"data engineer" entries

Why local state is a fundamental primitive in stream processing
What do you get if you cross a distributed database with a stream processing system?

One of the concepts that has proven the hardest to explain to people when I talk about Samza is the idea of fault-tolerant local state for stream processing. I think people are so used to the idea of keeping all their data in remote databases that any departure from that seems unusual.
So, I wanted to give a little bit more motivation as to why we think local state is a fundamental primitive in stream processing.
What is state and why do you need it?
An easy way to understand state in stream processing is to think about the kinds of operations you might do in SQL. Imagine running SQL queries against a real-time stream of data. If your SQL query contains only filtering and single-row transformations (a simple select and where clause, say), then it is stateless. That is, you can process a single row at a time without needing to remember anything in between rows. However, if your query involves aggregating many rows (a group by) or joining together data from multiple streams, then it must maintain some state in between rows. If you are grouping data by some field and counting, then the state you maintain would be the counts that have accumulated so far in the window you are processing. If you are joining two streams, the state would be the rows in each stream waiting to find a match in the other stream.
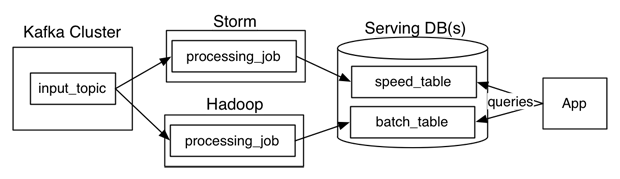
Questioning the Lambda Architecture
The Lambda Architecture has its merits, but alternatives are worth exploring.
Nathan Marz wrote a popular blog post describing an idea he called the Lambda Architecture (“How to beat the CAP theorem“). The Lambda Architecture is an approach to building stream processing applications on top of MapReduce and Storm or similar systems. This has proven to be a surprisingly popular idea, with a dedicated website and an upcoming book. Since I’ve been involved in building out the real-time data processing infrastructure at LinkedIn using Kafka and Samza, I often get asked about the Lambda Architecture. I thought I would describe my thoughts and experiences.
What is a Lambda Architecture and how do I become one?
The Lambda Architecture looks something like this:

A growing number of applications are being built with Spark
Many more companies want to highlight how they're using Apache Spark in production.
One of the trends we’re following closely at Strata is the emergence of vertical applications. As components for creating large-scale data infrastructures enter their early stages of maturation, companies are focusing on solving data problems in specific industries rather than building tools from scratch. Virtually all of these components are open source and have contributors across many companies. Organizations are also sharing best practices for building big data applications, through blog posts, white papers, and presentations at conferences like Strata.
These trends are particularly apparent in a set of technologies that originated from UC Berkeley’s AMPLab: the number of companies that are using (or plan to use) Spark in production1 has exploded over the last year. The surge in popularity of the Apache Spark ecosystem stems from the maturation of its individual open source components and the growing community of users. The tight integration of high-performance tools that address different problems and workloads, coupled with a simple programming interface (in Python, Java, Scala), make Spark one of the most popular projects in big data. The charts below show the amount of active development in Spark:

For the second year in a row, I’ve had the privilege of serving on the program committee for the Spark Summit. I’d like to highlight a few areas where Apache Spark is making inroads. I’ll focus on proposals2 from companies building applications on top of Spark.