
The need to extract interesting bits of an HTML document comes up often enough that by now we have all seen many ways of doing it wrong and some ways of doing it right for some values of “right”.
One might think that one of the most fascinating answers on Stackoverflow has put an end to the desire to parse HTML using regular expressions, but time and again such a desire proves too tempting.
Let’s say you want to check all the links on a page to identify stale ones, using regular expressions:
use strict;
use warnings;
use feature 'say';
my $re = qr/<as+href=["']([^"']+)["']/i;
my $html = do { local $/; <DATA> }; # slurp _DATA_ section
my @links = ($html =~ m{ $re }gx);
say for @links;
__DATA__
<html><body>
<p><a href="http://example.com/">An Example</a></p>
<!-- <a href="http://invalid.example.com/">An Example</a> -->
</body></html>In this self-contained example, I put a small document in the __DATA__ section. This example corresponds to a situation where the maintainer of the page commented out a previously broken link, and replaced it with the correct link.
When run, this script produces the output:
$ ./href.pl http://example.com/ http://invalid.example.com/
It is surprisingly easy to fix using HTML::TokeParser::Simple. Just replace the body of the script above with:
use HTML::TokeParser::Simple;
my $parser = HTML::TokeParser::Simple->new(handle => *DATA);
while (my $anchor = $parser->get_tag('a')) {
next unless defined(my $href = $anchor->get_attr('href'));
say $href;
}When run, this script correctly prints:
$ ./href http://example.com/
And, it looks like we made it much more readable in the process!
Of course, interesting HTML parsing jobs involve more than just extracting links. While even that task can be made ever-increasingly complex for the regular expression jockey by, say, adding some interesting attributes between the a and the href, code using HTML::TokeParser::Simple would not be affected.
Another specialized HTML parsing module is HTML::TableExtract. In most cases, it makes going through tables on a page a breeze. For example, the State Actions to Address Health Insurance Exchanges contains State Table 2: Snapshot of State Actions and Figures.
The contents of this page may change with new developments, so here is a screenshot of the first few lines of the table:
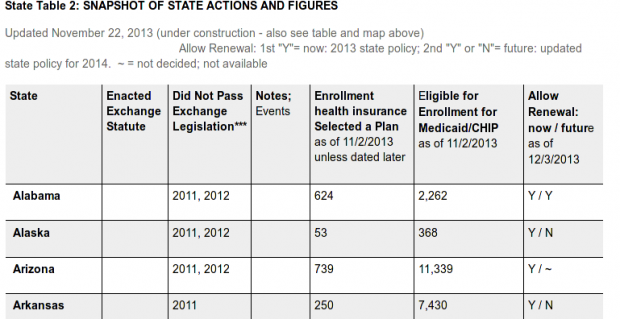
Parsing this table using HTML::TableExtract is straightforward:
use HTML::TableExtract;
use Text::Table;
my $doc = 'state-actions-to-implement-the-health-benefit.aspx';
my $headers = [ 'State', 'Selected a Plan' ];
my $table_extract = HTML::TableExtract->new(headers => $headers);
my $table_output = Text::Table->new(@$headers);
$table_extract->parse_file($doc);
my ($table) = $table_extract->tables;
for my $row ($table->rows) {
clean_up_spaces($row); # not shown for brevity
$table_output->load($row);
}
print $table_output;Running this script yields:
$ ./te State Selected a Plan Alabama 624 Alaska 53 Arizona 739 Arkansas 250 …
Note that I did not even have to look at the underlying HTML code at all for this code to work. If it hadn’t, I would have had to delve into that mess to find the specific problem, but, in this case, as in many others in my experience, HTML::TableExtract gave me just what I wanted. So long as the substrings I picked continue to match the content, my script will extract the desired columns even if some of the underlying HTML changes.
Both HTML::TokeParser::Simple (based on HTML::PullParser) and HTML::TableExtract (which subclasses HTML::Parser parse a stream rather than loading the entire document to memory and building a tree. This made them performant enough for whatever I was able to throw at them in the past.
With HTML::TokeParser::Simple, it is also easy to stop processing a file once you have extracted what you need. That helps when you are dealing with thousands of documents, each several megabytes in size where the interesting content is located towards the beginning. With HTML::TablExtract, performance can be improved by switching to less robust table identifiers such as depths and counts. However, in certain pathological conditions I seem to run into a lot, you may need to play with regexes to first extract the exact region of the HTML source that contains the content of interest.
In one case I had to process large sets of HTML files I had to process where each file was about 8 Mb. The interesting table occurred about 3/4 through the HTML source, and it was clearly separated from the rest of the page by <!-- interesting content here --> style comments. In this particular case, slurping each file, extracting the interesting bit, and passing the content to HTML::TableExtract helped. Throw a little Parallel::ForkManager into the mix, and a task that used to take a few hours went down to less than half an hour.
Sometimes, you just need to be able to extract the contents of the third span within the sixth paragraph of the first content div on the right. Especially if you need to extract multiple pieces of information depending on various parts of the document, creating a tree structure will make that task simpler. It may have a huge performance cost, however, depending on the size of the document. Building trees out of the smallest possible HTML fragments can help here.
Once you have the tree structure, you can address each element or sets of elements. XPath is a way of addressing those elements. HTML::TreeBuilder builds a tree representation of HTML documents. HTML::TreeBuilder::XPath adds the ability to locate nodes in that representation using XPath expressions. So, if I wanted to get the table of contents of the same document, I could have used something along the lines of:
use HTML::TreeBuilder::XPath;
use Text::Table;
my $doc = 'state-actions-to-implement-the-health-benefit.aspx';
my $tree = HTML::TreeBuilder::XPath->new;
my $toc_table = Text::Table->new('Entry', 'Link');
$tree->parse_file($doc);
my @toc = $tree->findnodes('//table[@id="bookmark"]/tbody/*/*/*//li/a');
for my $el ( @toc ) {
$toc_table->add(
$el->as_trimmed_text,
$el->attr('href'),
);
}
print $toc_table;Mojo::DOM is an excellent module that uses JQuery style selectors to address individual elements. It is extremely helpful when dealing with documents were HTML elements, classes, and ids were used in intelligent ways.
XML::Twig will also work for some HTML documents, but in general, using an XML parser to parse HTML documents found in the wild is perilious. On the other hand, if you do have well-formed documents, or HTML::Tidy can make them nice, XML::Twig is a joy to use. Unfortunately, it is depressingly too common to find documents pretending to be HTML, using a mish-mash of XML and HTML styles, and doing all sorts of things which browsers can accommodate, but XML parsers cannot.
And, if your purpose is just to clean some wild HTML document, use HTML::Tidy. It gives you an interface to the command line utility tidyp. For really convoluted HTML, it sometimes pays to pass through tidyp first before feeding it into one of the higher level modules.
Thanks to others who have built on HTML::Parser, I have never had to write a line of event handler code myself for real work. It is not that they are difficult to write. I do recommend you study the examples bundled with the distribution to see how the underlying machinery works. It is just that the modules others have built on top of and beyond HTML::Parser make life so much easier that I never had to worry much about going to the lowest possible level.
That’s a good thing.
Editor’s note: If you’re looking for tips on how to write more efficient, robust, and maintainable Perl code, you’ll want to check out Damien Conway’s “Modern Perl Best Practices” video.