
Long Tail evidence from Safari and Google Book Search
Last fall, I came to the defense of Google against lawsuits by the Author's Guild and Association of American Publishers, arguing that Google Book Search would help readers to rediscover works that were no longer commercially available. I pointed out, in fact, that only about 4% of all titles ever published are still being commercially exploited. (Kevin Kelly wrote a long report on the current state of book scanning initiatives in yesterday's New York Times Magazine.)
A recent study by Roger Magoulas and Ben Lorica of O'Reilly Research provided strong data to support the assertion that online access drives usage of content that is generally not available in print. We compared sales reported through Nielsen Bookscan for the fourth quarter of 2005 with access logs from both O'Reilly's Safari Books Online service and from Google Book Search. The result provides compelling support for Chris Anderson's "long tail" theory.
The methodology we used was to divide the titles in the Bookscan top 10,000 into deciles. We then plotted the number of Safari views for the books in each decile. As you can see from the graph below, the top 10% of print titles delivered 53% of all unit sales. Those same titles provided 25% of Safari page views. By the second 10% of print titles, the relative level of access is very close, at 19% and 18% respectively, and by the third decile, there is a greater percentage of Safari page views for the titles than the percentage of books sold. Out at the end of the tail, you can see substantial Safari usage of books that for all practical purposes didn't sell any copies in print. (Titles in the lowest deciles may have sold only a single copy during the period in question, rounding to zero.) Fully 7% of page views in Safari is for books that are not selling at all in print; 20% of access is to books generating only 5% in print book sales; and 29% is to books generating only 9% of print book sales.
You can see how steep the print sales graph is, and how much flatter the online access graph is. Note how the Safari graph actually rises out at the end of the tail.

With Google Book Search, which has even older books (Safari includes only books going back to 2000), the effect is even more striking. 27% of page views come from books generating only 2% of unit sales, and fully 47% come from books generating only 9% of unit sales!

We believe that one reason that the Google Book Search graph is even flatter than the Safari graph is that it represents raw, unprompted search activity. Safari announces new titles when people first login to the service, and this marketing drives up the percentage of access to the most popular titles. With the "Safari Enabled" program, people are also able to use Safari for access to books that they've already bought in print.
Roger wrote: "[Note] the sharp contrast between the way computer books are distributed on BookScan - with a great concentration in the first two deciles of 72% of sales (pretty darn close to Pareto 80/20) - and the way access is distributed for users of Google Book Search (GBS) - a relatively even distribution with far less concentration in the top BookScan deciles and an uptick in the lowest BookScan decile. Take out availability, distribution and inventory considerations and GBS shows a more equitable distribution of interest across computer book titles - the rattlesnake tail."
Roger's mention of "the rattlesnake tail" is a reference to an earlier study done by Andrew Odewahn comparing Safari usage to Bookscan sales. The graph that Andrew produced showed a curious spike in usage out at the end of the tail. You can see why we called this effect the rattlesnake tail:
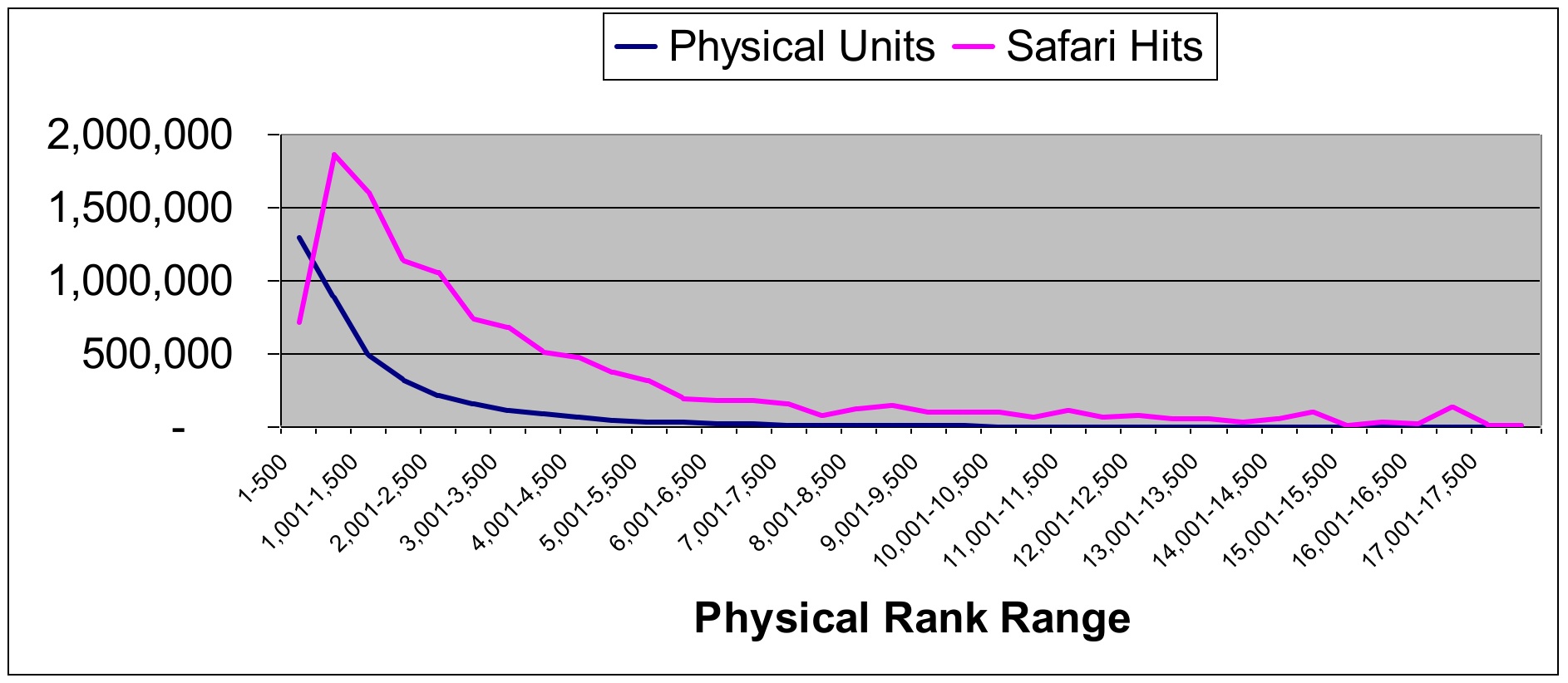
Rather than dividing the titles into deciles, Andrew used groups of 500 titles. And even though the study is based on the Bookscan Top 10,000 computer books report, you'll notice that the graph shows 17,500 titles. The reason is that during the period of the study, the first 6 months of 2005, 17,754 distinct SKUs (ISBN’s) appeared in the report at least once. Andrew ranked the 17,754 books by total unit sales and divided them into blocks of 500 based on their unit sales. He then measured the Safari page views for the books in each block.
The rattlesnake tail became even more pronounced when Andrew plotted the average weekly unit sales against the average weekly Safari page views for each title:
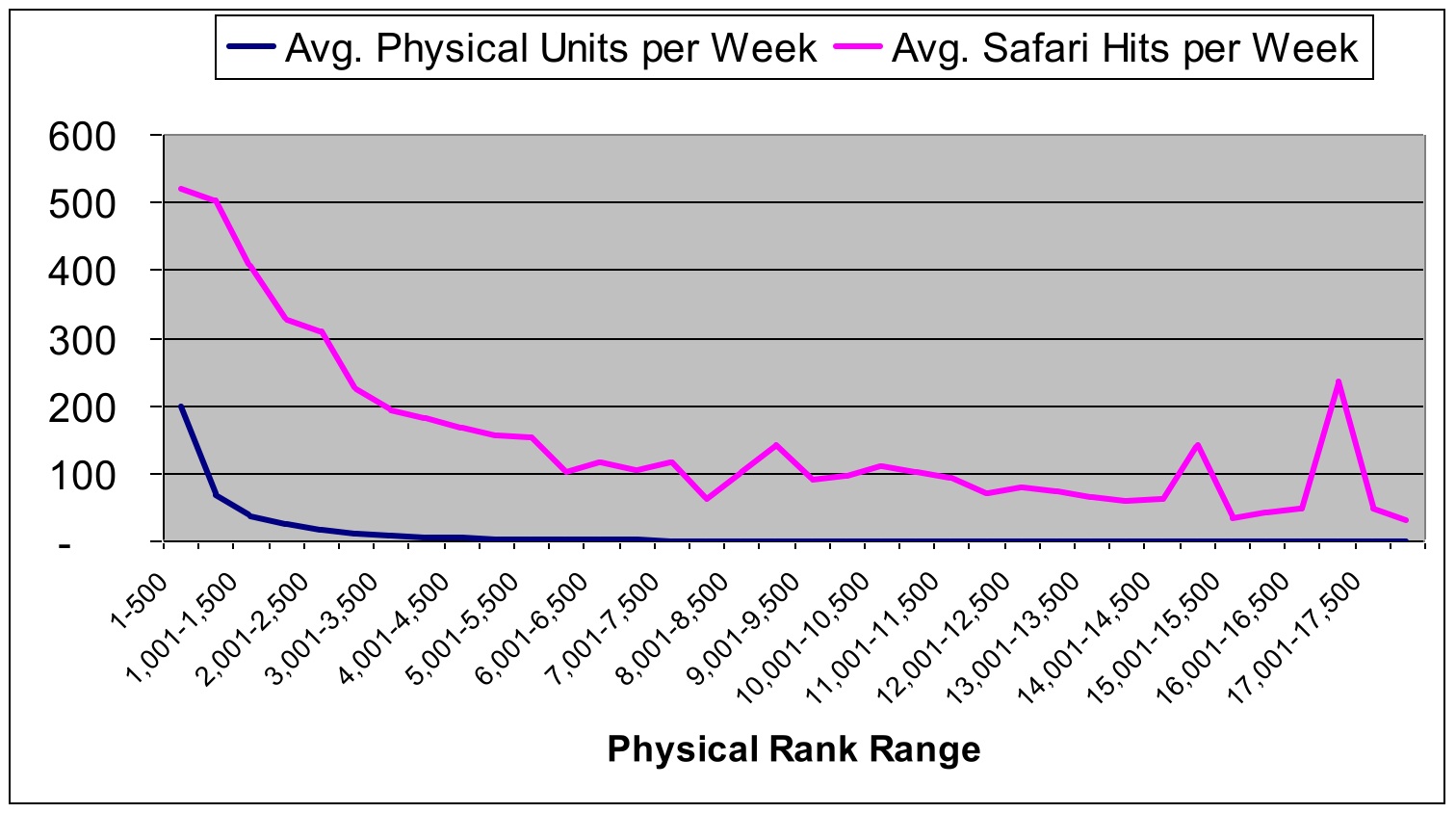
We determined that some of the rattlesnake spike was the result of user error -- people might, for example, use an older edition of a book for which a newer version was available. But a significant percentage of that usage was for old books for which no newer version was available. (You can guess that we'll soon be bringing back older books for download sales or print-on-demand!)
Using a Bookscan rank of 4,500 as a cutoff, Andrew also computed rough estimates for the long tail effect using proportions of unit sales and views:
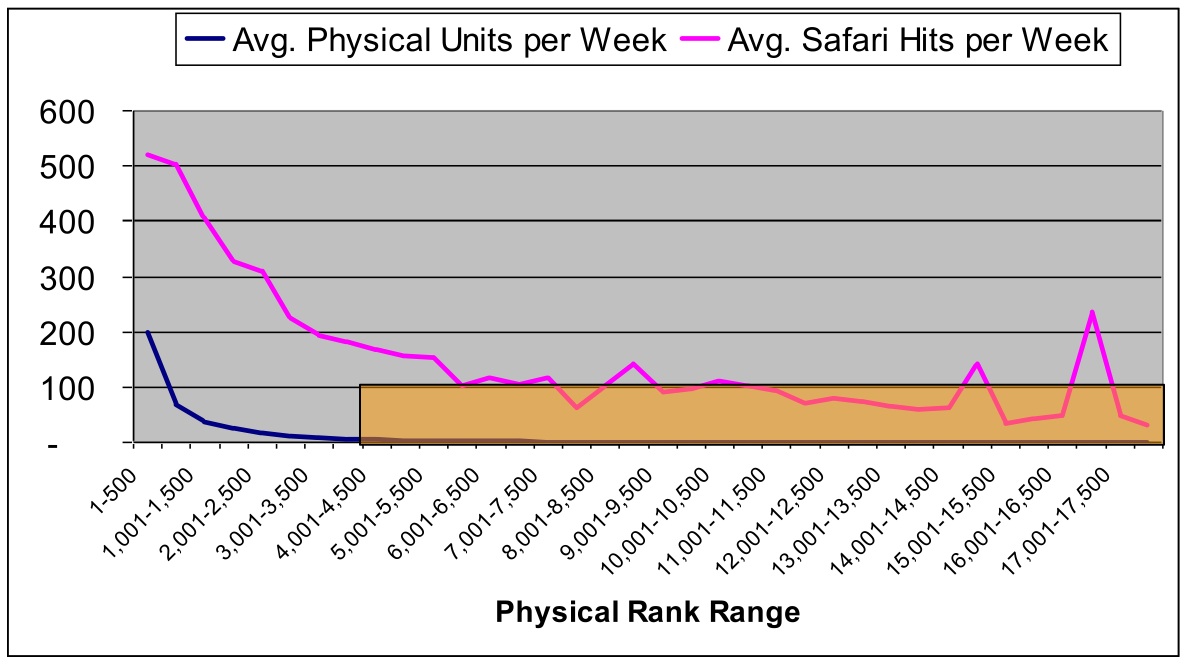
A Bookscan rank of 4500 to mark the start of the long tail is quite generous. At that level, a book is selling only a few copies a week nationwide. Just eyeballing the graph, you'd put the long tail cutoff at perhaps 3000! But even setting the bar at 4500, Andrew concluded that 23% of Safari views came from 6% of physical book sales.
While my support for Google against the AAP was driven primarily by the considerations that I outlined in the articles I linked to at the start of this piece, Andrew's study gave me hard data that supported my reasoning. Roger and Ben's more recent work has confirmed it. There is significant demand for books that are generally unavailable in print.
Notes on data sources and methodology
As described in previous Radar postings, our Bookscan data mart contains weekly point-of-sale data on the top 10,000 computer books aggregated by Nielsen from retailers such as Barnes & Noble, Amazon, Borders, and major independent booksellers. The Safari data is for O'Reilly and Pearson books only (plus a few other publishing partners who have only some of their books in Safari). For example, of the 17,754 physical ISBNs in Andrew's study, 2,171 were available through Safari. The Google Book Search data is for O'Reilly books only, a total of 683 titles.
We don't have access to other publishers' data, but would be interested to do a similar analysis given access to that data. We would be particularly interested in working with publishers outside the technical books area.
tags: web 2.0
| comments: 17
| Sphere It
submit: ![]()
![]()
![]()
![]()
0 TrackBacks
TrackBack URL for this entry: http://blogs.oreilly.com/cgi-bin/mt/mt-t.cgi/4659
Comments: 17
Interesting conclusions - but doesn't sorting by Bookscan ratings bias the conclusions? The Safari and Google Books graphs could be similarly steep if sorted by the relevant popularity. If so, it wouldn't be that Google Books has a particularly long tail, but that its users choose different books.
Sorry, but, huh?
You are making argument that there is some utility (and perhaps profit for a few copyright holders) in Google's action. I don't know of any serious critic of Google who would dispute those claims, do you? There is no reason to set about proving those claims -- for the sake of argument we can stipulate them.
The objections are in two forms.
First, the actions Google stated it would take at the outset of this project seem to many of us to plainly violate copyright law, pure and simple. It would require a rather extraordinary argument to explain why a corporation's lawless behavior ought to be celebrated rather than punished, or how it is that Google's plan does not violate copyright law.
Second, while there is utility in having all of these books scanned, this does not lead to the conlusion that a particular search company should wind up with a commercial monopoly on the results. Especially when it comes to rare and older books, the number of opportunities to scan them is small -- precious. Where is the argument that society ought to bargain away rights to perform this scanning to a monopoly?
-t
What all that doesn't say is what the effect on booksales is of Google plagiarising books that are in print (or harder still, have in-print equivalents that people would otherwise purchase).
If Google puts online say an old Wrox book for teaching HTML, what impact does that have on the sales of current O'Reilly titles about the same material?
And what effect does Google making available the texts of books that are available commercially through Safari have on the sale of those books through Safari (let alone printed versions)?
A lot of people aren't going to pay for something they can get for free, as is made painfully clear by the continuing decline in software, movie, and music sales as piracy became ever more prevalent for those mediums.
Now people have a source for pirated books as well, cheaper and more accessible than going to the library and copying the chapters they're interested in for 5 cents per page (or more).
I'm curious what percentage of the "long tail" can be explained by expired copyrights and therefore free access. I understand that in Safari all books are accessible after subscription, but in GBS a number of books only allow limited viewing. It doesn't strike me as much of a surprise that free access would stimulate increased consumption, and this alone would not prove that consumers have moved away from more conventional consumption patterns. Thanks! -Andrew
Tim,
You should contact Lightning Source and see if they are interested in sharing data with you. Kriby Best recently confirmed that their average print run is 1.8 copies, and that the majority of their sales come from tradional publishers, not author services (ie, subsidy presses). They'd need to sanitize the data in some way, I'd have to look at my own contract to see what they say about privacy of publisher data, but it might be worth their while as it could help them promote their services traditional publishers who remain unconvinced that thar's gold in that backlist. It would amount to one-stop-shopping for the data you're looking for:-)
Chris --
I'm sorry I didn't make it clearer. The data displayed is for the intersection of the two data sets. That is, for the Safari graph, it's for the 2100-odd books that appeared in both the Bookscan top 10,000 AND in Safari. Books that don't appear in both sources are not represented in the Bookscan graph.
In Andrew Odewahn's study, books must have had at least one sale in Bookscan during the study period (the first half of 2005) AND have been published prior to 2005. He did this with newly published books, you would have had a couple of artifacts: on the one hand, you might have had books with only a few weeks of sales, but you'd also have the skew that new books tend to have a surge in sales. It's probably worth comparing the graphs without the "published prior to the study period" limit.
For the more recent study, it turns out that the Bookscan data set is a little broader: it includes any books that appeared at any time in our three years of Bookscan data, and then finds the intersection of that data set with books in Safari or, for the other graph, for O'Reilly books in Google Book Search. As a result, in this study, we are comparing books in Safari or GBS with books that may have had zero Bookscan sales in the study period, rather than at least one unit sold.
5/17 Correction on my clarification: Roger and Ben tell me that in order to make the data sets consistent, that for the Safari study they *didn't* use the 2100 books that were in both Bookscan and Safari. Instead, both studies use only the 650 or so O'Reilly titles that appear in all three data sets. (Andrew's earlier study used the intersection of Safari and Bookscan, about 2100 titles.)
Tom --
First off, all the books in the study are in Google Book Search by permission. Most publishers have been happy to cooperate with GBS because of the richness of the information that Google gives back about access, and the fact that Google allows publishers to opt out if they change their mind.
The controversy is around the Google Library project, which involves scanning of library collections. As I argued in the articles I linked to at the beginning of this piece, most of these books are in the twilight zone, where publishers have no incentive to bring them back into print. But more to the point, Google is not actually displaying the contents of these books unless they know they are in the public domain, or have been opted in by publishers. They are simply showing snippets, just like they do on the web. If it's copyright infringement for Google to build an search engine for book content, then it's also copyright infringement for them to make a search engine for web content. As long as Google doesn't actually show the content, I don't believe that this is copyright infringement.
Jeroen --
In our data, we saw no loss of print book sales as a result of Google Book Search. There are a lot of restrictions on how much of a book you can use, so it isn't really a substitute.
Andrew --
In the study in question, there should be no effect from books that are out of copyright and thus allow full viewing, since the analysis is of contemporary computer books only.
Wow! This was expected but it's always great to read that it's confirmed too.
It would be quite interesting to discover the real reason behind the rattlesnake spike. This may be related to older books added to pre-populated bookshelves for corporate accounts or e-learning companies. Or are these numbers just for B2C?
Hasn't the spike to do with the relative need of the purchaser for the information in question, and their following through with the purchase because of their need for an actual copy of an otherwise unavailable text? Substantial physical sales within the past decade result in high consumer familiarity with those works. One rarely purchases new what one has used. The relative unavailability and merit of the books in question demands their actual purchase when needed, as a snippet can't be enough to remind the reader of something yet unread.
Hasn't the spike to do with the relative need of the purchaser for the information in question, and their following through with the purchase because of their need for an actual copy of an otherwise unavailable text? Substantial physical sales within the past decade result in high consumer familiarity with those works. One rarely purchases new what one has on-hand used. The relative unavailability and merit of the books in question demands their actual purchase when needed, as a snippet can't be enough to remind the reader of something yet unread.
(www.CaffeineMarketing.com)
Yes I too have been reading this book. Alright so Chris Anderson developed The Long Tail Theory in Wired magazine back in 2004 to describe how economic business models of Amazon.com, Netflix, and others have created their riches. His book only recently came out.
The problem with this book is that the focus is purposely too broad to appeal to a wider audience and increase book sales. Even the author of “The Purple Cow“, Seth Godin told me that he wanted to appeal to a broad audience to help increase book sales. Think of how multi-level marketing and being an IBO works. Everyone sees how easy it is and thinks they will be able to make money when in reality the appeal is soo broad that the market becomes over cluttered.
The bottom line: Don’t think of every marketing book out there as a great resource. A great marketer who writes a marketing book is looking to.. of course… market their book to the largest audience to generate the most sales. Just don’t expect every book out there to solve your problems.
I don't see the big deal. People lend books all day. Information is information. I posted a whole book's worth of content on my sales and marketing site ( http://www.salesandmarketinghelp.com ) when I could just have easily published a book with the content. People who want to read books will still buy books, people looking for content online, would probably not buy the book anyway. They will find similar content on good websites. If anything, this is great exposure for the authors.
Long tail is the way to go... Our site has gotten much better since we have edited our pages to adapt to "long tail" searchers. :)
The numeric data for Google Book Search is excellent. I just found numbers from Google that confirm long tail effect for GBS.
BTW -- The links for most of the graph images in the posting are broken. My article above has the corrected GBS image.
Post A Comment:
STAY CONNECTED
RECENT COMMENTS
- Eric Rumsey on Long Tail evidence from Safari and Google Book Search: The numeric data for Go...
- Jonathan on Long Tail evidence from Safari and Google Book Search: Long tail is the way to...
- joe on Long Tail evidence from Safari and Google Book Search: I don't see the big dea...
- Matthew Peschong on Long Tail evidence from Safari and Google Book Search: (www.CaffeineMarketing....
- Anonymous on Long Tail evidence from Safari and Google Book Search: Hasn't the spike to do ...
- joshua irish on Long Tail evidence from Safari and Google Book Search: Hasn't the spike to do ...
- Bernard Struyf on Long Tail evidence from Safari and Google Book Search: Wow! This was expected ...
- Tim O'Reilly on Long Tail evidence from Safari and Google Book Search: Andrew -- In the study...
- Tim O'Reilly on Long Tail evidence from Safari and Google Book Search: Jeroen -- In our data,...
- Tim O'Reilly on Long Tail evidence from Safari and Google Book Search: Tom -- First off, all ...
RADAR TOPICS
chris anderson [05.15.06 07:32 AM]
Tim,
Brilliant analysis, Tim. Just one point of clarification, please. The 10,000 book in Bookscan and Safari are different books, yes? In other words, they're reporting the top 10,000 books overall, while you're showing the top 10,000 Safari books (no doubt there's some overlap).
Just checking to make sure I'm understanding correctly...
Chris