation. This is not just an issue for the tabloids’ oddballs and nerds, it’s an issue for everyone who believes in the fundamental importance of freedom. The Internet uprising is not causing bad regulation; bad regulation caused the Internet uprising. (via Gabriella Coleman)
Four short links: 18 February 2011
Data Sets, Data-driven Policy, Task Queues, and 8-Bit Browser
- DSPL: DataSet Publishing Language (Google Code) — a representation language for the data and metadata of datasets. Datasets described in this format can be processed by Google and visualized in the Google Public Data Explorer. XML metadata on CSV, geo-enabled, with linkable data. (via Michal Migurski on Delicious)
- Why is Evidence So Hard for Politicians — Ben Goldacre nails how politicians go about “evidence-based policy making”: So the Minister has cherry picked only the good findings, from only one report, while ignoring the peer-reviewed literature. Most crucially, he cherry-picks findings he likes whilst explicitly claiming that he is fairly citing the totality of the evidence from a thorough analysis. I can produce good evidence that I have a magical two-headed coin, if I simply disregard all the throws where it comes out tails.
- Celery: Distributed Task Queue — asynchronous task queue/job queue based on distributed message passing. It is focused on real-time operation, but supports scheduling as well. MIT-style licensed, written in Python, RabbitMQ is the recommended message broker. (via Joshua Schachter on Delicious)
- pixelfari — Safari hacked to look like it’s running on an 8-bit computer. This sense of playfulness with the medium is something I love about the best coders. They think “ha, wouldn’t it be funny if …” and then can make it happen.
Four short links: 17 August 2010
Stemming Demo, Mapping Service, Value of Data, and The Magic of the Valley
- Demo of Stemming Algorithms — type in text and see what it looks like when stemmed with different algorithms provided by NLTK. (via zelandiya on Twitter)
- Crowdmap — hosted Ushahidi. (via dvansickle on Twitter)
- Opinions vs Data — talks about the usability of a new gmail UI element, but notable for this quote from Jakob Nielsen: In my two examples, the probability of making the right design decision was vastly improved when given the tiniest amount of empirical data. (via mcannonbrookes on Twitter)
- The Next Silicon Valley — long and detailed list of the many forces contributing to Silicon Valley’s success as tech hub, arguing that the valley’s position is path-dependent and can simply be grown ab initio in some aspiring nation’s co-prosperity zone of policy whim. (via imran and timoreilly on Twitter)
Four short links: 13 August 2010
Scientific Literacy, Load Balancing, Indoors Geolocation, and iPhone Security
- The Myth of Scientific Literacy — I’d love it if there was a simple course we could send our elected officials on which would guarantee future science policy would be reliably high quality. Being educated in science (or even “about science”) isn’t going to do it. It’s social connections that will. We need to keep our elected officials honest, constantly check they are applying the evidence we want them to, in the ways we want them to. And if the scientific community want to be listened to, they need to work to build connections. Get political and scientific communities overlapping, embed scientists in policy institutions (and vice versa), get MP’s constituents onside to help foster the sorts of public pressure you want to see: build trust so scientists become people MPs want to be briefed by. (via foe on Twitter)
- Three Papers on Load Balancing (Alex Popescu) — three papers on distributed hash tables.
- Meridian — iPhone app that does in-building location, sample app is the AMNH Explorer which shows you maps of where you are. Uses wifi-based positioning. (via raffi on Twitter)
- Fixing What Apple Won’t — the jailbreakers are releasing security patches for systems that Apple have abandoned. (via ardgedee on Twitter)
Four short links: 12 August 2010
Network Neutrality, Open Data, Science Policy, and the Android Army
- A Review of Verizon and Google’s Net Neutrality Proposal (EFF) — a mixture of good and bad, is the verdict. I am ready to give Google credit for getting Network Neutrality back on the regulatory agenda, whether or not this proposal was a strawman.
- Ten Principles for Opening Up Government Information (Sunlight Foundation) — We have updated and expanded upon the Sebastopol list and identified ten principles that provide a lens to evaluate the extent to which government data is open and accessible to the public. The list is not exhaustive, and each principle exists along a continuum of openness. The principles are completeness, primacy, timeliness, ease of physical and electronic access, machine readability, non-discrimination, use of commonly owned standards, licensing, permanence and usage costs.
- What If the Web Really Worked for Science? Reimagining Data Policy and Intellectual Property (video) — a talk by James Boyle on IP and science policy.
- Winners of the Apps for Army Challenge — more Android apps than iPhone in the winners. (via Alex)
Four short links: 21 July 2010
Health, Profit, Policy, and Semantic Web Software
- The Men Who Stare at Screens (NY Times) — What was unexpected was that many of the men who sat long hours and developed heart problems also exercised. Quite a few of them said they did so regularly and led active lifestyles. The men worked out, then sat in cars and in front of televisions for hours, and their risk of heart disease soared, despite the exercise. Their workouts did not counteract the ill effects of sitting. (via Andy Baio)
- Caring with Cash — describes a study where “pay however much you want” had high response rate but low average price, “half goes to charity” barely changed from the control (fixed price) response rate, but “half goes to charity and you can pay what you like” earned more money than either strategy.
- Behavioural Economics a Political Placebo? (NY Times) — As policymakers use it to devise programs, it’s becoming clear that behavioral economics is being asked to solve problems it wasn’t meant to address. Indeed, it seems in some cases that behavioral economics is being used as a political expedient, allowing policymakers to avoid painful but more effective solutions rooted in traditional economics. (via Mind Hacks)
- Protege — open source ontology editor and knowledge-base framework.
Four short links: 23 June 2010
Being Wrong, Science Malfunding, Touch-screen Libraries, Mining Flickr Photos
- Ira Glass on Being Wrong (Slate) — fascinating interview with Ira Glass on the fundamental act of learning: being wrong. I had this experience a couple of years ago where I got to sit in on the editorial meeting at the Onion. Every Monday they have to come up with like 17 or 18 headlines, and to do that, they generate 600 headlines per week. I feel like that’s why it’s good: because they are willing to be wrong 583 times to be right 17. (via Hacker News)
- Real Lives and White Lies in the Funding of Scientific Research (PLoSBiology) — very clear presentation of the problems with the current funding models of scientific research, where the acknowledged best scientists spend most of their time writing funding proposals. K.’s plight (an authentic one) illustrates how the present funding system in science eats its own seed corn. To expect a young scientist to recruit and train students and postdocs as well as producing and publishing new and original work within two years (in order to fuel the next grant application) is preposterous.
- jQTouch Roadmap — interesting to me is the primary distinction between Sencha and jQTouch, namely that jQT is for small devices (phones) only, while Sencha handles small and large (tablet) touch-screen devices. (via Simon St Laurent)
- Travel Itineraries from Flickr Photo Trails (Greg Linden) — clever idea, to use metadata extracted from Flickr photos (location, time, etc.) to construct itineraries for travellers, saying where to go, how long to spend there, and how long to expect to spend getting from place to place. Another story of the surprise value that can be extracted from overlooked data.