
Operations is a competitive advantage... (Secret Sauce for Startups!)
My lunchtime conversations at the Summit centered around Operations as a competitive advantage (and occasionally a "strategic weapon"). This advantage is the ability to consistently create and deploy reliable software to an unreliable platform that scales horizontally.
Many people think of Operations as "a bunch of boring work... which I'm hoping someone else is doing." It often takes less time to set up a development environment than the tools and infrastructure needed to test, deploy, monitor, and scale new software. The survival of most projects depend on working software, at least initially, and so if there is money or time many people will spend it on development. Unfortunately, people say they will "figure that ops stuff out soon", but what they mean is "when we're totally screwed!!!" It doesn't have to be that way...
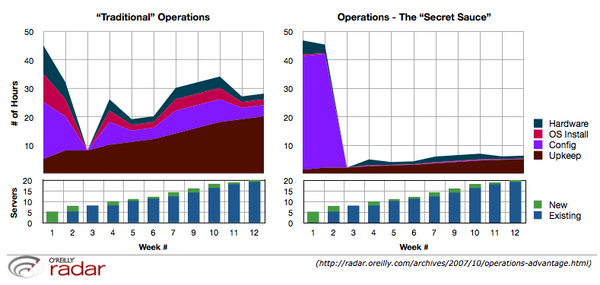

The example above is the tale of two Web 2.0 startups scaling to 20 systems during their first three months. The first team starts writing software and installing systems as they go, waiting to deal with the "ops stuff" until they have an "ops person". The second team dedicates someone to infrastructure for the first few weeks and ramps up from there. They won't need to hire an "ops person" for a long time and can focus on building great technology.
In my experience it takes about 80 hours to bootstrap a startup. This generally means installing and configuring an automated infrastructure management system (puppet), version control system (subversion), continuous build and test (frequently cruisecontrol.rb), software deployment (capistrano), monitoring (currently evaluating Hyperic, Zenoss, and Groundwork). Once this is done the "install time" is reduced to nearly zero and requires no specialized knowledge. This is the first ingredient in "Operations Secret Sauce".
This kind of scaleability becomes really interesting when you find yourself suddenly popular, as iLike did when it launched its Facebook app and had to scale up fast (Radar):
In our first 20 hours of opening doors we had 50,000 users sign up, and it is only accelerating. (10,000 users joined in the first 12 hrs. 10,000 more users in the next 3 hrs. 30,000 more users in the next 5 hrs!!)
We started the system not knowing what to expect, with only 2 servers, but ready with backup. Facebook's rabid userbase chewed up our 2 servers almost instantly. We doubled our capacity to catch up. And then we doubled it again. And again. And again. Oh crap - we ran out of servers!! Although iLike.com has a very healthy level of Web traffic, and even though about half of all the servers in our datacenter were sitting unused, idle, as backup capacity, we are now completely maxed out.
We just emailed everybody we knjow across over a dozen Bay Area startups, corporations, and venture firms in a desperate plea to find spare servers so we can triple our capacity for the continued onslaught. Tomorrow we are picking up over 100 servers from different companies to have them installed just to handle the weekend's traffic. (For those who responded to our late night pleas, thank you!)
Not being able to acquire hardware fast enough is by far a better problem than not being able to install it. iLike is something of a poster-child for puppet.
Are any VCs out there including effective operations in their due-dilligence? Are startups incorporating this in their pitch? (Amazon seems to be pushing this as part of the AWS "Start-Up Project" if you're using S3 and EC2)
Update: Luke points out Adam Jacob's post about implementing Puppet for iLike. (Disclosure: I'm discussing collaboration with Adam's company, HJK solutions.)
Update #2: John Allspaw of Yahoo/Flickr fame has great commentary on procurement and capacity management challenges for successful startups.
Adam says:
Puppet enables us to get a huge jump-start on building automated, scaleable, easy to manage infrastructures for our clients. Using puppet, we:
- Automate as much of the routine systems administration tasks as possible.
- Get 10 minute unattended build times from bare metal, most of which is data transfer. Puppet takes it the rest of the way, getting the machines ready to have applications deployed on them. It’s down to two and a half minutes for Xen.
- Bootstrap our clients production environments while building their development environment. I can’t stress how cool this really is. Because we are expressing the infrastructure at a higher level, when it comes time to deploy your production systems, it’s really a non-event. We just roll out the Puppet Master and an Operating System auto-install environment, and it’s finished.
- Cross-pollinate between clients with similar architectures. We work with several different shops using Ruby on Rails, all of whom have very similar infrastructure needs. By using Puppet in all of them, when we solve a problem for one client, we’ve effectively solved it for the others. I love being able to tell a client that we solved a problem for them, and all it’s going to cost is the time it takes for us to add the recipe.
Sounds good to me.
tags: operations, startups, web 2.0
| comments: 13
| Sphere It
submit: ![]()
![]()
![]()
![]()
0 TrackBacks
TrackBack URL for this entry: http://blogs.oreilly.com/cgi-bin/mt/mt-t.cgi/5992
Comments: 13
This article isn't clear on it, but iLike actually used Puppet to scale with all of those new machines:
http://blog.hjksolutions.com/articles/2007/08/31/puppet-ilike-and-infrastructure-2-0
(I'm the author of Puppet, but iLike isn't a client of mine and I'm not that author of that post.)
@John - I think there are a few companies already doing that. More interesting to me is a company that does this across multiple computing/storage grid providers!
@Luke - Thanks for the link, and for Puppet!
IMHO, bringing up ops considerations early in the process of product design should be a priority. Having at least some awareness of operational constraints can pay off significantly later on.
I might even add that while not being able to acquire hardware fast enough is by far a better problem, streamlining your procurement process should be also considered part of the whole system. We've had to learn a bit of that at Flickr, just like iLike. :)
As usual: great post, Jesse.
-deployment should be part of every project, be it startup or in-house. all too often, the Enterprise specs (say, EJB) make assumptions that you have some process that involves people editing XML files in a GUI as part of the release process -the reality is that nobody wants to waste time on the dull bits.
-if you can bring up a system and deploy to it during the build, then you get to do functional testing on it.
-if your apps diagnostics are in a form that the ops team can use and understand, then everyone benefits.
I think where startups are special is there is less of a barrier between ops and dev; ideally: none. There is also the need to ramp up capacity based on demand, without the money to invest in custom datacentres. Outsourcing your servers to server farms is the sensible action here -and once you do that, the value of automating deployment really pays off.
But again, what's to stop the enterprises doing that, other than an urge to waste money and people on a problem that has already been solved, and a fear of taking risks.
Steve Loughran, SmartFrog team.
While I agree with Jesse that traditionally operations have been a large part of the secret sauce, I think this demonstrates how broken the current "traditional" operations are.
A software startup should be able to focus on (a) the main/unique value they provide -- their application's primary functionality and (b) how to sell it better.
Operations is a price of entry and should *not* be a differentiator. When each bright new startup needs to figure out the same things over and over again, this brings friction in the process. We as an industry have already figured how to do operations, it shouldn't be hard. It should be productized, as many other former differentiators are (remember the times when each WYSIWYG application had its own GUI system? each content publisher had their own markup language?). The Googles of this world may tell you that you really need to put a lot of money and innovation to build your own datacenters, your own computers from motherboards, etc.... You don't.
A second note: anyone who needs to scale (read: any Web 2.0 company with ambitions, which means, any Web 2.0 company) should carefully look at hosted options. Hosting providers have lots of servers at hand and can deploy 100s of them in a few hours. The iLike story would have been all about how easy it was to scale rather than how they had to beg and borrow servers.
Disclosure: I am the founder of 3Tera, the maker of the AppLogic grid operating system for web applications. Our best partners are hosting providers who offer virtual private datacenters (e.g., The Gridlayer).
Whether you choose our solution or do something different:
- make sure you have the ability to focus on your primary functionality and unique advantage
- ensure that operations are taken care of in the most outsourced way possible
Note to VCs: how long are you going to have the same 1MM or so spent in each startup for the same thing, namely operations? Find a way to not reinvent the wheel for each company (or at least not reinvent the wheels that they can afford not to reinvent
Best,
-- Peter
I agree with you Peter. Building your application to run in a hosted environment requires a similar amount of initial planning and prep, and has the same or greater initial reward.
To address Steve's point about diagnostics:
As a software engineer / developer, I found Michael Nygard's book "Release It!: Design and Deploy Production-Ready Software" really illuminating and supportive of your point. Since reading that book, diagnostics and run-time reporting have become some of my battle-cries. (I'm just challenged by getting the "product owners" to see the value.)
Again, this is from a programming perspective, to effectively scale your application consider avoiding session-state. There are ways to program around this concept. (If you'd like to read an aggressively-titled blog entry on this concept, see http://davidvancouvering.blogspot.com/2007/09/session-state-is-evil.html)
This advantage is the ability to consistently create and deploy reliable software to an unreliable platform that scales horizontally.
I've been in 'operations' most of my career; it suits me. How nice to see that other people get how important that area is.
One problem I've faced is that Operations is easy to ignore; most orgs can't use it to generate revenue, it's not as 'sexy' as development - on a good day in Operations nothing exciting happens, which can lead some to think that whatever money you're spending on that group is easily cut.
But again, what's to stop the enterprises doing that, other than an urge to waste money and people on a problem that has already been solved, and a fear of taking risks.
Define 'Enterprise'? My day job is a mid-sized company, 8,000 employees worldwide. If you define 'enterprise' computing as 24/7 365 we're it.
I am not privy to all of the negotiations but we have looked at this ... and we've not found a host that suits our needs and can beat the costs we incur for maintaining our own data centers.
Outsourcing what makes sense - I"m for it. But for us, at least, it doesn't make sense.
I am going to play devil's advocate and say that in the case of the startup getting the prototype up and running is more important. The application can always be streamlined later, more programming muscle applied, more hardware.
Moreover, having lead programmers involved in operations as you go means that they will know where the sticking points are.
And I agree with Peter that you want to outsource hosting to somebody dedicated to that space. Since we moved our clients to a first class host (Cartika), life has gotten a whole lot simpler.
When we are ready to scale they have a grid in place. We won't have to think about that.
Hi.
Just wondering what in the end you've selected: Hyperic, Zenoss, or Groundwork?
Maybe they need better servers or at least something scalable. Have you guys checked into Sun Microsystem's startup essentials program? Looks like a sweet deal.
Post A Comment:
STAY CONNECTED
RECENT COMMENTS
- Brody on Operations is a competitive advantage... (Secret Sauce for Startups!): Maybe they need better ...
- Stas on Operations is a competitive advantage... (Secret Sauce for Startups!): Hi. Just wondering wha...
- WordPress SEO on Operations is a competitive advantage... (Secret Sauce for Startups!): I am going to play devi...
- Brian on Operations is a competitive advantage... (Secret Sauce for Startups!): But again, what's to st...
- Brian on Operations is a competitive advantage... (Secret Sauce for Startups!): This advantage is the a...
- Nelz on Operations is a competitive advantage... (Secret Sauce for Startups!): To address Steve's poin...
- Jesse Robbins on Operations is a competitive advantage... (Secret Sauce for Startups!): I agree with you Peter....
- Peter Nickolov on Operations is a competitive advantage... (Secret Sauce for Startups!): While I agree with Jess...
- Steve Loughran on Operations is a competitive advantage... (Secret Sauce for Startups!): -deployment should be p...
- John Allspaw on Operations is a competitive advantage... (Secret Sauce for Startups!): IMHO, bringing up ops c...
RADAR TOPICS
John Willis [10.23.07 01:34 PM]
There are some really interesting companies working around S3/EC2. Now you add a little puppet with elastic computing cloud with a touch of serivices now you got yourself a VC play. Opps, I forgot VC's don't like services...
johnmwillis.com