
How to leverage the browser cache with a CDN
An introduction to multi-level caching.

Since a content delivery network (CDN) is essentially a cache, you might be tempted not to make use of the cache in the browser, to avoid complexity. However, each cache has its own advantages that the other does not provide. In this post I will explain what the advantages of each are, and how to combine the two for the most optimal performance of your website.
Why use both?
While CDNs do a good job of delivering assets very quickly, they can’t do much about users who are out in the boonies and barely have a single bar of reception on their phone. As a matter of fact, in the US, the 95th percentile for the round trip time (RTT) to all CDNs is well in excess of 200 milliseconds, according to Cedexis reports. That means at least 5% of your users, if not more, are likely to have a slow experience with your website or application. For reference, the 50th percentile, or median, RTT is around 45 milliseconds.
So why bother using a CDN at all? Why not just rely on the browser cache?

10 Elasticsearch metrics to watch
Track key metrics to keep Elasticsearch running smoothly.
Elasticsearch is booming. Together with Logstash, a tool for collecting and processing logs, and Kibana, a tool for searching and visualizing data in Elasticsearch (aka, the “ELK” stack), adoption of Elasticsearch continues to grow by leaps and bounds. When it comes to actually using Elasticsearch, there are tons of metrics generated. Instead of taking on the formidable task of tackling all-things-metrics in one blog post, I’ll take a look at 10 Elasticsearch metrics to watch. This should be helpful to anyone new to Elasticsearch, and also to experienced users who want a quick start into performance monitoring of Elasticsearch.
Most of the charts in this piece group metrics either by displaying multiple metrics in one chart, or by organizing them into dashboards. This is done to provide context for each of the metrics we’re exploring.
To start, here’s a dashboard view of the 10 Elasticsearch metrics we’re going to discuss:
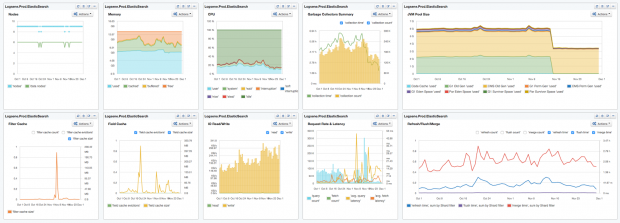
10 Elasticsearch metrics in one compact SPM dashboard. This dashboard image, and all images in this post, are from Sematext’s SPM Performance Monitoring tool.
Now, let’s dig into each of the 10 metrics one by one and see how to interpret them.

From Industrialism to Post-Industrialism
Leveraging the power of emergence to balance flexibility with coherency.

Download
Building an Optimized Business
Download a free copy of Building an Optimized Business, a curated collection of chapters from the O’Reilly Web Operations and Performance library. This post is an excerpt by Jeff Sussna from Designing Delivery, one of the selections included in the curated collection.
In 1973, Daniel Bell published a book called “The Coming of Post-Industrial Society”. In it, he posited a seismic shift away from industrialism towards a new socioeconomic structure which he named ‘post-industrialism’. Bell identified four key transformations that he believed would characterize the emergence of post-industrial society:
- Service would replace products as the primary driver of economic activity
- Work would rely on knowledge and creativity rather than bureaucracy or manual labor
- Corporations, which had previously strived for stability and continuity, would discover change and innovation as their underlying purpose
- These three transformations would all depend on the pervasive infusion of computerization into business and daily life
If Bell’s description of the transition from industrialism to post-industrialism sounds eerily familiar, it should. We are just now living through its fruition. Every day we hear proclamations touting the arrival of the service economy. Service sector employment has outstripped product sector employment throughout the developed world. 1
Companies are recognizing the importance of the customer experience. Drinking coffee has become as much about the bar and the barista as about the coffee itself. Owning a car has become as much about having it serviced as about driving it. New disciplines such as service design are emerging that use design techniques to improve customer satisfaction throughout the service experience.

Chaos Monkey for systems of people: The ultimate performance hack
The O'Reilly Radar Podcast: Alois Reitbauer on performance hacking, DevOps applications, and fostering a culture of respect.

Subscribe to the O’Reilly Radar Podcast to track the technologies and people that will shape our world in the years to come.
In this week’s episode of the Radar Podcast, O’Reilly’s Courtney Nash chats with Alois Reitbauer, chief evangelist at Ruxit, about how DevOps is deeply woven into the Ruxit culture. Reitbauer also talks about how the term “performance hacking” came about at Ruxit, why Chaos Monkey should be applied to systems of people, and why trust across — and between — all departments in an organization is essential.
DevOps beyond DevOps
Performance hacking is a term that emerged at Ruxit about a year ago as the company prepared for the beta launch, Reitbauer said, when they realized as the company scaled up, they needed to bring everyone from all their teams together. “The idea of performance hacking, then,” he noted, “was really, how can we scale up this collaboration between the DevOps teams, the product development teams, and our go-to-market growth hacking teams while we grow as an organization.” The ultimate aim was to figure out how to continue to act like a three-person, one-room startup as the company scaled to a couple hundred people.
One of the approaches embraced at Ruxit is to apply some of the DevOps best practices to their growth hacking and product development strategies. As an example, Reitbauer offered up the idea of Chaos Monkey, as applied not to AWS instances, but to the organization as a whole. The way it works, he explained, is to send a member of a team — any team — away on short notice (or no notice) and see what breaks. Reitbauer said that they’d actually done this and outlined what they learned from the exercise:
We have done it, and it also came up as part of our regular organizational practices. Like, when we had our first very strong conference season — we sent people to different shows all over the place; we picked people from the team who had to go somewhere. And even if people knew they were going to be out of the office in a couple of weeks, they still started to behave as if they would be around all the time, that they wouldn’t be leaving the office. Then, suddenly they were on a plane. They had no time to do their everyday work, and suddenly they realized where they really needed help. So, you don’t even have to make it a total surprise. You just have to plan how to get people out of their regular working behavior to do something else. Then we were able to figure out, ‘We really need somebody else to be able to jump in here or to help somebody out over there.’ It might be a regular holiday or just not daily routine.
The Puppet design philosophy
Explore the declarative, idempotent, and stateless Puppet DSL.

Before we begin to explore practical best practices with Puppet, it’s valuable to understand the reasoning behind these recommendations.
Puppet can be somewhat alien to technologists who have a background in automation scripting. Where most of our scripts are procedural, Puppet is declarative. While a declarative language has many major advantages for configuration management, it does impose some interesting restrictions on the approaches we use to solve common problems.
Although Puppet’s design philosophy may not be the most exciting topic to begin this book, it drives many of the practices in the coming chapters. Understanding that philosophy will help contextualize many of the recommendations covered.

Open source won, so what’s next?
What to expect at OSCON 2015.

Twenty years ago, open source was a cause. Ten years ago, it was the underdog. Today, it sits upon the Iron Throne ruling all it surveys. Software engineers now use open source frameworks, languages, and tools in almost all projects.
When I was putting together the program for OSCON with the other program chairs, it occurred to me that by covering “just” open source, we weren’t really leaving out all that much of the software landscape. It seems open source has indeed won, but let’s not gloat; let’s make things even better. Open source has made many great changes to software possible, but the spirit of the founding community goes well beyond code. Read more…