"real time analytics" entries

Specialized and hybrid data management and processing engines
A new crop of interesting solutions for the complexity of operating multiple systems in a distributed computing setting.

The 2004 holiday shopping season marked the start of Amazon’s investigation into alternative database technologies that led to the creation of DynamoDB — a key-value storage system that went onto inspire several NoSQL projects.
A new group of startups began shifting away from the general-purpose systems favored by companies just a few years earlier. In recent years, we’ve seen a diverse set of DBMS technologies that specialize in handling particular workloads and data models such as OLTP, OLAP, search, RDF, XML, scientific applications, etc. The success and popularity of such systems reinforced the belief that in order to scale and “go fast,” specialized systems are preferable.
In distributed computing, the complexity of maintaining and operating multiple specialized systems has recently led to systems that bridge multiple workloads and data models. Aside from multi-model databases, there are an emerging number of storage and compute engines adept at handling different workloads and problems. At this week’s Strata + Hadoop World conference in NYC, I had a chance to interact with the creators of some of these new solutions.
OLTP (transactions) and OLAP (analytics)
One of the key announcements at Strata + Hadoop World this week was Project Kudu — an open source storage engine that’s good at both table scans (analytics) and random access (updates and inserts). Its creators are quick to point out that they aren’t out to beat specialized OLTP and OLAP systems. Rather, they’re shooting to build a system that’s “70-80% of the way there on both axes.” The project is very young and lacks enterprise features, but judging from the reaction at the conference, it’s something the big data community will be watching. Leading technology research firms have created a category for systems with related capabilities: HTAP (Gartner) and Trans-analytics (Forrester).

Accelerating real-time analytics with Spark
Integration of the data supply chain is key to a reliable and fast big data analytics deployment.

Watch our free webcast “Accelerating Advanced Analytics with Spark” to learn about the architecture, applications, and best practices of Apache Spark.
Apache Hadoop is a mature development framework, which coupled with its large ecosystem, and support and contributions from key players such as Cloudera, Hortonworks, and Yahoo, provides organizations with many tools to manage data of varying sizes.
In the past, Hadoop’s batch-oriented nature using MapReduce was sufficient to meet the processing needs of many organizations. However, increasing demands for faster processing of data have emerged. These demands have been driven by recent developments in streaming technologies, the Internet of Things (IoT) and real-time analytics, to name just a few. These new demands have required new processing models. One significant new technology today that is being used to meet these demands and is gaining considerable interest and widespread support is Apache Spark. Spark’s speed and versatility make it a key part of today’s big-data processing stack in industries from energy to finance. Read more…

How real-time analytics integrates with our connected world
The O'Reilly Podcast: Scott Jarr on how real-time analytics applications can unlock value and automate decision-making.

In this special-edition O’Reilly Podcast, O’Reilly’s Ben Lorica and VoltDB’s co-founder Scott Jarr discuss how VoltDB’s hybrid transaction, analytic system allows for real-time analytics and personalization of data across various industries.
Scaling transaction processing without losing the relational database
MIT’s Mike Stonebraker (VoltDB’s co-founder) wanted to scale traditional OLTP (online transaction processing) without losing performance. The project evolved and eventually commercialized as VoltDB around the time NoSQL systems introduced a paradigm shift to non-relational databases. Jarr describes how Stonebraker’s approach didn’t assume a relational database was a core issue:
To give you an old story, but it’s a good story, they took a traditional style OLTP database and they ran it in memory. What they found was that it was doing less than 10% of its effective workload in processing transactions. The rest was dealing with overhead in various forms. He said, ‘Without getting rid of any of the things that we know [are] involved in the database world — consistency, SQL, ACID transactions, relational structures, high-level query languages — let’s keep all that, but let’s see if we can make this thing go faster.’
When those [NoSQL] systems were coming out, and they were coming out very strong, it was around the same time we were coming out with VoltDB. People were asking questions, ‘Well you’re consistent and they’re not.’ Or, ‘You’re relational and they’re not.’ I think that really lost the true meaning of what the differences were … [let’s] not get mired in the details … let’s look at the workloads that people are trying to accomplish.

Real-time analytics within the transaction
Integrated data stream platforms are poised to supplant the lambda architecture.

Data generation is growing exponentially, as is the demand for real-time analytics over fast input data. Traditional approaches to analyzing data in batch mode overcome the computational problems of data volume by scaling horizontally using a distributed system like Apache Hadoop. However, this solution is not feasible for analyzing large data streams in real time due to the scheduling I/O overhead it introduces.
Two main problems occur when batch processing is applied to stream or fast data. First, by the time the analysis is complete, it may already have been outdated by new incoming data. Second, the data may be arriving so fast that it is not feasible to store and batch-process them later, so the data must be processed or summarized when it is received. The Square Kilometer Array (SKA) radio telescope is a good public example of a system in which data must be preprocessed before storage. The SKA is a distributed radio observation project where each base station will receive 10-30 TB/sec and the Central Unit will process 4PB/sec. In this scenario, online summaries of the input data must be computed in real time and then processed — and significantly reduced in size — data is what’s stored.
In the business world, common examples of stream data are sensor networks, Twitter, Internet traffic, logs, financial tickers, click streams, and online bids. Algorithmic solutions enable the computation of summaries, frequency (heavy hitter) and event detection, and other statistical calculations on the stream as a whole or detection of outliers within it.
But what if you need to perform transaction-level analysis — scans across different dimensions of the data set, for example — as well as store the streamed data for fast lookup and retrospective analysis? Read more…
A real-time tool for a real-time problem
Using VoltDB and the Lambda Architecture to locate abnormal behavior.

Subscriber Identity Module box (SIMbox) fraud is a type of telecommunications fraud where users avoid an international outbound-calls charge by redirecting the call through voice over IP to a SIM in the country where the destination is located. This is an issue we helped a client address at Wise Athena.
Taking on this type of problem requires a stream-based analysis of the Call Detail Record (CDR) logs, which are typically generated quickly. Detecting this kind of activity requires in-memory computations of streaming data. You might also need to scale horizontally.
We recently evaluated the use of VoltDB together with our cognitive analytics and machine-learning system to analyze CDRs and provide accurate and fast SIMbox fraud detection. At the beginning, we used batch processing to detect SIMbox fraud, but the response time took too long, so we switched to a technology that allows in-memory computations in order to reach the desired time constraints.
VoltDB’s in-memory distributed database provides transactions at streaming speed in a fast environment. It can support millions of small transactions per second. It also allows streaming aggregation and fast counters over incoming data. These attributes allowed us to develop a real-time analytics layer on top of VoltDB. Read more…

Why local state is a fundamental primitive in stream processing
What do you get if you cross a distributed database with a stream processing system?

One of the concepts that has proven the hardest to explain to people when I talk about Samza is the idea of fault-tolerant local state for stream processing. I think people are so used to the idea of keeping all their data in remote databases that any departure from that seems unusual.
So, I wanted to give a little bit more motivation as to why we think local state is a fundamental primitive in stream processing.
What is state and why do you need it?
An easy way to understand state in stream processing is to think about the kinds of operations you might do in SQL. Imagine running SQL queries against a real-time stream of data. If your SQL query contains only filtering and single-row transformations (a simple select and where clause, say), then it is stateless. That is, you can process a single row at a time without needing to remember anything in between rows. However, if your query involves aggregating many rows (a group by) or joining together data from multiple streams, then it must maintain some state in between rows. If you are grouping data by some field and counting, then the state you maintain would be the counts that have accumulated so far in the window you are processing. If you are joining two streams, the state would be the rows in each stream waiting to find a match in the other stream.
Expanding options for mining streaming data
New tools make it easier for companies to process and mine streaming data sources
Stream processing was in the minds of a few people that I ran into over the past week. A combination of new systems, deployment tools, and enhancements to existing frameworks, are behind the recent chatter. Through a combination of simpler deployment tools, programming interfaces, and libraries, recently released tools make it easier for companies to process and mine streaming data sources.
Of the distributed stream processing systems that are part of the Hadoop ecosystem0, Storm is by far the most widely used (more on Storm below). I’ve written about Samza, a new framework from the team that developed Kafka (an extremely popular messaging system). Many companies who use Spark express interest in using Spark Streaming (many have already done so). Spark Streaming is distributed, fault-tolerant, stateful, and boosts programmer productivity (the same code used for batch processing can, with minor tweaks, be used for realtime computations). But it targets applications that are in the “second-scale latencies”. Both Spark Streaming and Samza have their share of adherents and I expect that they’ll both start gaining deployments in 2014.
Stream Mining essentials
At the most basic level, stream mining is about generating summaries that can be used to answer fundamental questions
A series of open source, distributed stream processing frameworks have become essential components in many big data technology stacks. Apache Storm remains the most popular, but promising new tools like Spark Streaming and Apache Samza are going to have their share of users. These tools excel at data processing and are also used for data mining – in many cases users have to write a bit of code1 to do stream mining. The good news is that easy-to-use stream mining libraries will likely emerge in the near future.
High volume data streams (data that arrive continuously) arise in many settings, including IT operations, sensors, and social media. What can one learn by looking at data one piece (or a few pieces) at a time? Can techniques that look at smaller representations of data streams be used to unlock their value? In this post, I’ll briefly summarize a recent overview given by stream mining pioneer Graham Cormode.
Generate Summaries
Massive amounts of data arriving at high velocity pose a challenge to data miners. At the most basic level, stream mining is about generating summaries that can be used to answer fundamental questions:
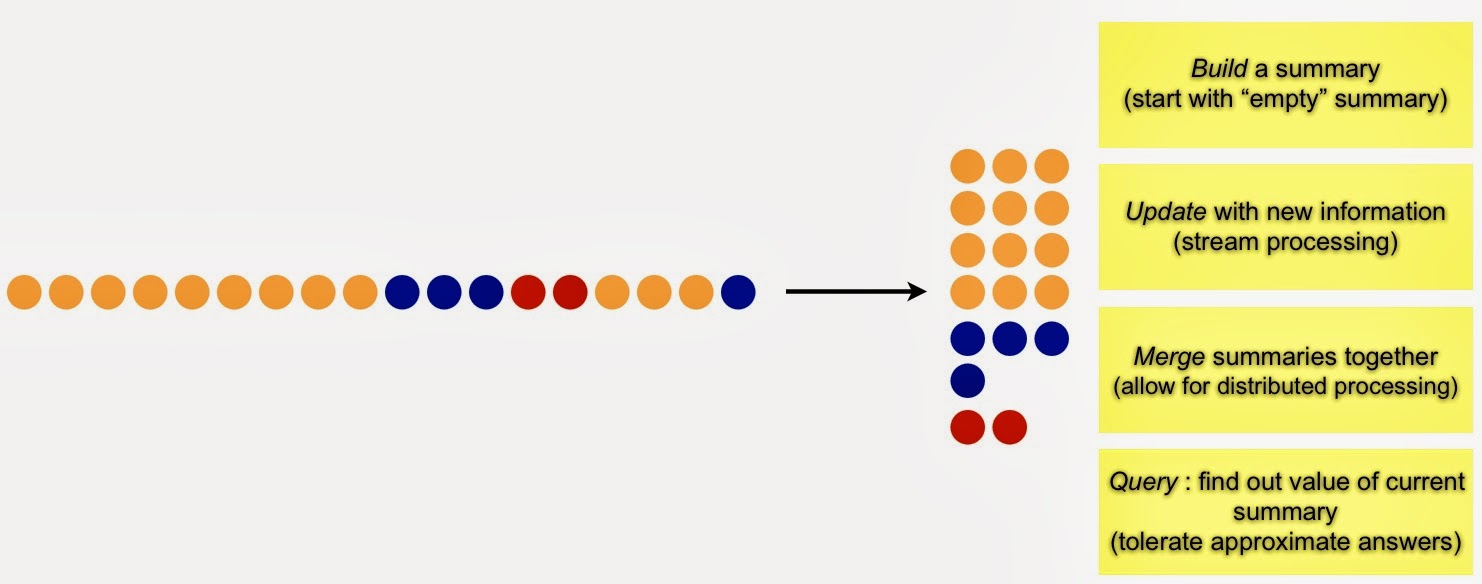
Properly constructed summaries are useful for highlighting emerging patterns, trends, and anomalies. Common summaries (frequency moments in stream mining parlance) include a list of distinct items, recently trending items, heavy hitters (items that have appeared frequently), and the top k (most popular) items.
Stream Processing and Mining just got more interesting
A general purpose stream processing framework from the team behind Kafka and new techniques for computing approximate quantiles
Largely unknown outside data engineering circles, Apache Kafka is one of the more popular open source, distributed computing projects. Many data engineers I speak with either already use it or are planning to do so. It is a distributed message broker used to store1 and send data streams. Kafka was developed by Linkedin were it remains a vital component of their Big Data ecosystem: many critical online and offline data flows rely on feeds supplied by Kafka servers.
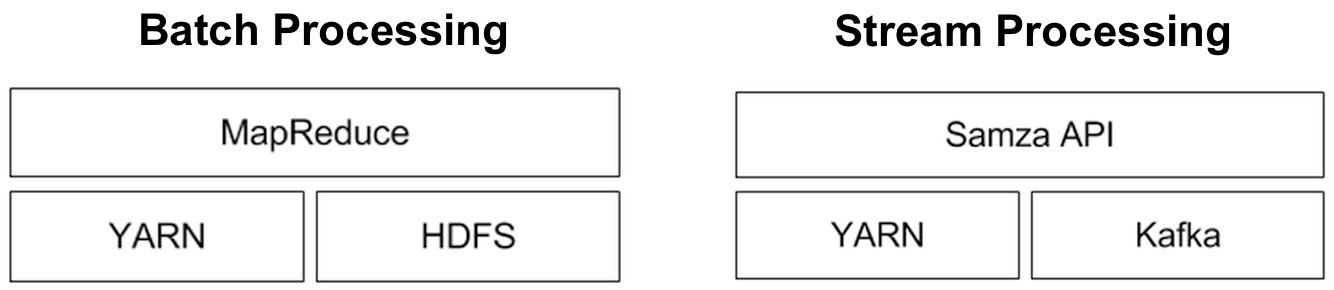
Apache Samza: a distributed stream processing framework
Behind Kafka’s success as an open source project is a team of savvy engineers who have spent2 the last three years making it a rock solid system. The developers behind Kafka realized early on that it was best to place the bulk of data processing (i.e., stream processing) in another system. Armed with specific use cases, work on Samza proceeded in earnest about a year ago. So while they examined existing streaming frameworks (such as Storm, S4, Spark Streaming), Linkedin engineers wanted a system that better fit their needs3 and requirements:
Big Data and Advertising: In the trenches
Volume, variety, velocity, and a rare peek inside sponsored search advertising at Google
The $35B merger of Omnicom and Publicis put the convergence of Big Data and Advertising1 in the front pages of business publications. Adtech2 companies have long been at the forefront of many data technologies, strategies, and techniques. By now it’s well-known that many impressive large scale, realtime analytics systems in production, support3 advertising. A lot of effort has gone towards accurately predicting and measuring click-through rates, so at least for online advertising, data scientists and data engineers have gone a long way towards addressing4 the famous “but we don’t know which half” line.
The industry has its share of problems: privacy & creepiness come to mind, and like other technology sectors adtech has its share of “interesting” patent filings (see for example here, here, here). With so many companies dependent on online advertising, some have lamented the industry’s hold5 on data scientists. But online advertising does offer data scientists and data engineers lots of interesting technical problems to work on, many of which involve the deployment (and creation) of open source tools for massive amounts of data.