

I’ve given a continuous delivery workshop a few times with ThoughtWorks Chief Scientist Martin Fowler, who tells an interesting story about continuous integration, from the first software project he ever saw. When Martin was a teenager, his father had a friend who was running a software project, and he gave Martin the nickel (or five pence) tour — a bunch of men, predominately on mainframe terminals, working in an old warehouse. Martin remarked that the thing that struck him the most was when the guide told him that all the developers were “currently integrating all their code.” They had finished coding six months prior, yet despite that they weren’t sure when they were going to be done “integrating.”
That revelation surprised Martin: in his mind, software development was a discreet, scientific, deterministic process, not at all represented by the vague comments of these developers. But the practice of as-late-as-possible integration was common back in an earlier era of software development. If you look at software engineering texts of the ’60s and ’70s, every project included an integration phase. This isn’t how we think of integration today, which happens at the granularity of services and applications. Rather, a common practice was to have developers code in isolation for weeks and months at a time, then integrate all their code together into a cohesive whole. And that phase was, not surprisingly, a painful part of most projects. Yet, that type of 60s and 70s workflow is still codified in some version control tools today, even though we have now determined that late integration is the opposite of how we should approach this problem.
In the early ’90s, a group of experienced, yet jaded, software developers gathered to rethink how to build software. Rather than develop yet another prescriptive process, they focused instead on the practices that had been universally beneficial based on their experience. They developed a methodology around taking known best practices and pushing them as far as possible — eXtreme Programming. One of practices they included concerned integration, observing that projects that were eager with integration had fewer problems than projects that delayed integration. One of the core practices of XP was continuous integration: everyone commits to the trunk at least once a day.
Tools quickly sprang into existence to facilitate continuous integration, creating an entire tool category. Consequently, we don’t think of continuous integration as a practice but rather a tool. But the practice still has tremendous value.
The practice of Continuous Integration
Let’s say you are developing on a local workstation. You make some changes to code, and you do a local build, ensuring that tests have yielded green locally. Once completed, you pull from version control to grab any changes that have occurred since the last time you synchronized yourself with version control. You then do another build, and make sure that your tests remain green.
Tests remain green.
Now, you push your changes to version control, which in turn triggers a build on the continuous integration server.
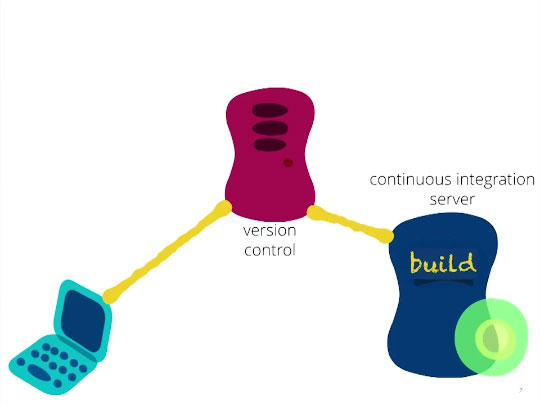
Push your changes.
The server now does a build incorporating your changes and all the other changes that everyone else has made in the interim, and once you have done that, you are said to have successfully continuously integrated all of your code.
Translated to modern terminology: everyone commit to the trunk at least once a day. This is still a highly valuable practice, yet many projects inadvertently throw it away.
Feature branching
Let’s say you have this common scenario, first highlighted on Martin Fowler’s Bliki.
You have ongoing development on a project on the mainline (which may be called master or trunk), and that mainline is where you are developing new features for your application. Additionally, a couple of new features exist that may or may not make it into the next release of the code base. You decide to use branching in your version control tool to model the problem, an engineering practice known as feature branching.
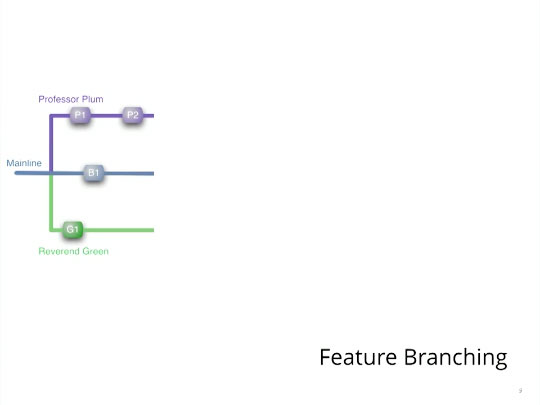
Feature branching
Professor Plum creates one branch in version control, Reverend Green creates another branch, and both begin work on their unique in-flight features. Both Professor Plum and Reverend Green, being experienced version control citizens, know that as they each make changes on their particular branch that they should periodically pull from trunk. They know this is key for incorporating any changes that have happened on trunk since the last time they synchronized themselves with it. Avoiding this makes the eventual merge more painful.
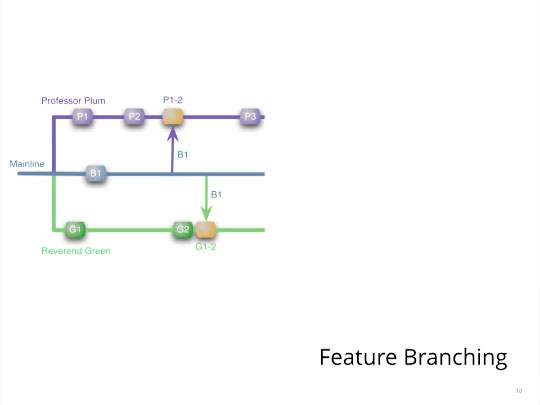
Pulling from trunk
A few days go by — or, perhaps a few weeks or maybe a couple months — and it is decided that Professor Plum’s feature is the one we want in the next version of our software. And so Professor Plum pushes to trunk… and performs a merge ambush on Reverend Green. Reverend Green didn’t do anything wrong, yet when he came into work on Monday morning, he did the usual svn up — and disaster! He’s looking at months worth of merge conflicts.
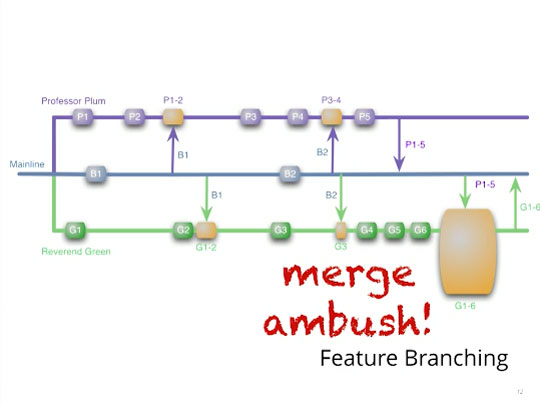
Merge ambush!
Yet Reverend Green’s merge conflict disaster isn’t the worst of it. Consider what happens if, on the very first day of their branch, Professor Plum started making profound changes to the Customer class. And, on the very first day of his branch, Rev. Green started making changes to the Customer in the opposite direction. We now have both guys coding in isolation from one another for a long period of time.
When the merge ambush occurs, Reverend Green has a terrible decision: “Do I go back and undo all of my work and reconcile my vision of the Customer class with Professor Plum?” Or, rather, (and this is what I’m terrified of), “Do I create a second version of the Customer class to avoid going back and rewriting all my code?”
The problem is that this project has opted for feature branching instead of continuous integration, and it’s a bad trade because feature branching also harms two other valuable engineering practices (which I’ll get to shortly). Teams must often trade off one practice against another, making it important to understand the implications of those decisions.
Notice that had the Professor and the Reverend utilized continuous integration, and committed to trunk as they made changes, the giant lump of pain would have never materialized — it is amortized over the length of the project.
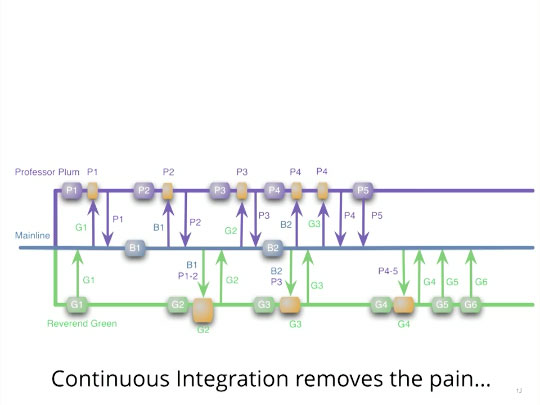
CI removes the pain.
Of course, in the continuous integration case here, we’ve lost the original motivation for branches in the first place — if we continuously integrate, both Plum and Green’s features will show up in partially completed states (and they will be irrevocably in the code base). However, you can see how the “eager versus late” principle is at work here. The reason the Professor and Reverend experienced that lump of pain was because they let that combinatorial explosion build up over time.
Best of both worlds?
What are some of the motivations for using feature branching? One is just what I illustrated above, the ability to cherry pick in-flight features. In this case, you generally don’t want incomplete features showing up on trunk. This is sometimes knows as the “untrusted contributors problem,” which can also sound like this: “I only want to see complete features on trunk,” or, “I want to see nothing at all — I don’t want to see half-done things.”
The translations of this from an engineering perspective: I want to be able to preserve the practices of continuous integration and still be able to achieve the two goals of avoiding incomplete features and being able to cherry pick selected features during a development process. There are a variety of engineering practices that allow this, one of the most common is feature toggles.
Feature toggles/feature flags
Feature toggles allow you to purposefully add a little bit of technical debt to your code to support practices like continuous integration.
The idea behind feature toggles (or feature flags) is to add configuration to your application to determine if a feature should be present. This could be as simple as a properties file that has Boolean values in it or as complex as a pile of XML. Within the user interface of your code, you add conditionals that guard the feature toggled code, either showing the new feature or not. Same for business logic: add a conditional around the feature toggle, creating two cases. Either the code is executed, or not executed, based on the condition of that toggle.
Let’s consider how this would work in the Professor Plum/Reverend Green scenario. If both Reverend Green and Professor Plum used feature toggles, they would both start a toggle around their new speculative, in-flight feature. In that case, the first time that they both notice that they have each touched the Customer file because they’re still integrating on the trunk, they realize right away that they’re going to have a merge conflict in the behavior that they’re exhibiting in that shared class. Catching the merge conflict eagerly allows the Professor and Reverend to realize and reconcile their changes as early as possible.
While Professor Plum is working, he has Reverend Green’s toggle turned off, so he never sees any of the effects of Reverend Green’s toggle. The exact same thing is true for the other side of the feature toggle. This preserves continuous integration; they’re still checking into trunk, but they don’t see each other’s features showing up in their code.
Applying feature toggles is a trade-off; specifically, it’s a temporary, technical debt that you add to your code base in order to be able to support engineering practices like continuous integration.
Togglz
In the Java world, nothing really exists unless there’s a framework for it. There’s a really nice framework in the Java world for doing feature toggles call Togglz. It includes a bunch of clever behaviors.
For example, a really common workflow in the Togglz world relates well to our friends Reverend Green and Professor Plum. When checking out code, Reverend Green only wants to see his feature toggled “on,” and everyone else’s toggled “off.” In Togglz, if you associate a feature toggle with a version control ID, you’ll notice that when you check out that toggle with that ID, it automatically toggles that feature “on” and automatically toggles all the other features “off.” So the logistics of working with a framework are made much easier because the Togglz framework is intelligent about the way it applies toggles.
Once a developer makes a feature decision, the feature toggles should be removed as soon as the feature decision is resolved. Here’s where the purposeful technical debt comes in. As soon as you’ve decided this feature is going to be in the code base or not, you need to strip out all the toggle code around it so that you’re left with just that feature you wanted (or the absence of that feature).
A word of caution: try to avoid having too many toggles live in a code base at one time. Simply put, they add complexity to your code base. A handful, or maybe double-digits (if that) is fine, but not many more than that.
The best feature toggles are relatively coarsely-grained. That is, you don’t want to be toggling single lines of code. You also, typically, do not want feature toggles that rely on other feature toggles, because that builds a lot of interdependencies and complexity around what are you building at any given time.
Runtime feature toggles versus build time feature toggles
There exists a distinction in this world between build time versus runtime feature toggles. “Runtime toggles” are those managed by tools like Togglz, and allow you to change the state of the toggle at runtime. This supports some interesting release scenarios like canary releasing.
It’s also easier to set up deployment pipelines if you have runtime feature toggles, because the test can look at the state of the toggle and decide, “Should I try to test this code or not?”
Some organizations prefer to use build time feature toggles, which are easiest to do if you’re using a language that supports conditional compiles, like a C# or within the C language family (Java does not support conditional compiles). In the case of build time feature toggles, you’ll find that you’re never actually deploying any code that’s not being run.
A Taxonomy of feature toggles
Mature teams that use feature toggles often have a taxonomy of feature toggles. An infrastructure team may, for example, have a set of feature toggles that control one piece of infrastructure versus another piece of infrastructure, whereas your engineering team may have a set of feature toggles that control showing a new menu option (or showing a new button). In these scenarios, the conditions aren’t meant to interact with one another, rather operate independently of one another. In this case, feature toggles aimed at different purposes can be applied within the exact same code base.
This taxonomy approach pretty much works on any platform or technology stack. As long as you have a conditional, like an if statement, and a way to read configuration, you can get feature toggles to work.
It’s possible, of course, to invest a lot more sophistication into getting feature toggles to work. For example, a common mechanism in most Java projects is a dependency injection mechanism like Spring, which is ideally suited for, well, dependency injection.
Feature toggles are heavily used in the industry. Many large companies, rather than dealing with the complexity of branches and figuring out exactly what constitutes a release, end up using feature toggles instead to simplify things. Granted, it takes greater discipline in the developers to become accustomed to writing everything within a toggle. Yet, once you’re accustomed to doing it, it becomes quite nature.
Many tools and frameworks exist that bring using toggles within reach for developers. Togglz, for one, bends over backwards to make the workflow part of adding feature toggles as painless as possible. It still allows you to isolate incomplete things and cherry pick features so that you only see them when you want to on trunk, and you can turn them off while they’re under development (or when you don’t want to see them as part of a particular build). Feature toggles are terrific for visual elements and interactive code. Another common scenario that tempts teams to use feature branching is a long running upgrade, which is more suited to the Branch by Abstraction pattern.
Branch by abstraction refactoring pattern
Feature toggles is not the only mechanism by which you can change or hide changes that are ongoing. Another technique that’s common in the continuous delivery world, and successfully avoids feature branching, is the concept of “branch by abstraction.” The term “branch” is a unfortunately overloaded in English; in this case, it means a logical branch in code, not a version control branch.
This is, ostensibly, a refactoring technique. Here’s the scenario. Let’s say that you have an existing application, and it’s using an old version of a library, and you really need to update that to the newer version of the library. But ongoing application development still needs to proceed, and changing out the library is probably much more than one iteration’s worth of work. The challenge: how do I change out this fundamental library while still allowing development to continue for the rest of application?
The branch by abstraction refactoring pattern suggests this: First, introduce an interface that has common semantics across the old library and the new library. Next, have the old library implement that interface. Next, gradually refactor the application code to rely on the interface rather than the library directly.
This adds a level of indirection. And it needs to be done in very tight iterative loops, because you’re going to affect other people’s working on the application because you’re rewiring their library access. Once the interface is in place you can now start making changes behind that interface and gradually implementing behavior in the new library, gradually de-implementing behavior out of the old library, until you’ve finally got all the behavior moved over to the new one. You can then ditch the old library.
You may want to leave the new interface in place, because it is going to make it easier to add a newer library at some point down in the future. And that interface may be valuable if you are trying to build what domain-driven design calls an anti-corruption layer between your application and the native libraries you use. If you capture the semantics of what you want that library for, then it doesn’t really matter what the implementation details are or what library you use; it won’t have an impact on your application if you change it. But if that interface was just there as a refactoring artifact, you can now throw it away, at which point you will have successfully moved everything over to the new library without affecting people’s ability to continue working on the code within the application.
Using branches
We’re not completely anti-branch, only in cases where it harms other practices. Branches have their use in the Continuous Delivery world. Release branches are one example. These are very short-lived branches with extremely short, one-way merges to isolate changes on behalf of an upcoming release. Those do not involve two-way merges and therefore prevent continuous integration. We use them simply to make the management of releases a bit easier.
Some version control tools still try to force developers to do their work in isolated branches, which is poisonous to continuous integration.
Other engineering practices damaged by feature branches
Feature branching ends up destroying three valuable engineering practices, and continuous integration is one of them, which trunk-based development restores. Let’s talk about the other two engineering practices that feature branches does serious damage to. The second is opportunistic refactoring. If you’re living on a feature branch, you are strongly discouraged from undertaking an opportunistic refactoring exercise.
Agile engineering says that if you encounter a broken window in your code base, you are supposed to fix it as aggressively as possible and get rid of those small flaws. But what if you’re living on a feature branch, and you notice, for example, that the Customer class name is misspelled? Agile engineering practices would encourage you to act immediately to correct it. However, if you’re on a feature branch, that kind of refactoring is the most painful because you incidentally touch dozens of source files. This in turn means that when it comes time to reconcile your feature back with the trunk, you’re going to make your merge conflict that much worse.
Opportunistic refactoring is a good behavior, one that is best to encourage in developers; however, if feature branching is present, you actively discourage that behavior. In effect, you’re punishing people for “good” behavior (opportunistic refactoring), thus ensuring that they never do it again.
Best practices only flourish in the right environment. Setting up road blocks against useful practices is not a good way to encourage those practices to happen on projects.
The last of the engineering practices damaged by feature branching is combining features. Let’s say you’re in the feature branching Professor Plum/Reverend Green world and the big boss comes to you and says, “OK, I want to see a version of the code base with neither Green nor Plum in it; then just Green; then just Plum; and then both of them together. Go.” You must perform three merges to make that happen (you have trunk, then trunk + Plum, trunk + Green, trunk + Plum + Green). And if the big boss wants that same thing next week, you have to go through that exact same three-merge exercise again.
Things are better in the feature toggle world. If you want to see how features interact with one another, you just turn “on” the features you’re interested in. There’s no merge headache because everything is pre-merged. Feature toggles encourage you to merge things as eagerly as possible, which is an example of “eager versus late” in action: by using feature toggles, you’re eagerly merging things at the point where the merge conflict will initially occur, not putting off the merge conflict as late as possible and then dealing with the amount of combinatorial pain that is built up.
And that truly gets at the heart of the key benefits of feature toggles — using them forces developers to work better, to practice eager integration versus late integration.
When choosing engineering practices for your team, make sure you understand not just the benefits but the tradeoffs as well. Don’t choose practices that provide a small conceptual benefit in one area at the expense of several important other practices.
Editor’s note: The post was transcribed and edited from the video course, “Engineering Practices for Continuous Delivery,” by Neal Ford. Start watching the course for free. Watch the section on Continuous Integration and Trunk-Based Development below.
The preceding is part of our ongoing exploration into learning how to solve programming problems.