"spark" entries

Python data tools just keep getting better
A variety of tools are making data science tasks easy to do in Python
Here are a few observations inspired by conversations I had during the just concluded PyData conference1.
The Python data community is well-organized:
Besides conferences (PyData, SciPy, EuroSciPy), there is a new non-profit (NumFOCUS) dedicated to supporting scientific computing and data analytics projects. The list of supported projects are currently Python-based, but in principle NumFOCUS is an entity that can be used to support related efforts from other communities.
It’s getting easier to use the Python data stack:
There are tools that facilitate the dissemination and sharing of code and programming environments. IPython2 notebooks allow Python code and markup in the same document. Notebooks are used to record and share complex workflows and are used heavily for (conference) tutorials. As the data stack grows, one of the major pain points is getting all the packages to work properly together (version compatibility is a common issue). In particular setting up environments were all the pieces work together can be a pain. There are now a few solutions that address this issue: Anaconda and cloud-based Wakari from Continuum Analytics, and cloud computing platform PiCloud.
There are many more visualization tools to choose from:
The 2D plotting tool matplotlib is the first tool enthusiasts turn to, but as I learned at the conference, there are a number of other options available. Continuum Analytics recently introduced companion packages Bokeh and Bokeh.js that simplify the creation of static and interactive visualizations using Python. In particular Bokeh is the equivalent of ggplot (it even has an interface that mimics ggplot). With Nodebox, programmers use Python code to create sketches and interactive visualizations that are similar to those produced by Processing. Read more…
Data Science Tools: Fast, easy to use, and scalable
Tools slowly democratize many data science tasks
Here are a few observations based on conversations I had during the just concluded Strata Santa Clara conference.
Spark is attracting attention
I’ve written numerous times about components of the Berkeley Data Analytics Stack (Spark, Shark, MLbase). Two Spark-related sessions at Strata were packed (slides here and here) and I talked to many people who were itching to try the BDAS stack. Being able to combine batch, real-time, and interactive analytics in a framework that uses a simple programming model is very attractive. The release of version 0.7 adds a Python API to Spark’s native Scala interface and Java API.

MLbase: Scalable machine-learning made accessible
Describe and run bleeding edge algorithms on massive data sets
In the course of applying machine-learning against large data sets, data scientists face a few pain points. They need to tune and compare several suitable algorithms – a process that may involve having to configure a hodgepodge of tools, requiring different input files, programming languages, and interfaces. Some software tools may not scale to big data, so they first sample and test ideas on smaller subsets, before tackling the problem of having to implement a distributed version of the final algorithm.
To increase productivity, ideally data scientists should be able to quickly test ideas without doing much coding, context switching, tuning and configuration. A research project0 out of UC Berkeley’s Amplab and Brown seems to do just that: MLbase aims to make cutting edge, scalable machine-learning algorithms available to non-experts. MLbase will have four pieces: a declarative language (MQL – discussed below), a library of distributed algorithms (ML-Library), an optimizer and a runtime (ML-Optimizer and ML-Runtime). Read more…
GraphChi: Graph analytics over billions of edges using your laptop
A disk-based, single-node, graph analytics system that scales to massive graphs
GraphChi is a spinoff project of GraphLab, an open source, distributed, in-memory software system for analytics and machine-learning.

Designed specifically to run on a single computer with limited memory1 (DRAM), since its release a few months ago GraphChi has been used to analyze graphs with billions of edges. Running on a single machine means deployment and debugging are simpler. In addition it is no longer necessary to find (optimal) graph partitions that minimize communication between compute nodes – the starting point for many distributed graph computations.
The stated goal of GraphChi is to “Compute on graphs with billions of edges, in a reasonable time, on a single PC.” One way to define “reasonable amount of computation time” is to compare against the results produced by other graph processing systems. That’s exactly what GraphChi’s creators did in a recent paper. They found that GraphChi compared favorably to graph analytics packages such as Pegasus and Stanford GPS. While GraphChi was 2-3X slower2 in some cases, it is easier to deploy, easier to debug, and way more energy efficient. Read more…
Shark: Real-time queries and analytics for big data
Shark is 100X faster than Hive for SQL, and 100X faster than Hadoop for machine-learning
Hadoop’s strength is in batch processing, MapReduce isn’t particularly suited for interactive/adhoc queries. Real-time1 SQL queries (on Hadoop data) are usually performed using custom connectors to MPP databases. In practice this means having connectors between separate Hadoop and database clusters. Over the last few months a number of systems that provide fast SQL access within Hadoop clusters have garnered attention. Connectors between Hadoop and fast MPP database clusters are not going away, but there is growing interest in moving many interactive SQL tasks into systems that coexist on the same cluster with Hadoop.
Having a Hadoop cluster support fast/interactive SQL queries dates back a few years to HadoopDB, an open source project out of Yale. The creators of HadoopDB have since started a commercial software company (Hadapt) to build a system that unites Hadoop/MapReduce and SQL. In Hadapt, a (Postgres) database is placed in nodes of a Hadoop cluster, resulting in a system2 that can use MapReduce, SQL, and search (Solr). Now on version 2.0, Hadapt is a fault-tolerant system that comes with analytic functions (HDK) that one can use via SQL. Read more…
Spark 0.6 improves performance and accessibility
The development team continues to focus on features that will grow the number of Spark users
In an earlier post I listed a few reasons why I’ve come to embrace and use Spark. In particular I described why Spark is well-suited for many distributed Big Data Analytics tasks such as iterative computations and interactive queries, where it outperforms Hadoop. With version 0.6, Spark becomes even0 faster and easier to use. The release notes contain all the detailed changes, but as you’ll see from the highlights1 below, version 0.6 is a substantial release. Another good sign is the growth in number of contributors, with now over a third of the developers coming from outside the core team in Berkeley.
New Deployment Modes
In addition to running on top of Mesos, Spark can now be deployed in standalone mode: users only need to install Spark and a JVM on each node, a simple cluster manager2 that comes with Spark 0.6, handles the rest. Deployment becomes much simpler and allows organizations who aren’t familiar with Mesos (and C++) to run Spark on their clusters. This release also provides an experimental mode for running Spark on Apache YARN.
New Java API
While I use Spark exclusively through Scala, many Java developers have been asking for a Java API. With version 0.6 the wait is over: all of Spark’s features can be accessed from Java through an API. A Python API is coming very soon.
RDD persistence options
RDD’s are distributed objects that can be cached in-memory, across a cluster of compute nodes. They are the fundamental data objects used in Spark. In version 0.6 caching policy can be controlled at the individual RDD level. Users can decide whether to keep an RDD in-memory or on disk, serialize it, or replicate3 it across nodes. Read more…
Seven reasons why I like Spark
Spark is becoming a key part of a big data toolkit.
A large portion of this week’s Amp Camp at UC Berkeley, is devoted to an introduction to Spark – an open source, in-memory, cluster computing framework. After playing with Spark over the last month, I’ve come to consider it a key part of my big data toolkit. Here’s why:
Hadoop integration: Spark can work with files stored in HDFS, an important feature given the amount of investment in the Hadoop Ecosystem. Getting Spark to work with MapR is straightforward.
The Spark interactive Shell: Spark is written in Scala, and has it’s own version of the Scala interpreter. I find this extremely convenient for testing short snippets of code.
The Spark Analytic Suite:
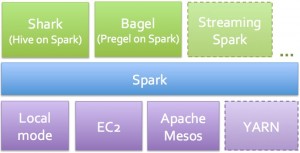
(Figure courtesy of Matei Zaharia)
Spark comes with tools for interactive query analysis (Shark), large-scale graph processing and analysis (Bagel), and real-time analysis (Spark Streaming). Rather than having to mix and match a set of tools (e.g., Hive, Hadoop, Mahout, S4/Storm), you only have to learn one programming paradigm. For SQL enthusiasts, the added bonus is that Shark tends to run faster than Hive. If you want to run Spark in the cloud, there are a set of EC2 scripts available.