- idb (Github) — a tool to simplify some common tasks for iOS pentesting and research: screenshots, logs, plists/databases/caches, app binary decryption/download, etc. (via ShmooCon)
- Twitter Infrastructure — an interview with Raffi Krikorian, VP of Platform Engineering. Details on SOA, deployment schedule, rollouts, and culture. (via Nelson Minar)
- Orbit (Github) — a standalone Javascript lib for data access and synchronization.
- Chromium is the New C Runtime — using Chrome’s open source core as the standard stack of networking, crash report, testing, logging, strings, encryption, concurrency, etc. libraries for C programming.
"Twitter" entries

Four short links: 20 January 2014
iOS Pentesting, Twitter's Infrastructure, JS Data Sync, and Chromium as C Runtime

Tweets loud and quiet
Twitter’s long, long, long tail suggests the service is less democratic than it seems.
Writers who cover Twitter find the grandiose irresistible: nearly every article about the service’s IPO this fall mentioned the heroes of the Arab Spring who toppled dictators with 140-character stabs, or the size of Lady Gaga’s readership, which is larger than the population of Argentina.
But the bulk of the service is decidedly smaller-scale–a low murmur with an occasional celebrity shouting on top of it. In comparative terms, almost nobody on Twitter is somebody: the median Twitter account has a single follower. Among the much smaller subset of accounts that have posted in the last 30 days, the median account has just 61 followers. If you’ve got a thousand followers, you’re at the 96th percentile of active Twitter users. (I write “active users” to refer to publicly-viewable accounts that have posted at least once in the last 30 days; Twitter uses a more generous definition of that term, including anyone who has logged into the service.)
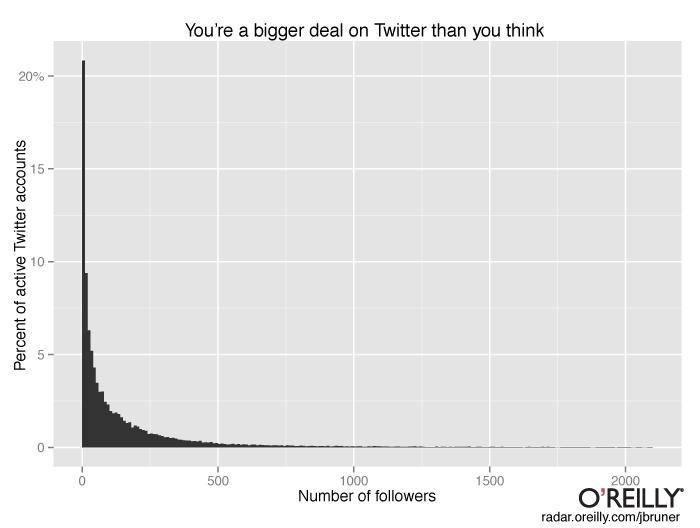
This is a histogram of Twitter accounts by number of followers. Only accounts that have posted in the last 30 days are included. Read more…

The birdie and the shark
Twitter isn't quite beyond jumping the shark, but it has taken a big step backward.
While I’ve been skeptical of Twitter’s direction ever since they decided they no longer cared about the developer ecosystem they created, I have to admit that I was impressed by the speed at which they rolled back an unfortunate change to their “blocking” feature. Yesterday afternoon, Twitter announced that when you block a user, that user would not be unsubscribed to your tweets. And sometime last night, they reversed that change.
I admit, I was surprised by the immediate outraged response to the change, which was immediately visible on my Twitter feed. I don’t block many people on Twitter — mostly spammers, and I don’t think spammers are interested in reading my tweets, anyway. So, my first reaction was that it wasn’t a big deal. But as I read the comments, I realized that it was a big deal: people complaining of online harassment, trolls driving away their followers, and more.
So yes, this was a big deal. And I’m very glad that Twitter has set things right. In the past years, Twitter has seemed to me to be jumping the shark in small steps, rather than a single big leap. If you think about it, this is how it always happens. You don’t suddenly wake up and find you’ve become the evil empire; it’s a death of a thousand cuts. Read more…
Podcast: news that reaches beyond the screen
Finding ways to make media interact with the physical world
Reporters, editors and designers are looking for new ways to interact with readers and with the physical world–drawing data in through sensors and expressing it through new immersive formats.
In this episode of the Radar podcast, recorded at News Foo Camp in Phoenix on November 10, Jenn and I talk with three people who are working on new modes of interaction:
- Mark Trammell, of Sonos, previously of Obama HQ and Twitter
- Rebekah Monson, of the University of Miami
- Robert Hernandez, of the University of Southern California’s Annenberg School
Along the way:
- SensorSub, a project Rebekah is working on that uses data-gathering submarines to measure water quality
- Robert’s students are working on augmented-reality projects at the Los Angeles Central Library–building story-time experiences for children and interpreting the library’s famous murals
- How a lengthier sign-up process brought more people onto Twitter
- Mark’s efforts to understand user interaction on physical hardware
- Wise Kaplan and Cranky Kaplan, the fictional Twitter alter-egos of former New York Observer editor Peter Kaplan, who passed away shortly after we recorded this episode. In the same vein: Mayor Emanuel, Twitter satire from Dan Sinker that was subsequently anthologized.
- Snow Fall
For more on the intersection of software and the physical world, be sure to check out Solid, O’Reilly’s new conference program about the collision of real and virtual.
Subscribe to the O’Reilly Radar Podcast through iTunes, SoundCloud, or directly through our podcast’s RSS feed.

Twitter’s Most Fundamental Value
Twitter could be so much better than an advertising company
We can now gather from Twitter’s IPO that it’s fundamentally postured as an advertising company, but its real value isn’t in advertising. Twitter’s most fundamental value rests squarely within data analytics. However, just because Twitter could make a lot of money in advertising doesn’t mean that advertising is where it should concentrate the majority of your efforts or where its most fundamental value proposition lies.
More specifically, Twitter’s most fundamental value is in the overall collective intelligence of its user base when interpreted as an interest graph. Think of an interest graph as a mapping of people to their interests. In other words, if you follow an account on Twitter, what you’re really saying is that you’re interested in that account. Even though there’s lots to be gleaned in all of the little 140 character quips associated with a particular account, there’s a good bit you can tell about a person by solely examining the accounts that the person follows.
Investigating the Twitter Interest Graph
Why Is Twitter All the Rage?
I’m presenting a short webcast entitled Why Twitter Is All the Rage: A Data Miner’s Perspective that is loosely adapted from material that appears early in Mining the Social Web (2nd Ed). I wanted to share out the content that inspired the topic. The remainder of this post is a slightly abridged reproduction of a section that appears early in Chapter 1. If you enjoy it, you can download all of Chapter 1 as a free PDF to learn more about mining Twitter data.
Read more…
Writing Paranoid Code
Computing Twitter Influence, Part 2
In the previous post of this series, we aspired to compute the influence of a Twitter account and explored some relevant variables to arriving at a base metric. This post continues the conversation by presenting some sample code for making “reliable” requests to Twitter’s API to facilitate the data collection process.
Given a Twitter screen name, it’s (theoretically) quite simple to get all of the account profiles that follow the screen name. Perhaps the most economical route is to use the GET /followers/ids API to request all of the follower IDs in batches of 5,000 per response, followed by the GET /users/lookup API to retrieve full account profiles for up to Y of those IDs in batches of 100 per response. Thus, if an account has X followers, you’d need to anticipate making ceiling(X/5000) API calls to GET /followers/ids and ceiling(X/100) API calls toGET /users/lookup. Although most Twitter accounts may not have enough followers that the total number of requests to each API resource presents rate-limiting problems, you can rest assured that the most popular accounts will trigger rate-limiting enforcements that manifest as an HTTP error in RESTful APIs.
Four short links: 3 October 2013
USB in Cars, Capture Presentations, Amazon Redshift, and Polytweeting
- Hyundia Replacing Cigarette Lighters with USB Ports (Quartz) — sign of the times. (via Julie Starr)
- Freeseer — free, open source, cross-platform application that captures or streams your desktop—designed for capturing presentations. Would you like freedom with your screencast?
- Amazon Redshift: What You Need to Know — good write-up of experience using Amazon’s column database.
- GroupTweet — Allow any number of contributors to Tweet from a group account safely and securely. (via Jenny Magiera)
Computing Twitter Influence, Part 1: Arriving at a Base Metric
The subtle variables affecting a base metric
This post introduces a series that explores the problem of approximating a Twitter account’s influence. With the ubiquity of social media and its effects on everything from how we shop to how we vote at the polls, it’s critical that we be able to employ reasonably accurate and well-understood measurements for approximating influence from social media signals.
Unlike social networks such as LinkedIn and Facebook in which connections between entities are symmetric and typically correspond to a real world connection, Twitter’s underlying data model is fundamentally predicated upon asymmetric following relationships. Another way of thinking about a following relationship is to consider that it’s little more than a subscription to a feed about some content of interest. In other words, when you follow another Twitter user, you are expressing interest in that other user and are opting-in to whatever content it would like to place in your home timeline. As such, Twitter’s underlying network structure can be interpreted as an interest graph and mined for insights about the relative popularity of one user when compared to another.
Read more…
Mining One Million Tweets About #Syria
Surprising social media stats

I’ve been filtering Twitter’s firehose for tweets about “#Syria” for about the past week in order to accumulate a sizable volume of data about an important current event. As of Friday, I noticed that the tally has surpassed one million tweets, so it seemed to be a good time to apply some techniques from Mining the Social Web and explore the data.
While some of the findings from a preliminary analysis confirm common intuition, others are a bit surprising. The remainder of this post explores the tweets with a cursory analysis addressing the “Who?, What?, Where?, and When?” of what’s in the data.